Why Automated Feature Engineering Will Change the Way You Do Machine Learning
Automated feature engineering will save you time, build better predictive models, create meaningful features, and prevent data leakage.
By William Koehrsen, Feature Labs

There are few certainties in data science — libraries, tools, and algorithms constantly change as better methods are developed. However, one trend that is not going away is the move towards increased levels of automation.
Recent years have seen progress in automating model selection and hyperparameter tuning, but the most important aspect of the machine learning pipeline, feature engineering, has largely been neglected. The most capable entry in this critical field is Featuretools, an open-source Python library. In this article, we’ll use this library to see how automated feature engineering will change the way you do machine learning for the better.

Featuretools is an open-source Python library for automated feature engineering.
Each project highlights some of the benefits of automated feature engineering:
- Loan Repayment Prediction: automated feature engineering can reduce machine learning development time by 10x compared to manual feature engineering while delivering better modeling performance. (Notebooks)
- Retail Spending Prediction: automated feature engineering creates meaningful features and prevents data leakage by internally handling time-series filters, enabling successful model deployment. (Notebooks)
Feel free to dig into the code and try out Featuretools! (Full disclosure: I work for Feature Labs, the company developing the library. These projects were completed with the free, open-source version of Featuretools).
Feature Engineering: Manual vs. Automated
Feature engineering is the process of taking a dataset and constructing explanatory variables — features — that can be used to train a machine learning model for a prediction problem. Often, data is spread across multiple tables and must be gathered into a single table with rows containing the observations and features in the columns.
The traditional approach to feature engineering is to build features one at a time using domain knowledge, a tedious, time-consuming, and error-prone process known as manual feature engineering. The code for manual feature engineering is problem-dependent and must be re-written for each new dataset.
Automated feature engineering improves upon this standard workflow by automatically extracting useful and meaningful features from a set of related data tables with a framework that can be applied to any problem. It not only cuts down on the time spent feature engineering, but creates interpretable features and prevents data leakage by filtering time-dependent data.
Automated feature engineering is more efficient and repeatable than manual feature engineering allowing you to build better predictive models faster.
Loan Repayment: Build Better Models Faster
The primary difficulty facing a data scientist approaching the Home Credit Loan problem (a machine learning competition currently running on Kagglewhere the objective is to predict if a loan will be repaid by a client) is the size and spread of the data. Take a look at the complete dataset and you are confronted with 58 million rows of data spread across seven tables. Machine learning requires a single table for training, so feature engineering means consolidating all the information about each client in one table.
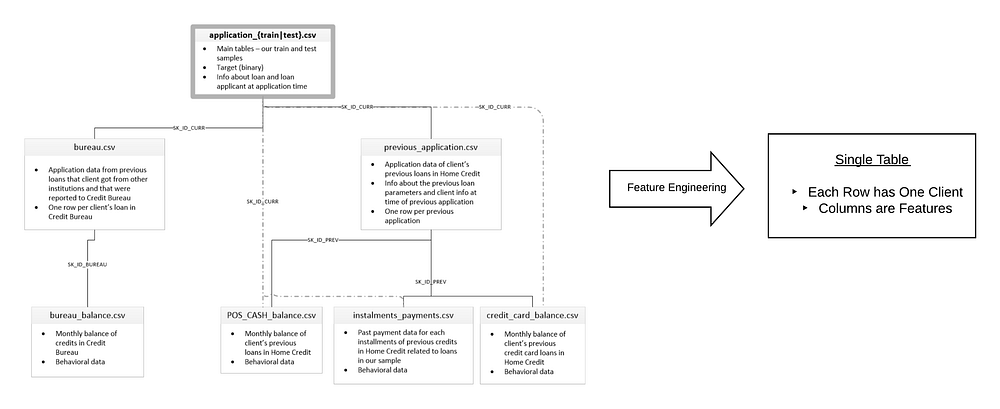
Feature engineering requires capturing all information from a set of related tables into one table.
The final manual engineered features performed quite well, achieving a 65% improvement over the baseline features (relative to the top leaderboard score), indicating the importance of proper feature engineering.
However, inefficient does not even begin to describe this process. For manual feature engineering, I ended up spending over 15 minutes per feature because I used the traditional approach of making a single feature at a time.

The Manual Feature Engineering process.
- Problem-specific: all of the code I wrote over many hours cannot be applied to any other problem
- Error-prone: each line of code is another opportunity to make a mistake
Furthermore, the final manual engineered features are limited both by human creativity and patience: there are only so many features we can think to build and only so much time we have to make them.
The promise of automated feature engineering is to surpass these limitations by taking a set of related tables and automatically building hundreds of useful features using code that can be applied across all problems.
From Manual to Automated Feature Engineering
As implemented in Featuretools, automated feature engineering allows even a domain novice such as myself to create thousands of relevant features from a set of related data tables. All we need to know is the basic structure of our tables and the relationships between them which we track in a single data structure called an entity set. Once we have an entity set, using a method called Deep Feature Synthesis (DFS), we’re able to build thousands of features in one function call.
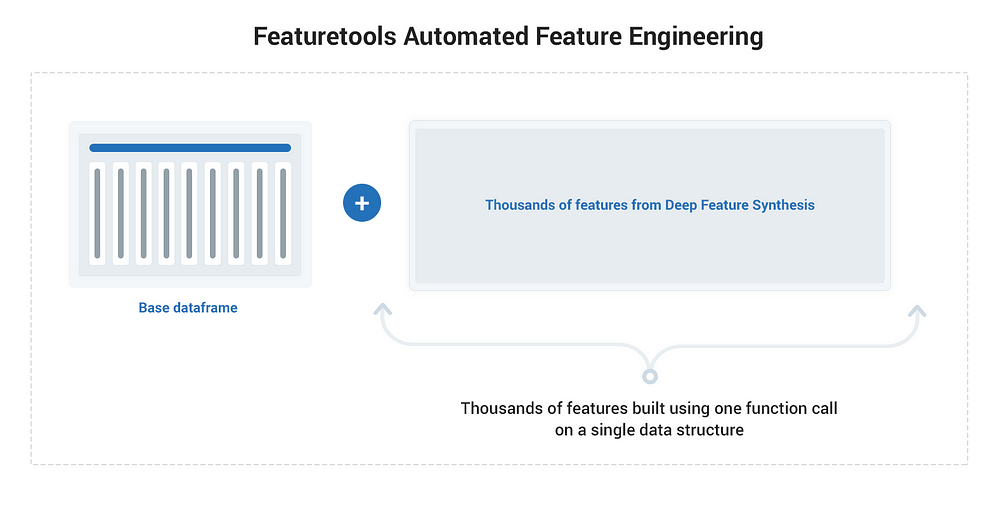
The Automated Feature Engineering process using Featuretools.
Feature primitives include many operations we already would do manually by hand, but with Featuretools, instead of re-writing the code to apply these operations on different datasets, we can use the same exact syntax across any relational database. Moreover, the power of DFS comes when we stack primitives on each other to create deep features. (For more on DFS, take a look at this blog post by one of the inventors of the technique.)
Deep Feature Synthesis is flexible — allowing it to be applied to any data science problem — and powerful — revealing insights in our data by creating deep features.
I’ll spare you the few lines of code needed for the set-up, but the action of DFS happens in a single line. Here we make thousands of features for each client using all 7 tables in our dataset (ft is the imported featuretools library):
# Deep feature synthesis
feature_matrix, features = ft.dfs(entityset=es,
target_entity='clients',
agg_primitives = agg_primitives,
trans_primitives = trans_primitives)
Below are some of the 1820 features we automatically get from Featuretools:
- The maximum total amount paid on previous loans by a client. This is created using a
MAXand aSUMprimitive across 3 tables. - The percentile ranking of a client in terms of average previous credit card debt. This uses a
PERCENTILEandMEANprimitive across 2 tables. - Whether or not a client turned in two documents during the application process. This uses a
ANDtransform primitive and 1 table.
Each of these features is built using simple aggregations and hence is human-interpretable. Featuretools created many of the same features I did manually, but also thousands I never would have conceived — or had the time to implement. Not every single feature will be relevant to the problem, and some of the features are highly correlated, nonetheless, having too many features is a better problem than having too few!
After a little feature selection and model optimization, these features did slightly better in a predictive model compared to the manual features with an overall development time of 1 hour, a 10x reduction compared to the manual process. Featuretools is much faster both because it requires less domain knowledge and because there are considerably fewer lines of code to write.
I’ll admit that there is a slight time cost to learning Featuretools but it’s an investment that will pay off. After taking an hour or so to learn Featuretools, you can apply it to any machine learning problem.
The following graphs sum up my experience for the loan repayment problem:
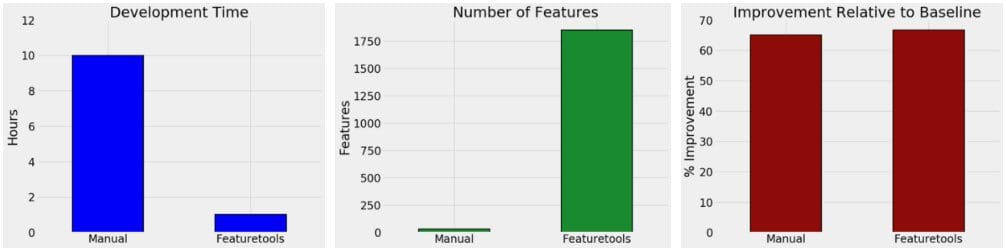
Comparison between automated and manual feature engineering on time, number of features, and performance.
- Development time: accounts for everything required to make the final feature engineering code: 10 hours manual vs 1 hour automated
- Number of features produced by the method: 30 features manual vs 1820 automated
- Improvement relative to baseline is the % gain over the baseline compared to the top public leaderboard score using a model trained on the features: 65% manual vs 66% automated
My takeaway is that automated feature engineering will not replace the data scientist, but rather by significantly increasing efficiency, it will free her to spend more time on other aspects of the machine learning pipeline.
Furthermore, the Featuretools code I wrote for this first project could be applied to any dataset while the manual engineering code would have to be thrown away and entirely rewritten for the next dataset!
Retail Spending: Build Meaningful Features and Prevent Data Leakage
For the second dataset, a record of online time-stamped customer transactions, the prediction problem is to classify customers into two segments, those who will spend more than $500 in the next month and those who won’t. However, instead of using a single month for all the labels, each customer is a label multiple times. We can use their spending in May as a label, then in June, and so on.
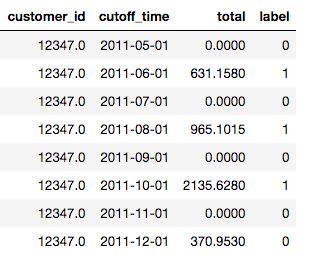
Each customer is used as a training example multiple times
Fortunately, ensuring that our data is valid in a time-series problem is straightforward in Featuretools. In the Deep Feature Synthesis function we pass in a dataframe like that shown above, where the cutoff time represents the point past which we can’t use any data for the label, and Featuretools automatically takes the time into account when building features.
The features for a customer in a given month are built using data filtered to before the month. Notice that the call to create our set of features is the same as that for the loan repayment problem with the addition of cutoff_time.
# Deep feature synthesis
feature_matrix, features = ft.dfs(entityset=es,
target_entity='customers',
agg_primitives = agg_primitives,
trans_primitives = trans_primitives,
cutoff_time = cutoff_times)
The result of running Deep Feature Synthesis is a table of features, one for each customer for each month. We can use these features to train a model with our labels and then make predictions for any month. Moreover, we can rest assured that the features in our model do not use future information, which would result in an unfair advantage and yield misleading training scores.
With the automated features, I was able to build a machine learning model that achieved 0.90 ROC AUC compared to an informed baseline (guessing the same level of spending as the previous month) of 0.69 when predicting customer spending categories for one month.
In addition to delivering impressive predictive performance, the Featuretools implementation gave me something equally valuable: interpretable features. Take a look at the 15 most important features from a random forest model:
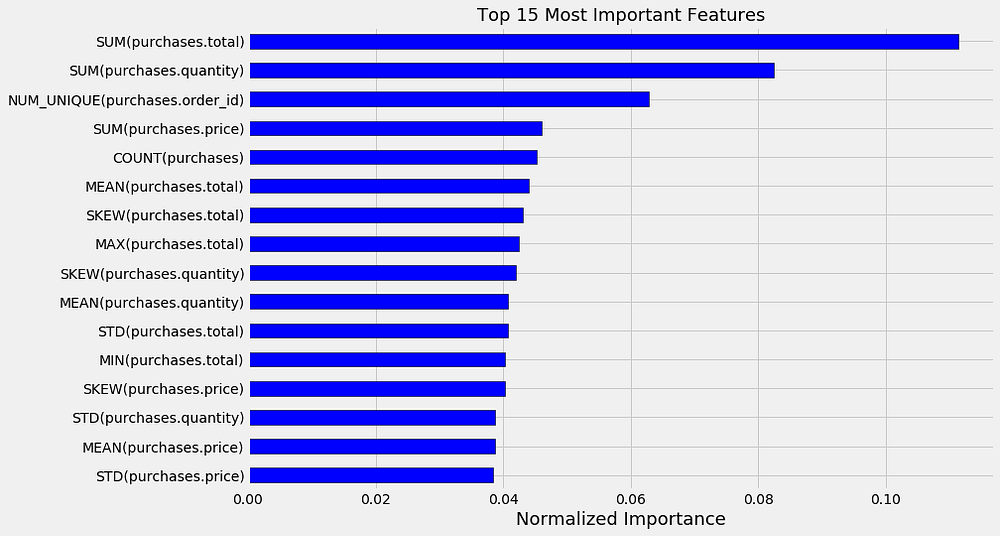
15 most important Featuretools features from a random forest model.
SUM(purchases.total), and the number of purchases, SUM(purchases.quantity). These are features that we could have built by hand, but then we would have to worry about leaking data and creating a model that does much better in development than in deployment.
If the tool already exists for creating meaningful features without any need to worry about the validity of our features, then why do the implementation by hand? Furthermore, the automated features are completely clear in the context of the problem and can inform our real-world reasoning.
Automated feature engineering identified the most important signals, achieving the primary goal of data science: reveal insights hidden in mountains of data.
Even after spending significantly more time on manual feature engineering than I did with Featuretools, I was not able to develop a set of features with close to the same performance. The graph below shows the ROC curves for classifying one month of future customer sales using a model trained on the two datasets. A curve to the left and top indicates better predictions:
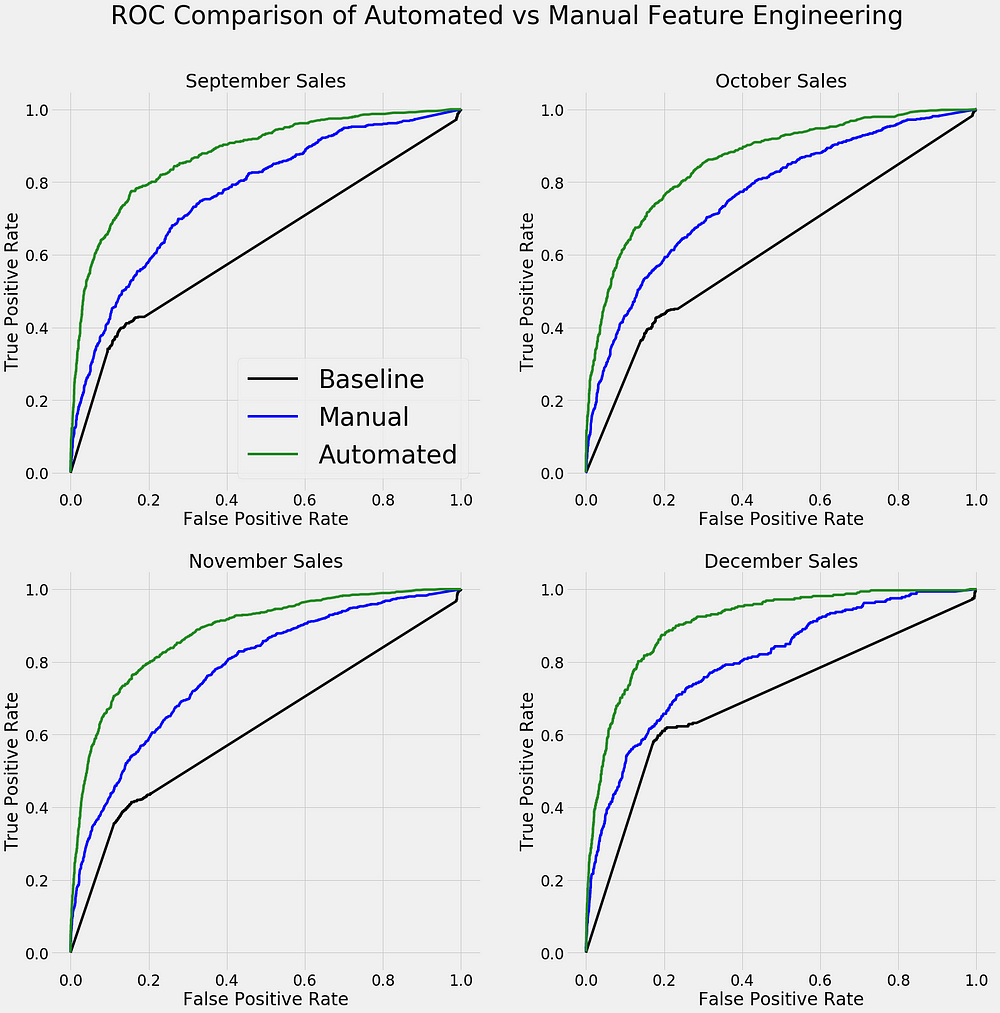
ROC curves comparing automated and manual feature engineering results. A curve to the left and top indicates better performance.
We use automatic safety systems in our day-to-day life and automated feature engineering in Featuretools is the secure method to build meaningful machine learning features in a time-series problem while delivering superior predictive performance.
Conclusions
I came away from these projects convinced that automated feature engineering should be an integral part of the machine learning workflow. The technology is not perfect yet still delivers significant gains in efficiency.
The main conclusions are that automated feature engineering:
- Reduced implementation time by up to 10x
- Achieved modeling performance at the same level or better
- Delivered interpretable features with real-world significance
- Prevented improper data usage that would invalidate a model
- Fit into existing workflows and machine learning models
“Work smarter, not harder” may be a cliche, but sometimes there is truth to platitudes: if there is a way to do the same job with the same performance for a smaller time investment, then clearly it’s a method worth learning.
Featuretools will always be free to use and open-source (contributions are welcome), and there are several examples — here’s an article I’ve written — to get you started in 10 minutes. Your job as a data scientist is safe, but it can be made significantly easier with automated feature engineering.
If building meaningful, high-performance predictive models is something you care about, then get in touch with us at Feature Labs. While this project was completed with the open-source Featuretools, the commercial product offers additional tools and support for creating machine learning solutions.
Bio: Will Koehrsen is a Data Scientist at Feature Labs, and a Data Science Communicator and Advocate.
Original. Reposted with permission.
Related: