 Apache Spark Introduction for Beginners
Apache Spark Introduction for Beginners
 Apache Spark Introduction for Beginners
Apache Spark Introduction for BeginnersAn extensive introduction to Apache Spark, including a look at the evolution of the product, use cases, architecture, ecosystem components, core concepts and more.
By Vikash Kumar, Tatvasoft.com.au
Businesses are utilizing Hadoop broadly to examine their informational indexes. The reason is that the Hadoop system depends on a basic programming model - MapReduce and it empowers a processing arrangement that is versatile, adaptable, blame tolerant and financially savvy.
But, the principal concern is to keep up speed in handling vast datasets as far as holding up time among inquiries and holding up the time to run the program. The below snapshot clearly justifies the limitation.
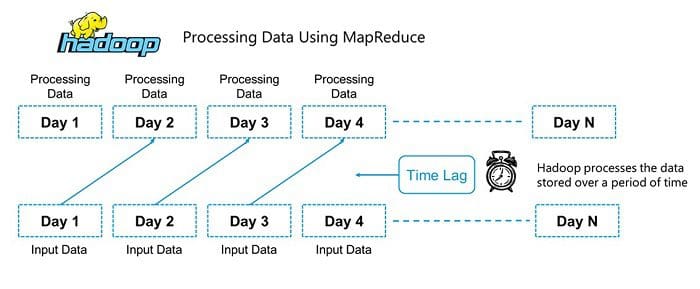
The answer the question “How to get over limitations of Hadoop MapReduce?” is APACHE SPARK. Don’t interpret that Spark and Hadoop are Competitors.
Evolution with Apache Spark
Spark was presented by Apache Software Foundation for accelerating the Hadoop computational registering programming process and overcoming its limitations. Rumors around suggest that Spark is nothing but an altered rendition of Hadoop and isn't dependent upon Hadoop. But the fact is "Hadoop is one of the approaches to implementing Spark, so they are not the competitors they are compensators."
The below snapshot clearly justifies how Spark processing is rendering the limitation of Hadoop.
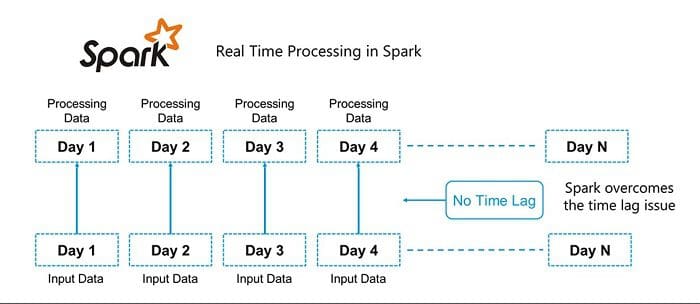
Apache Spark is an exceptionally a cluster computing technology, intended for quick computation. It depends on Hadoop MapReduce and it stretches out the MapReduce model to effectively utilize it for more kinds of computations, which incorporates intuitive questions and stream handling. The fundamental element of Spark is its in-memory clustering that expands the preparing pace of an application.
What Apache Spark is About
Apache Spark is a lightning fast cluster computing system. It provides the set of high-level API namely Java, Scala, Python, and R for application development. Apache Spark is a tool for speedily executing Spark Applications. Spark utilizes Hadoop in two different ways – one is for Storage and second is for Process handling. Just because Spark has its own Cluster Management, so it utilizes Hadoop for Storage objective.
Spark is intended to cover an extensive variety of remaining loads, for example, cluster applications, iterative calculations, intuitive questions, and streaming. Aside from supporting all these remaining tasks at hand in a particular framework, it decreases the administration weight of keeping up isolated apparatuses.
Spark is one of Hadoop's sub venture created in 2009 in UC Berkeley's AMPLab by Matei Zaharia. It was Open Sourced in 2010 under a BSD license. It was given to Apache programming establishment in 2013, and now Apache Spark has turned into the best level Apache venture from Feb-2014. And now the results are pretty booming.
Survey & Real-time Use Cases
Market rules and big agencies already tend to use Spark for their solutions. Flabbergast to know that the list includes - Netflix, Uber, Pinterest, Conviva, Yahoo, Alibaba, eBay, MyFitnessPal, OpenTable, TripAdvisor and much more. It can be said that Apache Spark Use Case stretch is spread right from Finance, Healthcare, Travel, e-commerce to Media & Entertainment industry.
Time is not back when many more domains examples will roll-out for using Spark in a myriad of ways.
Let's understand more about Apache Spark architecture, components, and features - that will absolutely witness why Spark is adopted by such a large community.
The numbers will surely awestruck you of the poll survey regarding why companies are intended to use the framework like Apache Spark for in-memory computing?

Apache Spark Architecture
Spark is accessible, intense, powerful and proficient Big Data tool for handling different enormous information challenges. Apache Spark takes after an ace/slave engineering with two primary Daemons and a Cluster Manager –
- Master Daemon – (Master/Driver Process)
- Worker Daemon – (Slave Process)
A spark cluster has a solitary Master and many numbers of Slaves/Workers. The driver and the agents run their individual Java procedures and users can execute them on individual machines. Below are the three methods of building Spark with Hadoop Components (these three components are strong pillars of Spark Architecture) -
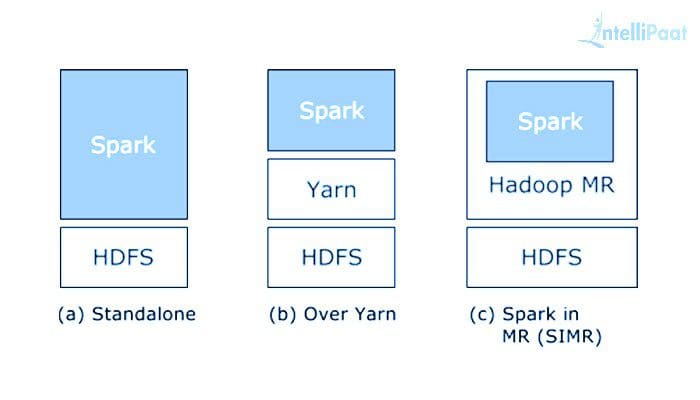
- Standalone - The arrangement implies Spark possesses the place on the top of HDFS(Hadoop Distributed File System) and space is allotted for HDFS, unequivocally. Here, Spark and MapReduce will run one next to the other to covering all in the form of Cluster.
- Hadoop Yarn - Hadoop Yarn arrangement implies, basically, Spark keeps running on Yarn with no pre-establishment or root get to required. It incorporates Spark into the Hadoop environment or the Hadoop stack. It enables different parts to keep running on the top of the stack having an explicit allocation for HDFS.
- Spark in MapReduce - Spark in MapReduce is utilized to dispatch start work notwithstanding independent arrangement. With SIMR, the client can begin Spark and uses its shell with no regulatory access.
Apache Spark Ecosystem Components
Apache Spark guarantee for quicker information handling and also simpler advancement is conceivable only because of Apache Spark Components. All of them settled the issues that happened while utilizing Hadoop MapReduce. Now, let's talk about each Spark Ecosystem Component one by one -
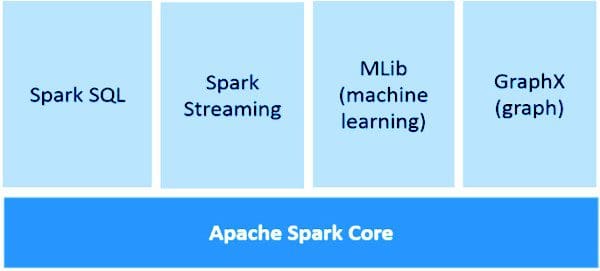
1. Apache Spark Core
Spark Core is the basic general execution engine for the Spark platform that all other functionalities are based upon. It gives In-Memory registering and connected datasets in external storage frameworks.
2. Spark SQL
Spark SQL is a segment over Spark Core that presents another information abstraction called SchemaRDD, which offers help for syncing structured and unstructured information.
3. Spark Streaming
Spark Streaming use Spark Core's quick scheduling ability to perform Streaming Analytics. It ingests information in scaled-down clusters and performs RDD (Resilient Distributed Datasets) changes on those small-scale groups of information.
4. MLlib (Machine Learning Library)
MLlib is a Distributed Machine Learning structure above Spark in view of the distributed memory-based Spark architecture. It is, as indicated by benchmarks, done by the MLlib engineers against the Alternating Least Squares (ALS) executions. Spark MLlib is nine times as rapid as the Hadoop disk version of Apache Mahout (before Mahout picked up a Spark interface).
5. GraphX
GraphX is a distributed Graph-Processing framework of Spark. It gives an API for communicating chart calculation that can display the client characterized diagrams by utilizing Pregel abstraction API. It likewise gives an optimized and improved runtime to this abstraction.
6. Spark R
Essentially, to utilize Apache Spark from R. It is R bundle that gives light-weight frontend. In addition, it enables information researchers to break down expansive datasets. Likewise permits running employments intuitively on them from the R shell. In spite of the fact that, the main thought behind SparkR was to investigate diverse methods to incorporate the ease of use of R with the adaptability of Spark.
Apache Spark Abstractions & Concepts
In the below section, it is briefly discussed regarding the abstractions and concepts of Spark -
- RDD (Resilient Distributed Dataset) - RDD is the central and significant unit of data in Apache Spark. It is a distributed collection of components across cluster nodes and can implement parallel operations. Parallelized Collections, External datasets and Existing RDDs are the three methods for creating RDD.
- DAG (Direct Acyclic Graph) - DAG is a designated graph with no inscribed sequences. It reads data from HDFS and Map & Reduce operations are applied. It comprises a series of vertices such that every edge is directed from initial to succeeding in the progression.
- Spark Shell - An interactive Shell that can execute a command line of the application effective because of the interactive testing and capability to read a large amount of data sources in various types.
- Transformations - It builds a new RDD from the existing one. It transfers the dataset to the function and then returns the new dataset.
- Actions - It turns final result to driver program or corresponds it to the external data store.
Apache Spark Features
Spark - mainly designed for Data Science - is considered as the largest Open source project for Data Processing. Let’s talk about sparkling features of Apache Spark -
- Fast in Data Processing, 10 times faster on Disk and 100 times swifter in Memory
- Spark with abstraction-RDD provides Fault Tolerance with ensured Zero Data loss
- Multiple languages support namely Java, R, Scala, Python for building applications
- Increase in system efficiency due to Lazy Evaluation of transformation in RDD
- In-Memory Processing resulting in high computation speed and acyclic data-flow
- With 80- high level operators it is easy to develop Dynamic & Parallel applications
- Real-time data stream processing with Spark Streaming
- Flexible to run Independently and can be integrated with Hadoop Yarn Cluster Manager
- Cost Efficient for Big data as minimal need of storage and data center
- Futuristic analysis with built-in tools for machine learning, interactive queries & data streaming
- Persistence and Immutable in nature with data paralleling processing over the cluster
- Graphx simplifies Graph Analytics by collecting algorithm and builders
- Re-using Code for batch processing and to run ad-hoc queries
- Progressive and expanding Apache community active for Quick Assistance
When to Use and When to Not Use Apache Spark?
Features set is more than enough to justify the pluses of using Apache Spark for Big Data Analytics, yet to justify the scenarios when and when not to use Spark is necessary to provide broader insights.
Can Use for -
Deployment modules that are co-related with Data Streaming, Machine Learning, Collaborative Filtering Interactive Analysis, and Fog Computing should surely use the perks of Apache Spark to experience a revolutionary change in decentralized storage, data processing, classification, clustering, data enrichment, complex session analysis, triggered event detection and ETL streaming.
Can’t Use for -
Spark is not fit for a multi-user environment. Spark as of now is not capable of handling more users concurrency, maybe in future updates this issue will be overcome. Yet an alternate engine like Hive for handling large batch projects.
Conclusion
Most advanced and popular product of Apache Community, Spark decreases the time complexity of the system. Fast Computations, increase Performance, structured and unstructured Data Streaming, Graph Analytics, richer Resource Scheduling capabilities ensures smooth, engaging and customer experience compatible with the system.
Bio: Vikash Kumar is the marketing manager at TatvaSoft. Vikash handles marketing activities by taking care of the digital media marketing channels.
Related:
- Project Hydrogen, new initiative based on Apache Spark to support AI and Data Science
- Introduction to Apache Spark
- Deep Learning With Apache Spark: Part 2