Introducing VisualData: A Search Engine for Computer Vision Datasets
Instead of building your own dataset, there already exists a rich collection of computer vision datasets contributed by academic researchers, hobbyists and companies.
By Jie Feng, Humanize AI
Computer vision is without doubt going to change almost every aspect of how a machine interacts with our environment and us in the near future. It is still a young field (originated from 1960s) but the technology starts to work at the first time in history with recent advances in machine learning. Applications like self-driving cars, robotics, VR/AR have motivated people to enter the field and apply the technology to much broader areas. It has become one of the most active subfields of Artificial Intelligence.
Crazy ideas around computer vision happen everyday for new research, side projects or business use cases. To work with computer vision, you need three things: data, algorithm and computation. Giant tech companies like Google and Amazon has made heavy computation possible for everyone with their cloud platform offering. The research community (e.g. arXiv) and open source community (e.g. Github) bring us better algorithms on paper and easy-to-use code in practice. It has never been a better time to study this complex subject which used to require Ph.D level experience. But there is one problem left — Data. More specifically, visual data which comes with high quality annotations. Building a good dataset requires a lot of thinking in terms of size, content balance, visual variations to help the trained model generalize well to unseen cases. Labeling a large scale dataset can be very expensive and slow, making it still a barrier for individuals or small companies with limited budget to experiment with new ideas.
The answer to the problem is open datasets. Instead of building your own dataset, there already exists a rich collection of computer vision datasets contributed by academic researchers, hobbyists and companies. These datasets include diverse topics from recognizing objects to reconstructing a 3D room, from finding a person in a video to identifying a shirt in a photo. They generally come with good quality labels annotated manually. In recent years, new datasets even include pretrained deep learning models that you can directly try out without training one by yourself. However, to discover these datasets is not that easy. They are usually hosted separately on the creator’s website and it’s hard to compare different ones to choose the best one for a specific task. For newcomers, it’s also hard to come up with the right keywords to put in Google.
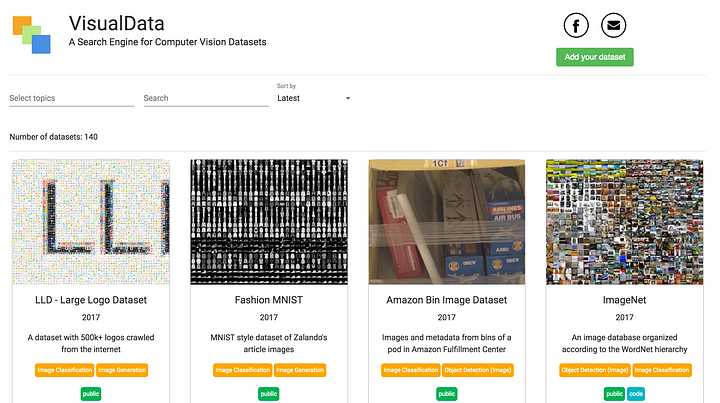
That’s why we built VisualData, a search engine for computer vision datasets. Each dataset is manually curated at this point, tagged with relevant topics for filtering and you can type keywords in the search bar which will be matched to the title and description of the dataset to easily find the best one to use. They are sorted according to published date so the most recent addition gets surfaced. The detail view shows the full description of a dataset and links to open source code/models. Other useful information will be added incrementally in the future, e.g. articles/tutorials about the dataset, difficulty to work with etc. Some example screenshots of the site are illustrated below.

From left to right: filtering with (multiple) topics, search with keywords, dataset detail.
This is a site I wish existed during my Ph.D. Now, I hope it could help people interested in computer vision easily explore existing data to do their experiments faster. It is still in an early form, and there are some cool ideas to be added for future versions. We hope to hear how it can be more useful to you.
P.S. Like this Facebook page or follow us on Twitter to get updates on new dataset or code release and post feedback and feature suggestion.
Bio: Jie Feng holds a PhD in Computer Science from Columbia, and is the creator of VisualData.
Original. Reposted with permission.
Related:
- Announcing Microsoft Research Open Data, a cloud hosted platform for sharing datasets
- DIY Deep Learning Projects
- Basic Image Data Analysis Using Numpy and OpenCV – Part 1