Unfolding Naive Bayes From Scratch
Whether you are a beginner in Machine Learning or you have been trying hard to understand the Super Natural Machine Learning Algorithms and you still feel that the dots do not connect somehow, this post is definitely for you!
By Aisha Javed.

My Sole Purpose of Writing this Blog Post
I have tried to keep things simple and in plain-English. The sole purpose is to deeply and clearly understand the working of a well know Text Classification ML Algorithm (Naïve Bayes) without being trapped in the gibberish mathematical jargon that is often used in the explanation of ML Algorithms which obviously lands you nowhere except for being relying on ML API’s with almost zero understanding of how the things actually work!
Who is the Target Audience?
ML beginners who are seeking in depth yet understandable explanation of ML Algorithms from scratch
Outcome of this Tutorial
A complete clear picture of the Naïve Bayes ML Algorithm with all its mysterious mathematics demystified plus a concrete step taken forward in your ML voyage! Cheers ????
Defining The Roadmap….. ????
Milestone # 1 : A Quick Short Intro to The Naïve Bayes Algorithm
Milestone # 2 : Training Phase of The Naïve Bayes Model
The Grand Grand Grand Milestone # 3 : The Testing Phase —Where Prediction Comes into the Play!
Milestone # 4 : Digging Deeper into the Mathematics of Probability
Milestone # 5 : Avoiding the Common Pitfall of The Underflow Error!
Milestone # 6 : Concluding Notes….
A Quick Short Intro to The Naïve Bayes Algorithm
Naive Bayes is one of the most common ML algorithms that is often used for the purpose of text classification. If you have just stepped into ML, it is one of the easiest classification algorithms to start with. Naive Bayes is a probabilistic classification algorithm as it uses probability to make predictions for the purpose of classification.
Milestone # 1 Achieved ????
Training Phase of The Naïve Bayes Model
Let’s say, there is a restaurant review, “Very good food and service!!!”, and you want to predict that whether this given review implies a positive or a negative sentiment. To do this, we will first need to train a model ( that essentially means to determine counts of words of each category) on a relevant labelled training data set and then this model itself will be able to automatically classify such reviews into one of the given sentiments against which it was trained for. Assume that you are given a training dataset which looks like something below (a review and it’s corresponding sentiment):
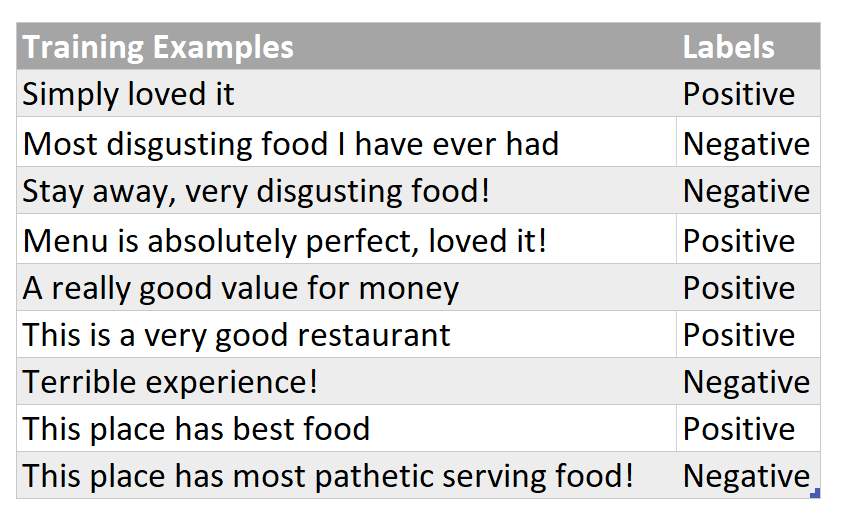
A Quick Side Note : Naive Bayes Classifier is a Supervised Machine Learning Algorithm
So how do we begin?
Step # 1 : Data Preprocessing
As part of the preprocessing phase (which is not covered in a detail in this post), all words in the training corpus/ training dataset are converted to lowercase and everything apart from letters like punctuation is excluded from the training examples.
A Quick Side Note : A common pitfall is not preprocessing the test data in the same way as the training dataset was preprocessed and rather feeding the test example directly into the trained model. As a result, the trained model performs badly on the given test example on which it was supposed to perform quite good!
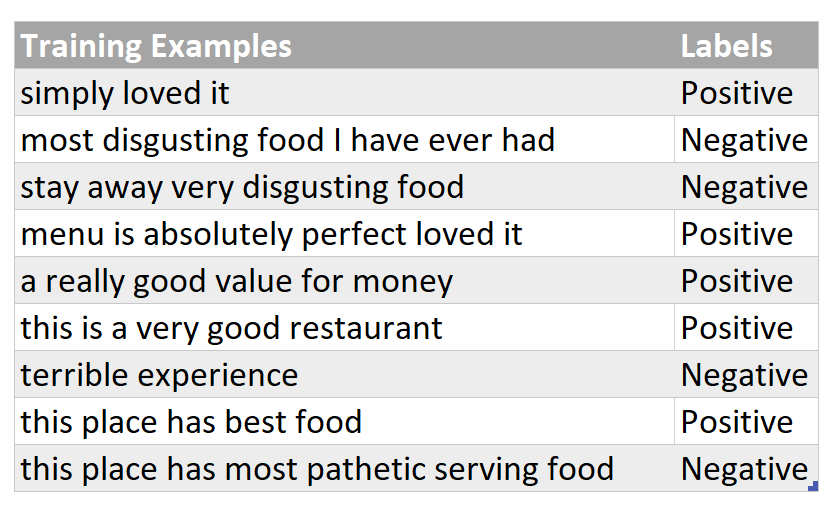
Step #2 : Training Your Naïve Bayes Model
Just simply make two bag of words (BoW), one for each category, and each of them will simply contain words and their corresponding counts. All words belonging to “Positive” sentiment/label will go to one BoW and all words belonging to “Negative” sentiment will have their own BoW. Every sentence in training set is split into words (on the basis of space as a tokenizer/separator) and this is how simply word-count pairs are constructed as demonstrated below :
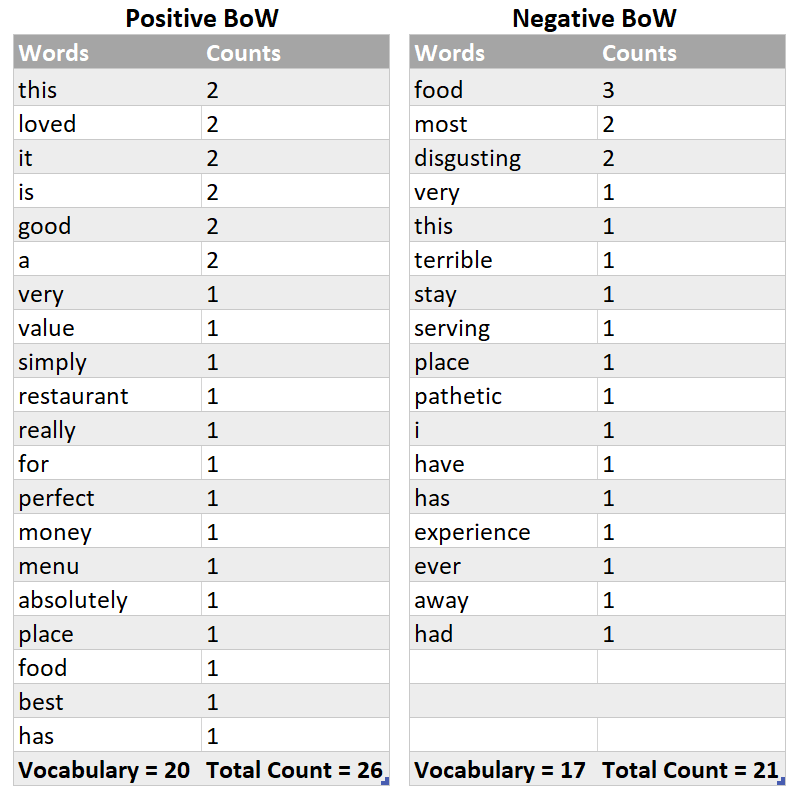
Milestone # 2 Achieved ????
Grrreat! You have achieved two milestones ! ???? ???? ????
Now its break time ! You can grab a cup of coffee or stretch your muscles before diving into the Grand Grand Grand Milestone # 3

Caution : We are about to begin the most essential part of the Naive Bayes Model i.e using the above trained model for prediction of restaurant reviews. I now It’s a bit lengthy but totally worth it as we will be discussing each and every minute detail leaving zero ambiguities as the end result !
The Testing Phase — Where Prediction Comes into the Play!
Consider that now your model is given a restaurant review, “Very good food and service!!!”, and it needs to classify to what particular category it belongs to. A positive review or a negative one? We need to find the probability of this given review of belonging to each category and then we would assign it either a positive or a negative label depending upon for which particular category this test example was able to score more probability.
Finding Probability of a Given Test Example
Step # 1 : Preprocessing of Test Example
Preprocess the test example in the same way as the training examples were preprocessed i.e changing examples to lower case and excluding everything apart from letters/alphabets.

Step # 2 : Tokenization of Preprocessed Test Example
Tokenize the test example i.e split it into single words.

A Quick Side Note : You must be already familiar with the term “feature” in machine learning. Here, in Naive Bayes, each word in the vocabulary of each class of the training data set constitutes a categorical feature. This implies that counts of all the unique words (i.e vocabulary/vocab) of each class are basically a set of features for that particular class. And why do we need “counts” ? because we need a numeric representation of the categorical word features as the Naive Bayes Model/Algorithm requires numeric features to find out the probabilistic scores!
Step # 3 : Using Probability to Predict Label for Tokenized Test Example
The not so intimidating mathematical form of finding probability
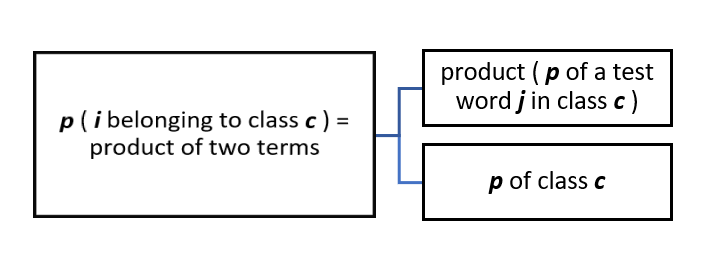
- let i = test example = “Very good food and service!!!”
- Total number of words in i = 5, so values of j (representing feature number) vary from 1 to 5. It’s that simple!
Let’s map the above scenario to the given test example to make it more clear!
Let’s start calculating values for these product terms
Step # 1 : Finding Value of the Term : p of class c
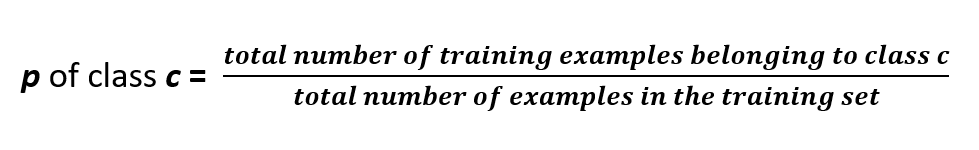

Step # 2 : Finding value of term : product (p of a test word j in class c)
Before we start deducing probability of a test word j in a specific class c let’s quickly get familiar with some easy peasy notation that is being used in the not so distant lines of this blog post:
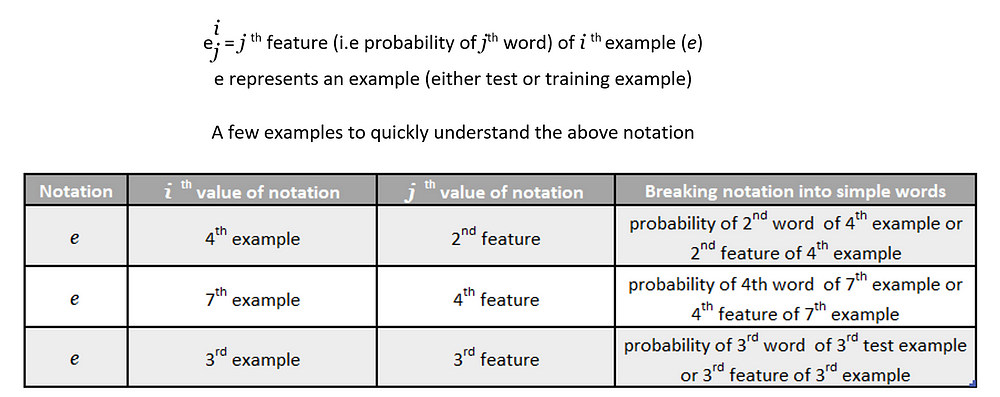
As we have only one example in our test set at the moment (for the sake of understanding), so i = 1.
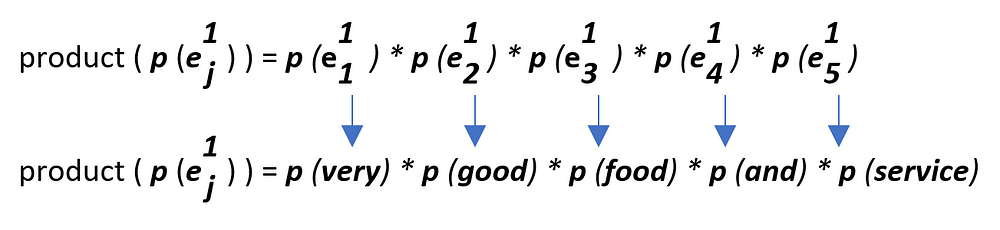
A Quick Side Note : During test time/prediction time, we map every word of test example against it’s count that was found during training phase. So, in this case, we are looking for in total 5 word counts for this given test example.

Just a random cat to keep you from falling asleep !
Finding Probability of a Test Word “ j ” in class c
Before we start calculating product ( p of a test word “ j ” in class c ), we obviously first need to determine p of a test word “ j ” in class c . There are two ways of doing this as specified below — which one should be actually followed and rather is practically used will be discovered in just a few minutes…
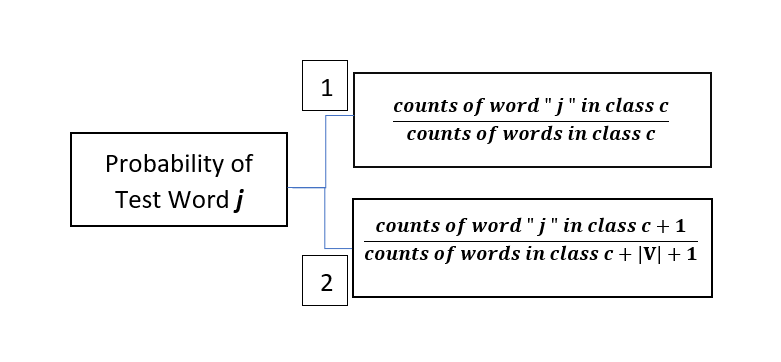
let’s first try finding probabilities using method number 1 :
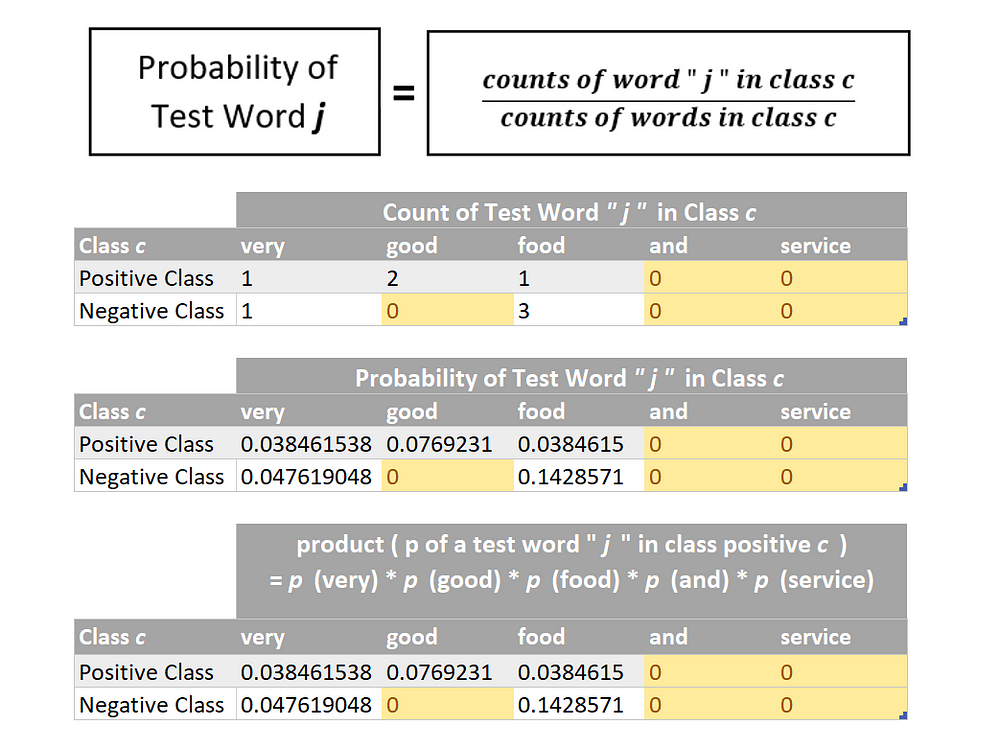
Now we can multiply the probabilities of individual words ( as found above ) in order to find the numerical value of the term :
product ( p of a test word “ j ” in class c )
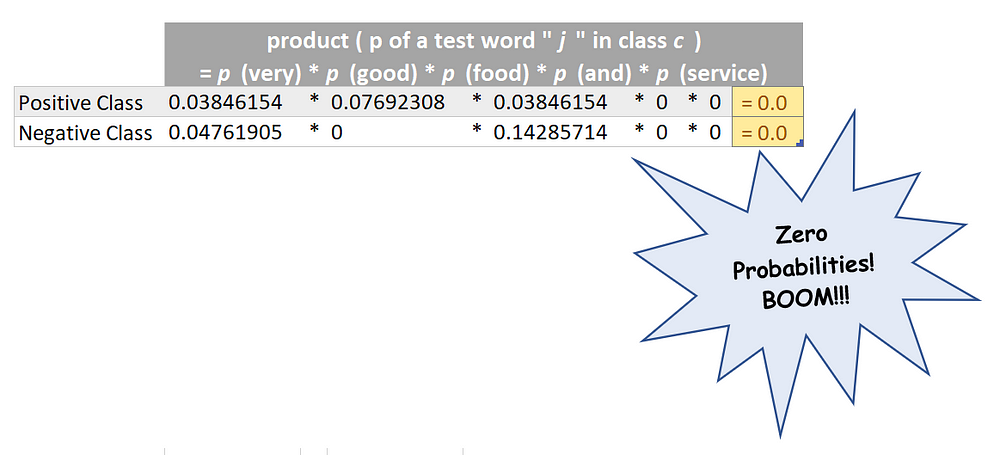

“ j ” in class c ) was zero for both the categories and this in turn was zero because a few words in the given test example (highlighted in orange) NEVER EVER appeared in our training dataset and hence their probability was zero! and clearly they have caused all the destruction!
So does this imply that whenever a word that appears in the test example but never ever occurred in the training dataset will always cause such destruction ? and in such case our trained model will never be able to predict the correct sentiment? It will just randomly pick positive or negative category since both have same zero probability and predict wrongly? The answer is NO! This is where the second method (numbered 2) comes into play and infact this is the mathematical formula that is actually used to deduce p ( i belonging to class c ) . But before we move on the method number 2, we should first get familiar with it’s mathematical brainy stuff!
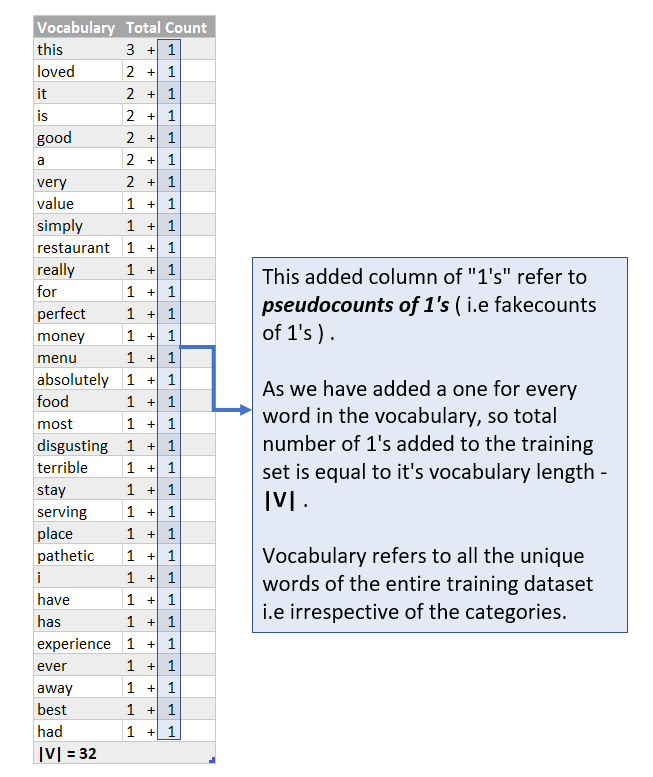
So now after adding pseudocounts of 1’s , the probability p of a test word that NEVER EVER APPEARED IN THE TRAINING DATASET WILL NEVER BE ZERO and therefore, the numerical value of the term product ( p of a test word “ j ” in class c ) will never end up as zero which in turn implies that
p ( i belonging to class c ) will never be zero as well! So all is well and no more destruction by zero probabilities!
So the numerator term of method number 2 will have an added 1 as we have added a one for every word in the vocabulary and so it becomes :
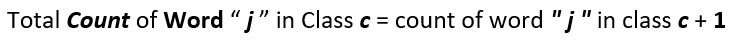
Similarly the denominator becomes :
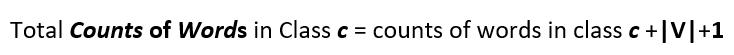
And so the complete formula :


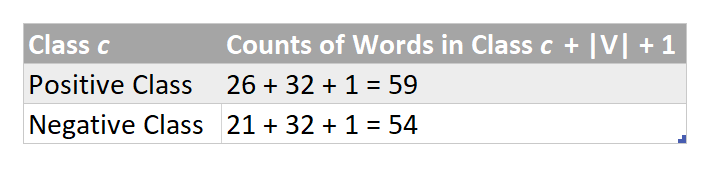

Yessssss ! You are almost there !
Now finding probabilities using method number 2 :
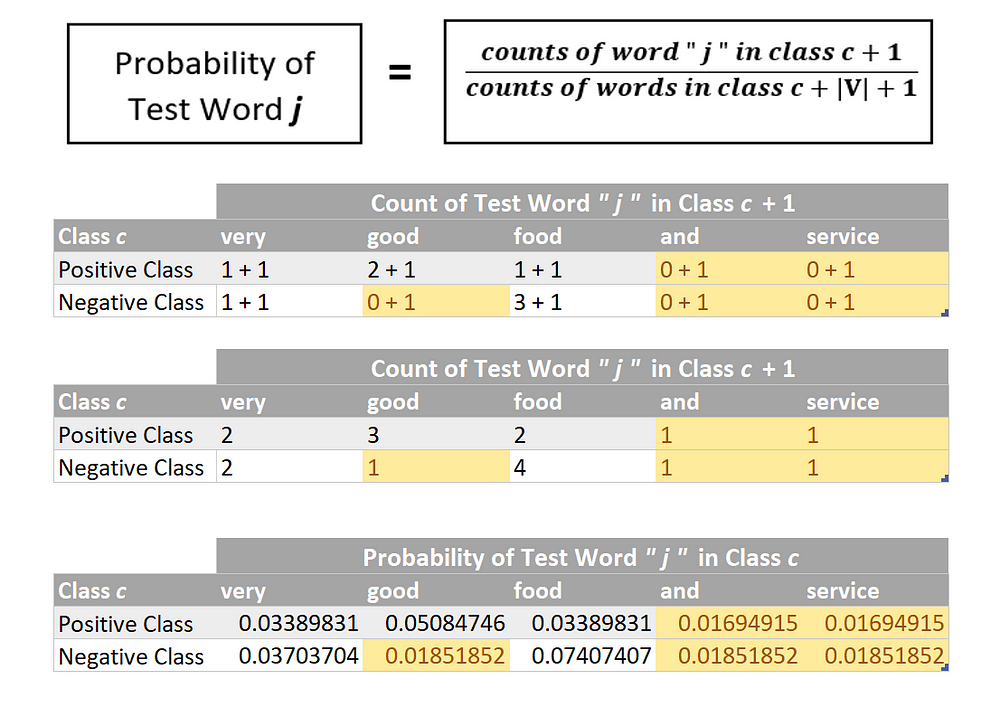


The Grand Grand Grand Milestone # 3 Achieved !! ???? ???? ????
Only a few final touch-ups are remaining ! You can take a short break before we move towards the ending notes.