Airbnb Rental Listings Dataset Mining
An Exploratory Analysis of Airbnb’s Data to understand the rental landscape in New York City.
By Sarang Gupta, Columbia University

Airbnb has seen a meteoric growth since its inception in 2008 with the number of rentals listed on its website growing exponentially each year. Airbnb has successfully disrupted the traditional hospitality industry as more and more travellers, not just the ones who are looking for a bang for their buck but also business travellers resort to Airbnb as their premier accommodation provider.
New York City has been one of the hottest markets for Airbnb, with over 52,000 listings as of November 2018. This means there are over 40 homes being rented out per square km. in NYC on Airbnb! One can perhaps attribute the success of Airbnb in NYC to the high rates charged by the hotels, which are primarily driven by the exorbitant rental prices in the city.
In this post, I will perform an exploratory analysis of the Airbnb dataset sourced from the Inside Airbnb website to understand the rental landscape in NYC through various static and interactive visualisations.
The analysis has been done in R. Source code can be found on my Github: https://github.com/saranggupta94/airbnb
Description of Data
The dataset comprises of three main tables:
listings- Detailed listings data showing 96 attributes for each of the listings. Some of the attributes used in the analysis arepricecontinuous),longitude(continuous),latitude(continuous),listing_type(categorical),is_superhost(categorical),neighbourhood(categorical),ratings(continuous) among others.reviews- Detailed reviews given by the guests with 6 attributes. Key attributes includedate(datetime),listing_id(discrete),reviewer_id(discrete) andcomment(textual).calendar- Provides details about booking for the next year by listing. Four attributes in total includinglisting_id(discrete),date(datetime),available(categorical) andprice(continuous).
A quick glance at the data shows that there are:
- 50,968 unique listing in NYC in total. The first rental in NYC was up in April, 2008 in Harlem, Manhattan.
- Over 1 million reviews have been written by guests since then.
- The price for a listing ranges from $10 per night to $10,000(!) per night. Listing with $10,000 price tag are in Greenpoint, Brooklyn; Astoria, Queens and Upper West Side, Manhattan.
Airbnb’s Meteoric Rise in NYC
Airbnb’s success hinges on the its wide host network alongside the number of guests using its services to find vacation rentals. NYC has seen an exponential growth in both — the number of unique listings and the number of travellers booking their accommodation on Airbnb.
The below animation shows Airbnb’s host network growth in the city from 2008 to 2018. As you can observe, there is rapid growth in the number of listings in all boroughs of the city as depicted by the cluttered blue dots.
Number of Airbnb listings over the years
Airbnb’s first New York listing was in Harlem in the year 2008, and the growth since has been exponential. Around 600 properties were added in the first couple years, mostly in Manhattan and Brooklyn. Downtown Manhattan and close lying areas in Brooklyn have always had high Airbnb presence. The number of listings has roughly doubled each year since then. By the year 2015, every neighbourhood of Manhattan had a multiple listings. Interestingly Bronx has very few listings, so few that the Manhattan-Bronx border can be seen in the animation by the sudden drop in listings. Since 2016, Airbnb listings have spread to parts of Staten Island. A prediction of 70k properties by 2020 shouldn’t be far off.
I was not able to obtain the data on the number of booking made on Airbnb over the years. Instead, I have used ‘number of reviews’ as a proxy for the demand for Airbnb rentals. As per the company, about 50% of the guests review the hosts/listings, hence studying the number of reviews will give us a good estimation of the demand.
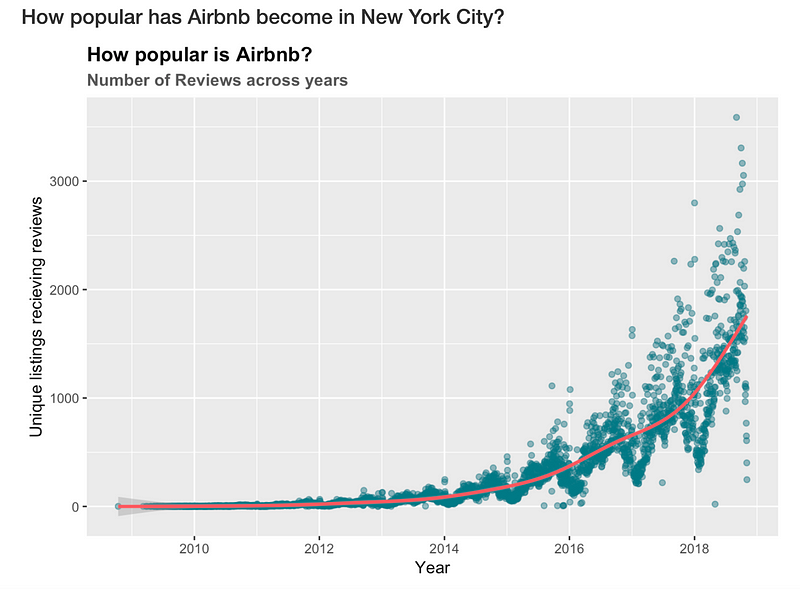
Similar to the number of hosts, the number of unique listings receiving reviews has increased steadily over the years, indicating an exponential increase in the demand for Airbnb rentals.
To get a granular view of all the listing, checkout the below interactive RShinyapp that I have designed that lets users filter the listings based on various parameters. Below is a screenshot of the RShiny app. You can try the actual app out through the link: https://ankitpeshin.shinyapps.io/listings/(apologies, it takes a few seconds to load)
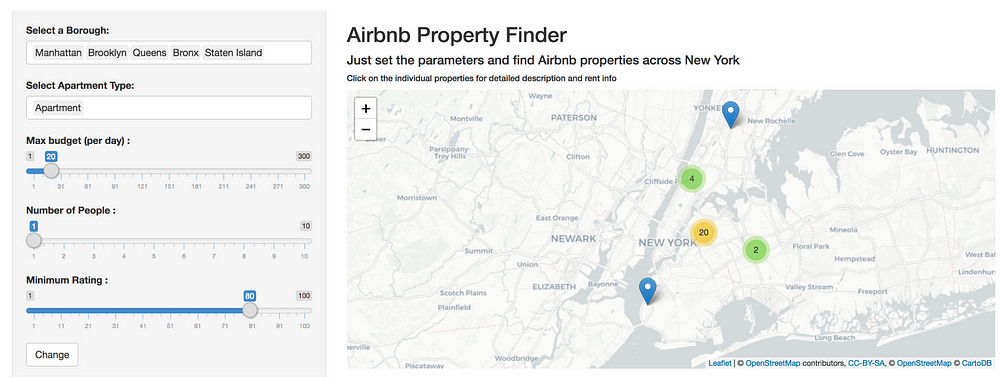
Airbnb Property Finder: RShiny app
Location, Location, Location! : Understanding NYC’s Real Estate scene
Airbnb users rate their stay on the basis of location, cleanliness and a host of other parameters. Here I work with the location score data. It would be interesting to see the average location scores for each neighbourhood. The location scores have to be a firm indicator of the appeal of the neighbourhood. Highly rated neighbourhoods will tend to have better connectivity (subway stations), will tend to be closer to the city hotspots (Times Square, Empire State, Wall Street).
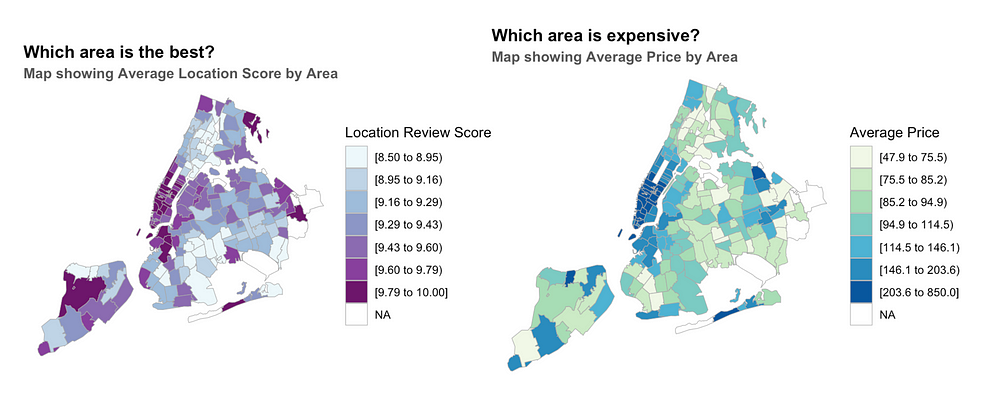
Manhattan receives the highest location scores for the downtown region (esp below Central Park). In Staten Island, the areas close to the State Park have the highest location scores. Brooklyn neighbourhoods close to Manhattan tend to have higher location ratings. Looking at the NY subway system in Brooklyn, it is interesting to observe that the highly rated areas correspond with subway line presence. The same is true for Bronx where subway lines do not go.
The listing costs are largely in line with the location scores. Highly rated locations also tend to be the most expensive ones. It is obvious that the highly rated location would also tend to be costly (demand vs supply)
It is however interesting to spot a few outliers : i). Find high rating — low rent regions (best of both worlds) : The State Park region in Staten Island (discussed in the previous graph) is one such region where rents tend to be fairly low despite having the highest location rating. Another such sweet-spot lies to the North East of Brooklyn. ii). Find low rating — high rent regions (worst of both worlds) : The Elm Park region of Staten Island has disproportionately high rents, yet very low location scores. Other such locations can be found towards the Northern Bronx regions.
Now let’s explore the types of listings that are there in NYC. Below is a chart that shows distribution of different listing types by Boroughs.
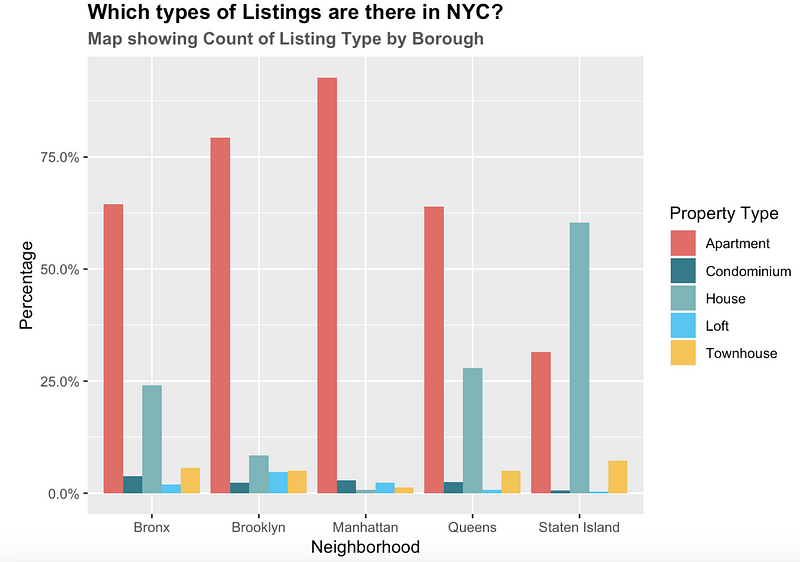
Apartment style listings are highest in number in all four neighbourhoods except Staten Island. Staten Island has more ‘House’ style property than ‘Apartments’. This seems intuitive, as Staten Island is sparsely populated, hence has more ‘space’ compared to the other boroughs.
It’s all about money: Analysing the Demand and Pricing
In this section, I will conduct a demand and price analysis for Airbnb rentals. I will look at demand over the years since the inception of Airbnb in 2008 and across months of the year to understand seasonality.
As mentioned earlier, I will be using the number of reviews as a proxy for the demand for Airbnb rentals due to unavailability of the booking data. The assumption is that the the number of reviews correspond to the demand for the rentals on the basis of Airbnb’s claim that 50% of guests review their stay. Furthermore, a review has to be provided by guests within 2 weeks of their stay, hence the number of reviews can provide a good estimate of the demand during a particular period.
Through the ‘How popular is Airbnb?’ graph shown before(I have provided it again below for ease of reference), one can observe a seasonal pattern in the number of reviews/demand. Every year there are peaks and drop in the demand, indicating that certain months are busier compared to the others.
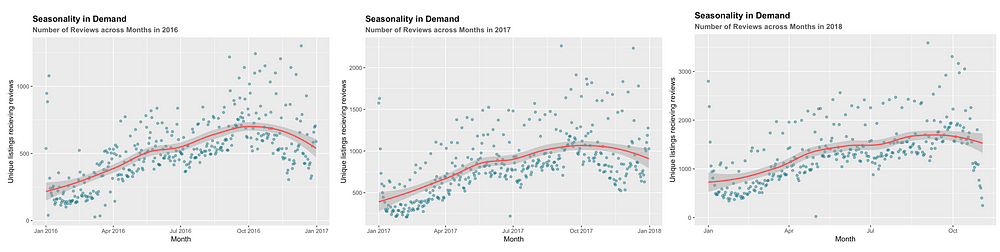
Exploring this at a granular level reveals that the demand is lowest in January and increases until October, when it begins to falls until the end of the year.
Is there a seasonality in the prices of rentals? Let us look at the daily average prices of the listings across the years.
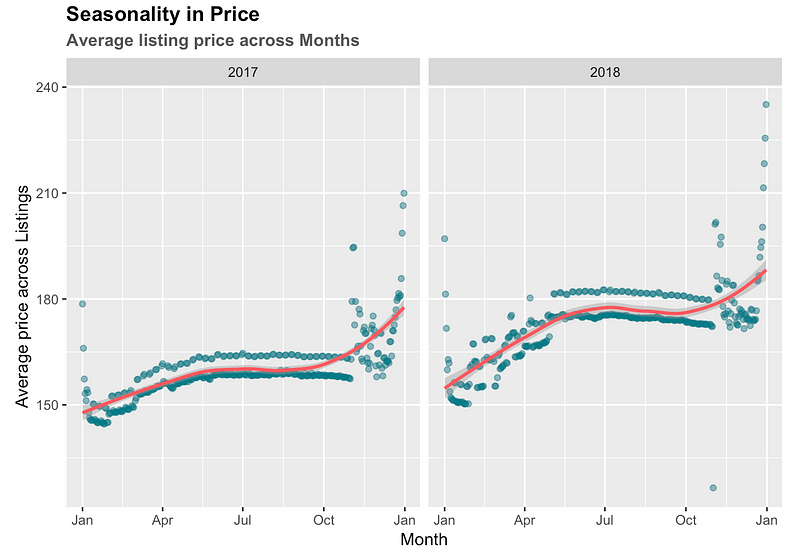
The average prices across listings tends to increase as one progresses along the year and spikes in December. The pattern is similar to that of the number of reviews/demand except in the months of November and December, where the number of reviews (indicative of demand) starts to fall.
We can also see two sets of points on the charts which depicts that average prices on certain days were higher compared to the other days. Following, I will plot a box plot of average prices by day of the week to understand this phenomenon.
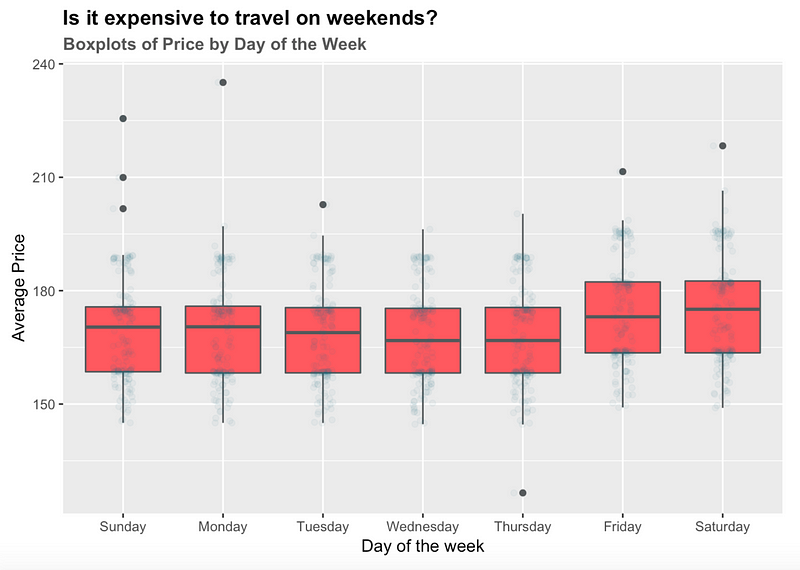
As we can see, Fridays and Saturdays are more expensive compared to the other days of the weeks, perhaps due to higher demand for lodging.
I will end the analysis of the section by studying how the occupancy looks like for the next year. Using data from the table calendar, I will find out the percentage occupancy for the next year i.e. as of November 3, 2018 (the date when the data was collected), what percentage of listings have already been booked. I was not able to obtain the past data on the occupancy, hence I could not study what the actual occupancy rates looked like.
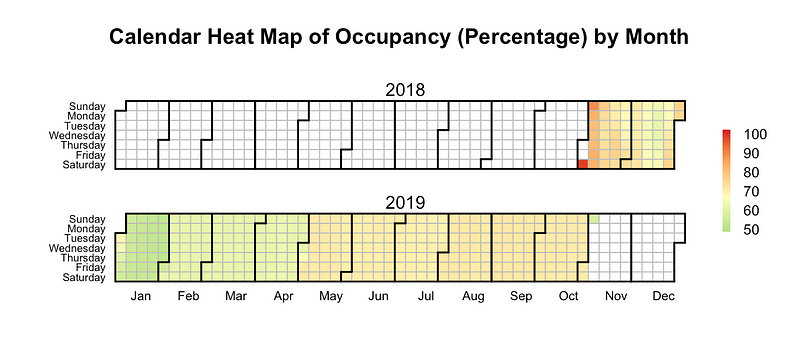
It can be inferred that January tends to be the quietest, and the occupancy rate increases as we progress through the year. This ties up with the results from the analysis of the number of reviews (indicative of the demand) that shows an increasing trend across the year.
Getting into the Customer’s Head : Analysing Customer Reviews
The dataset provides us with a ton of data, but nothing as insightful and close to the customer as their reviews/feedback. If mined properly, they can tell us a lot about the customer mindset, their expectations and how well those were met. For the final result to make sense, the review text data requires a lot of cleaning — eg. the words need to be stemmed, commas-fullstops-percentages etc need to be removed, common English words and stop words need to be removed etc. There are more than a million reviews, so I take a random sample of this data, in this case ~30k reviews.
An analysis of the word cloud shows interesting trends; Location seems to be key, since the words “neighbourhood”, “location”, “area” are featured prominently in the word cloud. Transport options like “subway”, “walk” also find frequent mention. Airbnbs are short term rentals, yet people seem to lay stress on the comfort aspect of their stay, words like “kitchen” tell us that many folks would rather cook than eat out. Availability of “Restaurants” close by find mention too. Bathrooms and Beds, as expected can be clear deal breakers if not in top condition. The word “Host” finds a lot of mention; indicating the important role that hosts play in shaping the Airbnb experience.
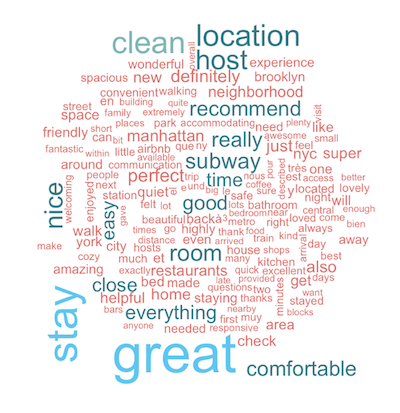
Word vectors provide an effective way to figure out the closest words to particular search terms. Using the review data, I constructed a vector space to build a word cloud of similar words to derive interesting insights.
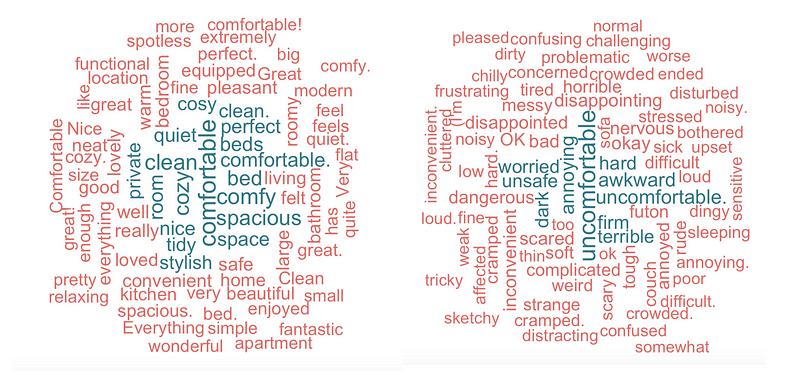
The first word cloud is for the word “uncomfortable”. Words similar to “uncomfortable” are usually those that occur in conjunction with it frequently, i.e reasons for the discomfort. The word cloud shows just that — notice words like “cramped”, “crowded”,“small”, “stuffy” and “cluttered” indicating that lack of space is one of the most common complaints. “Hot”, “damp” and “cold” are some of the common temperature issues. “Dusty”, “dirty” and “unclean” surroundings will prompt people to write negative feedback. Many feel “nervous”,“unsafe” and “stressful”; clearly a red flag for future tenants.
Similarly, querying by the keyword “comfortable”, we hope to see things that led to a positive experience. Prominently featured are words like “quiet”, “walkable”, “clean”, “spotless”, etc, again demonstrating the importance of environment, location and cleanliness. Helpful “hosts” and “communication” lead to a comfortable. Cleanliness of linens and the bed size leave a decisive impression.
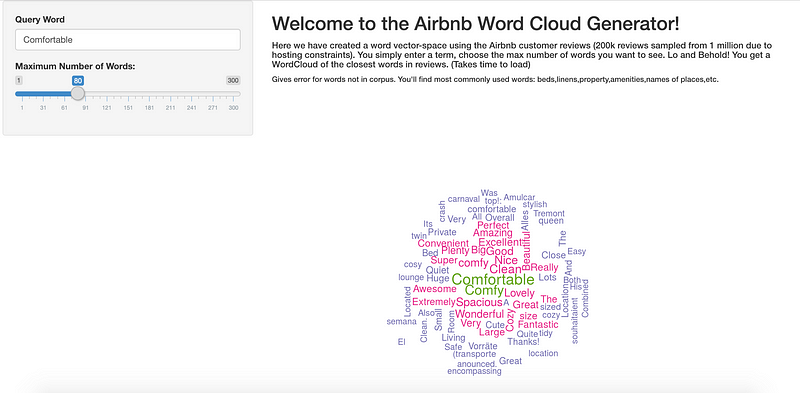
Check out the Shiny App that serves as an extension to the Word-Vector analysis of the customer reviews. You can query the vector to find “similar” words and build a custom word-cloud. Enter any valid query word and set the “max words” in the word cloud. A valid query word would be one that is present in the corpus, else it wouldn’t be part of the word vector.
Below is a screenshot, you can try the actual app out through the link: https://ankitpeshin.shinyapps.io/wordcloud_generator/ (allow it some time to load).
Hosts with Super Powers! : Analysing what it takes to become a Superhost
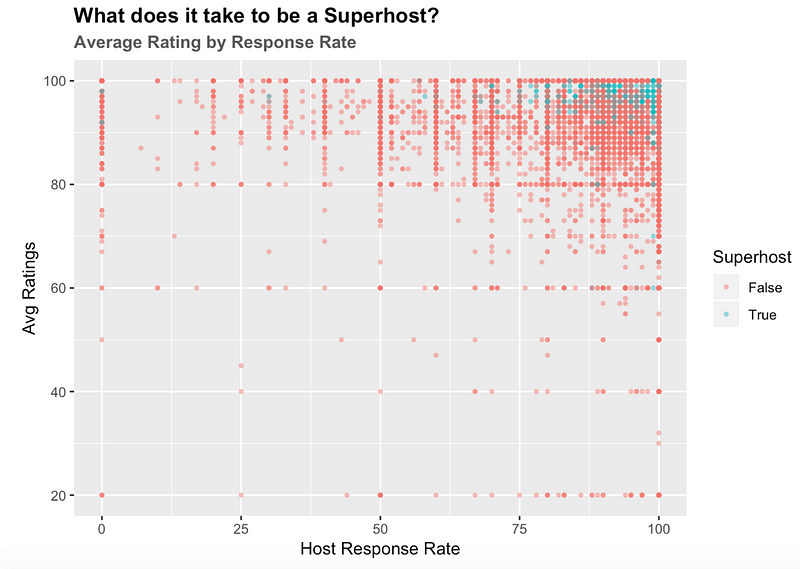
Airbnb awards the title of “Superhost” to a small fraction of its dependable hosts. This is designed as an incentive program that is a win-win for both the host, Airbnb, and their customers. The superhost gets more business in the form of higher bookings, the customer gets improved service and Airbnb gets happy satisfied customers.
But what does it take to be a Superhost? Airbnb’s site has a set of requirements that must be fulfilled in order to become one. Maintaining a review rate above 50%, a response rate above 90%, etc. Our findings, while mostly in line with the Airbnb’s guidelines, also show some interesting outliers.While most super-hosts are in the high-rating:high-response-rate region, we can also see a few hosts with response rates less than 75% (which violates the 90%+ criteria set by Airbnb). This is a very small fraction of the hosts. In terms of Ratings, almost all hosts are rated 80% and above.
With that being said, most Airbnb hosts lie in the high-rating:high-response region, but only a small fraction get to be super hosts. So clearly, becoming a Superhost takes a lot more than high ratings & response rates.
All in all, Airbnb has seen a phenomenal rise in New York City. The above analysis highlights a few trends from data to give an overview of Airbnb’s market. Inside Airbnb hosts similar data for several other major cities around the world and I believe it would be quite interesting to compare the patterns and trends amongst these cities.
Do checkout the source code on my Github: https://github.com/saranggupta94/airbnb
I am currently pursuing a Master’s in Data Science at Columbia University, New York. This project was done as part of the Exploratory Data Analysis and Visualisation course. Special thanks to Ankit Peshin and Ankita Agrawal for their contribution.
Feel free to check out my other projects at http://www.columbia.edu/~sg3637/or drop me a message at saranggupta94@gmail.com
Bio: Sarang Gupta is a Graduate student in the Data Science program at Columbia University with two years prior experience of working as an analyst at Goldman Sachs. He is passionate about machine learning and data science with applications in business and finance. He holds a Bachelor's degree in Industrial Engineering and Business Management from the Hong Kong University of Science and Technology.
Original. Reposted with permission.
Related:
- The Five Best Data Visualization Libraries
- How to build a data science project from scratch
- What is Minimum Viable (Data) Product?