 6 Steps To Write Any Machine Learning Algorithm From Scratch: Perceptron Case Study
6 Steps To Write Any Machine Learning Algorithm From Scratch: Perceptron Case Study
 6 Steps To Write Any Machine Learning Algorithm From Scratch: Perceptron Case Study
6 Steps To Write Any Machine Learning Algorithm From Scratch: Perceptron Case StudyWriting a machine learning algorithm from scratch is an extremely rewarding learning experience. We highlight 6 steps in this process.
By John Sullivan, DataOptimal
Writing an algorithm from scratch is a rewarding experience, providing you with that "ah ha!" moment where it finally clicks, and you understand what's really going on under the hood.
Am I saying that even if you've implemented the algorithm before with scikit-learn, it's going to be easy to write from scratch? Absolutely not.
Some algorithms are just more complicated than others, so start with something simple, such as the single layer Perceptron.
I'll walk you through a 6-step process to write algorithms from scratch, using the Perceptron as a case-study. This methodology can easily be translated to other machine learning algorithms.
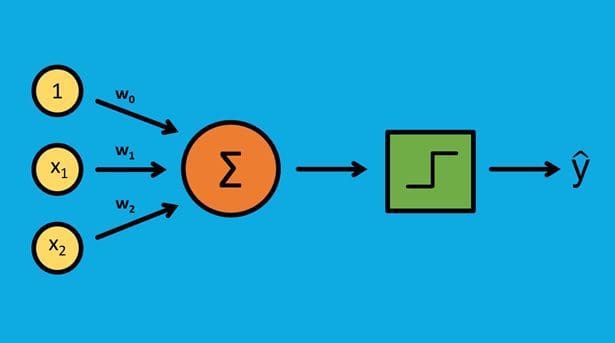
- Get a Basic Understanding of the Algorithm
This goes back to what I originally stated. If you don’t understand the basics, don’t tackle an algorithm from scratch. At the very least, you should be able to answer the following questions:
- What is it?
- What is it typically used for?
- When CAN’T I use this?
For the Perceptron, let’s go ahead and answer these questions:
- The single layer Perceptron is the most basic neural network. It’s typically used for binary classification problems (1 or 0, “yes” or “no”).
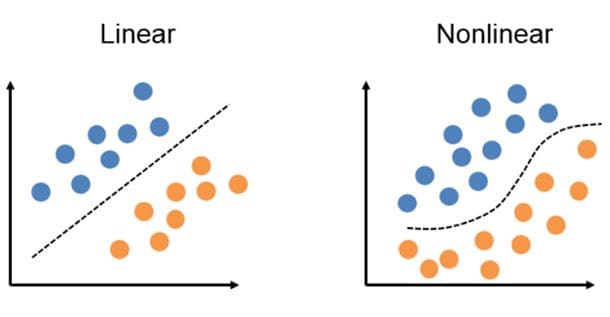
- It’s a linear classifier, so it can only really be used when there’s a linear decision boundary. Some simple uses might be sentiment analysis (positive or negative response) or loan default prediction (“will default”, “will not default”). For both cases, the decision boundary would need to be linear.
- If the decision boundary is non-linear, you really can’t use the Perceptron. For those problems, you’ll need to use something different.
- Find Some Different Learning Sources
After you have a basic understanding of the model, it’s time to start doing your research. I recommend using numerous sources. Some people learn better with textbooks, some people learn
better with video. Personally, I like to bounce around and use various types of sources. For the mathematical details, textbooks do a great job, but for more practical examples, I prefer blog posts and YouTube videos.
For the perceptron, here's some great resources:
- Textbooks:
- The Elements of Statistical Learning, Section 4.5.1
- Understanding Machine Learning: From Theory To Algorithms, Section 21.4
- Blogs:
- Jason Brownlee’s article on his Machine Learning Mastery blog, How To Implement The Perceptron Algorithm From Scratch In Python
- Sebastian Raschka’s blog post, Single-Layer Neural Networks and Gradient Descent
- Videos:

- Break the algorithm into chunks
Now that we’ve gathered our sources, it’s time to start learning. Start by grabbing some paper and a pencil. Rather than read a chapter or blog post all the way through, start by skimming for section headings, and other important info. Write down bullet points, and try to outline the algorithm.
After going through the sources, I’ve broken down the Perceptron algorithm into the following chunks:
- Initialize the weights
- Multiply weights by inputs and sum them up
- Compare the result against the threshold to compute the output (1 or 0)
- Update the weights
- Repeat
Breaking the algorithm up into chunks like this makes it easier to learn. Basically I’ve outlined the algorithm with pseudocode, and now I can go back and fill in the fine details. Here’s a picture of my notes for the second step, which is the dot product of the weights and inputs:

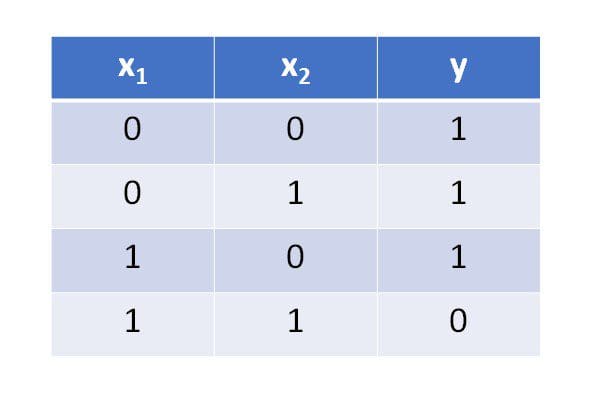
- Start with a simple example
After I’ve put together my notes on the algorithm, It’s time to start implementing it in code. Before I dive in to a complicated problem, I like to start with a simple example. For the Perceptron, a NAND gate is a perfect simple data set. If both inputs are true (1) then the output is false (0), otherwise, the output is true. Here’s an example of what the data set looks like:
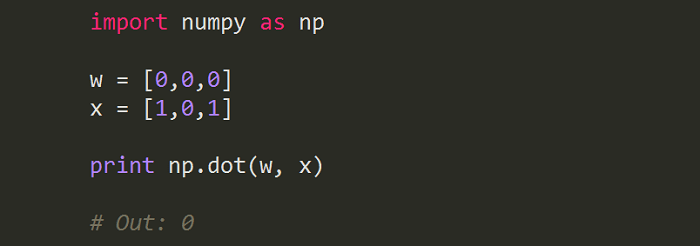
Now that I have a simple data set, I’ll start implementing the algorithm that I outlined in Step 3. It’s good practice to write the algorithm in chunks and test it, rather than trying to write it all in one sitting. This makes it easier to debug when you’re first starting out. Of course at the end you can go back and clean it up to make it look a little nicer.
Here’s an example of the Python code for the dot product part of the algorithm that I outlined in Step 3:
- Validate with a trusted implementation
Now that we’ve written up our code and tested it against a small data set, it’s time to scale things up to a larger dataset. To make sure that our code is working correctly on this more complicated dataset, it’s good to test it against a trusted implementation. For the Perceptron we can use the implementation from sci-kit learn.

To test my code I’m going to look at the weights. If I’ve implemented the algorithm correctly, my weights should match up with those of the sci-kit learn Perceptron.
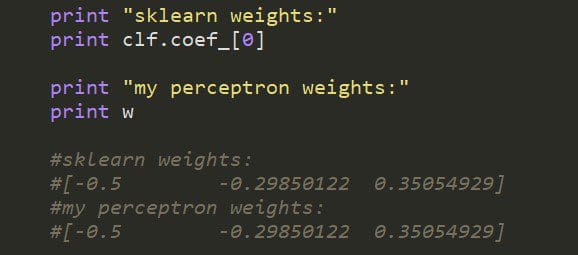
At first, I didn’t get the same weights, and this is because I had to tweak the default settings in the scikit-learn Perceptron. I wasn’t implementing a new random state every time, just a fixed seed, so I had to turn this off. The same goes for shuffling, I also needed to turn that off. To match my learning rate, I changed eta0 to 0.1. Finally, I turned off the fit_intercept option. I included a dummy column of 1’s in my feature dataset, so I was already automatically fitting the intercept (aka bias term).
This brings up another important point. When you validate against an existing implementation of a model, you need to be very aware of the inputs to the model. You should never blindly use a model, always question your assumptions, and exactly what each input means.
- Write up your process
This last step in the process is probably the most important. You’ve just gone through all the work of learning, taking notes, writing the algorithm from scratch, and comparing it with a trusted implementation. Don’t let all that good work go to waste! Writing up the process is important for two reasons:
- You’ll gain an even deeper understanding because you’re teaching others what you just learned.
- You can showcase it to potential employers. It’s one thing to show that you can implement an algorithm from a machine learning library, but it’s even more impressive if you can implement it yourself from scratch.
A great way to showcase your work is with a GitHub Pages portfolio.
Conclusion
Writing an algorithm from scratch can be a very rewarding experience. It’s a great way to gain a deeper understanding of the model, while building an impressive portfolio project at the same time.
Remember to take it slow, and start with something simple. Most importantly, make sure to document and share your work.
Bio: John Sullivan is the founder of the data science learning blog, DataOptimal. You can follow him on Twitter @DataOptimal.
Related:
- Top /r/MachineLearning posts, August 2018: Everybody Dance Now; Stanford class Machine Learning cheat sheets; Academic Torrents for sharing enormous datasets
- Key Takeaways from KDD 2018: a Deconfounder, Machine Learning at Pinterest, Knowledge Graph
- Everything You Need to Know About AutoML and Neural Architecture Search