Data Capture – the Deep Learning Way
An overview of how an information extraction pipeline built from scratch on top of deep learning inspired by computer vision can shakeup the established field of OCR and data capture.
By Petr Baudis, Rossum.ai.
Information extraction from text is one of the fairly popular machine learning research areas, often embodied in Named Entity Recognition, Knowledge Base Completion or similar tasks. But in business, many information extraction problems do not fit well into the academic taxonomy - take the problem of capturing data from business, layout-heavy documents like invoices. NER-like approaches are a poor fit because there isn’t rich text context and layout plays an important role in encoding the information. At the same time, the layouts can be so variable that simple template matching doesn’t cut it at all.
However, capturing data is a huge business problem - just for invoices, one billion per day is exchanged worldwide [*]. Yet only a tiny fraction of the problem is solved by traditional data capture software, leaving armies of people to do the mindless paper-pushing drudgery - meanwhile we are making strides in self-driving technology and steadily approaching human-level machine translation. It was genuinely surprising for us at Rossum when we realized this absurd gap.
Perhaps our main ambition in this post is to inspire the reader in how it’s possible to make a difference in an entrenched field using deep learning. Everyone is solving (and applying) the standard academic tasks - the key for us was to ignore the shackles of their standard formulations and rephrase the problem from the first principles of deep learning.
Traditional Data Capture
The traditional approach to data capture from formatted documents is to first generate a text layer from the document using an OCR step, then recognize data fields using either image-based templates or text-based rules. But this approach breaks down badly once document variability becomes a factor - consider invoices as an extreme example.

We’d need a lot of rules and templates. Text-based rules give an initial illusion of flexibility - just bind a data field type to the obvious label phrasings. Well, try to figure out good flexible rules just for invoiced amounts, as shown in the previous picture - go ahead, we will wait. Simultaneously, we must avoid false positives - see the picture below. This is why in the end, users restrict even text-based rules to each respective supplier.
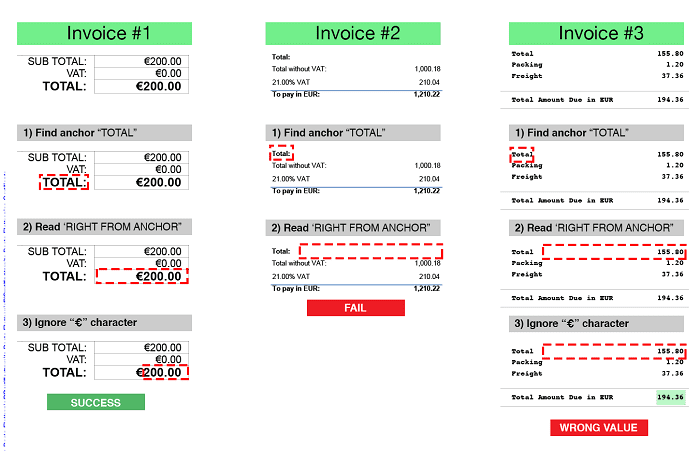
The next problem with text-based rules is that they are really sensitive to OCR quality. One matter is whether OCR even detects that text block at all, because invoices aren’t nice paragraphs of text. Next, the risk skyrockets for a single noisy character breaking down the whole rule extraction. Moreover, context is essential for OCR, and there is little in the invoice microparagraphs; what remains is unlike the books and newspapers that typical OCR has been mainly trained on.
Traditional OCR:

Humans don’t need templates
In the last 5 years, thinking about how do humans find information to teach computers the same approach suddenly isn’t a crazy notion - instead, it became a proven strategy that works for automating routine tasks thanks to neural networks, deep learning and big datasets. This is the key enabler that allowed us to completely rethink the approach to data capture.
While traditional OCR software takes a sequential approach to reading a page (all text, from one corner to the other), this breaks down when we move to business documents. Humans would be collecting specific bits of information, skimming the invoice, darting their eyes back and forth and looking for key points. Reading the document precisely letter by letter is superfluous, and humans can go long way based just on a visual structure of the document.
Rethinking with Deep Learning

- SKIM-READING
When seeing a document page for the first time, the initial take-in represents a sudden rush of very rough information. We notice the basic layout and the general structure of letters at various places in the page - where the amounts and dates are, sizes of text, numbers in the page corners, etc. Next, to clear up ambiguities, we glance ever so briefly at the text labels next to the values to get the rough idea of e.g. which amount is which. In another word:

To skim-read in machine, we use a novel kind of spatial OCR. Instead of converting the page to a stream of text, we determine the letter present on each spot of a page, building a space map of where every letter is - we can still recognize words by looking at places adjacent to each other, yet layout is the primary subject of representation rather than an afterthought.
- DATA LOCALIZATION
By tracking eye focus of humans reading structured documents, researchers at the Chia-Yi University investigated the learning process when reading a textbook text accompanied by diagrams ([https://www.sciencedirect.com/science/article/pii/S0360131514001365] the left figure), while UX designers at TheLadders looked into how humans read CVs ([https://www.jobisjob.co.uk/blog/2014/05/eye-tracking-your-cv-is-evaluated-in-only-6-seconds/]; the right figure).


This shows the very non-linear way that humans read structured documents, darting their eyes and focusing only on specific spots which they intuit would contain the key information.
We built Rossum's technology around the same principle - the neural networks look at a document page as a whole and use the rough “skim-reading” view to immediately focus just label candidates. We got inspired by neural network architectures originally designed for scene understanding tasks in computer vision - a page is our scene, an approach completely unrelated to traditional information extraction.
- Precise reading
When we identify multiple focal points on the page, it is time to precisely read and evaluate the information. For that, we fine-tune the location, carefully transcribe the final text, and assign it a confidence.
If you were to draw a box around a piece of information, your eyes would at first glance at the middle of that field, then work out exactly where its boundaries are so that you can determine the precise boundary. It should come as no surprise anymore that we take the same approach, with a dedicated neural network to determine these boundaries from the focal points.
Only at this point we come to the classic OCR task of precisely transcribing linear text from the picture! But with the precise area of the field already determined, we have a much easier time than traditional OCR systems - we shun the detection problem and get the OCR context from the label type.
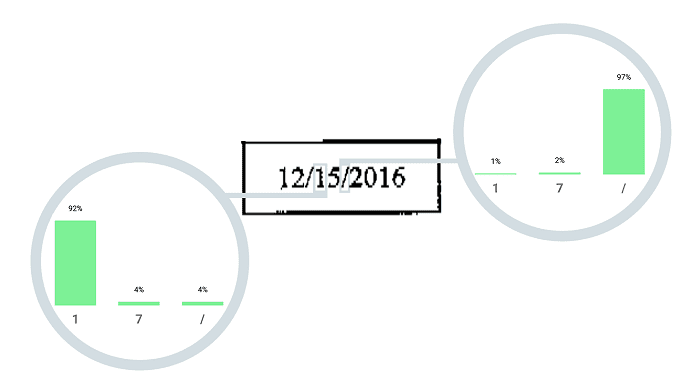
Fig.: Probability of decoding of visually very similar characters.
Does it work?
With traditional OCR, it is feasible to implement only the most prolific suppliers. In all the cases we have seen, that may be between 25% and 60% of invoice volume - but it always falls very short from a complete solution. If we assume 95% field accuracy for the recognized invoices, we are still at around 55% total fields extracted. Moreover, the suppliers need constant attention as they change and their invoices change as well.
With the neural pipeline outlined above (known as Rossum Elis), the baseline accuracy is 80% to 90% fields across the whole volume. When the user’s invoices settle in the training set, we routinely extract over 95% of fields. The difference is in the “10x better” territory.
Of course, there are other machine learning based products out there - infrrd.ai and smacc.io are our favorites, since they also have public demo uploads on their website. Even Abbyy, a traditional OCR vendor, is trying to break in with its Flexicapture for Invoices. But as far as we know, all these technologies are based on more traditional data capture approaches - which might spell trouble for OCR invoices and slow to adapt to new layouts. An independent benchmark to confirm or disprove this is yet to emerge.
Original. Reposted with permission.
Bio: Petr Baudis is a co-founder and the Chief AI Architect of Rossum, a company building deep learning technology for document understanding with the mission to eliminate manual data entry from the world. Petr has extensive experience with applying neural networks to a variety of natural language processing and computer vision tasks. He led the team that built the NLP question answering system YodaQA and before that authored one of AlphaGo predecessors, the Pachi computer Go player. He worked with Linus Torvalds as one of the earliest authors of Git.
Related: