 Your AI skills are worth less than you think
Your AI skills are worth less than you think

 Your AI skills are worth less than you think
Your AI skills are worth less than you thinkWe are in the middle of an AI boom. That doesn’t mean that making your AI startup succeed is easy. I think there are some important pitfalls ahead of anyone trying to build their business around AI.
By Ric Szopa, Inovo.vc
We are in the middle of an AI boom. Machine Learning experts command extraordinary salaries, investors are happy to open their hearts and checkbooks when meeting AI startups. And rightly so: this is one of those transformational technologies that occur once per generation. The tech is here to stay, and it will change our lives.
That doesn’t mean that making your AI startup succeed is easy. I think there are some important pitfalls ahead of anyone trying to build their business around AI.

My son and me, image processed using Artistic Style Transfer. This technique sparked my fascination with Deep Learning.
The value of your AI skills is declining
In 2015 I was still at Google and started playing with DistBelief (which they would later rename to TensorFlow). It sucked. It was painfully awkward to write, the main abstractions didn’t quite match what you expected. The idea of making it work outside of Google’s build system was a pipe dream.
In late 2016 I was working on a proof of concept to detect breast cancer in histopathological images. I wanted to use transfer learning: take Inception, Google’s best image classification architecture at the time, and retrain it on my cancer data. I would use the weights from a pretrained Inception as provided by Google, just changing the top layers to match what I was doing. After a long time of trial and error in TensorFlow, I finally figured out how to manipulate the different layers, and got it mostly working. It took a lot of perseverance and reading TensorFlow’s sources. At least I didn’t have to worry too much about dependencies, as the TensorFlow people mercifully prepared a Docker image.
In early 2018 the task from above wasn’t suitable for an intern’s first project, due to lack of complexity. Thanks to Keras (a framework on top of TensorFlow) you could do it in just a few lines of Python code, and it required no deep understanding of what you were doing. What was still a bit of a pain was hyperparameter tuning. If you have a Deep Learning model, you can manipulate multiple knobs like the number and size of layers, etc. How to get to the optimal configuration is not trivial, and some intuitive algorithms (like grid search) don’t perform well. You ended up running a lot of experiments, and it felt more like an art than a science.
As I am writing these words (beginning of 2019), Google and Amazon offer services for automatic model tuning (Cloud AutoML, SageMaker), Microsoft is planning to do so. I predict that manual tuning is going the way of dodo, and good riddance.
I hope that you see the pattern here. What was hard becomes easy, you can achieve more while understanding less. Great engineering feats of the past start sounding rather lame, and we shouldn’t expect our present feats to fare better in the future. This is a good thing and a sign of amazing progress. We owe this progress to companies like Google, who are investing heavily in the tools, and then giving them away for free. The reason why they do that is twofold.

Your office after you’ve been commoditized.
First, this is an attempt to commoditize the complement to their actual product, which is cloud infrastructure. In economics, two goods are complementary if you tend to buy them together. Some examples: cars and gasoline, milk and cereal, bacon and eggs. If the price of one of the complements goes down, the demand for the other will go up. The complement to the cloud is the software that runs on top of it, and AI stuff has also the nice property that it requires a lot of computational resources. So, it makes a lot of sense to make its development as cheap as possible.
The second reason why Google in particular is so gung ho on AI is that they have a clear comparative advantage with respect to Amazon and Microsoft. They started earlier, and it was them who popularized the concept of Deep Learning after all, so they managed to snatch a lot of the talent. They have more experience in developing AI products, and this gives them an edge when it comes to developing tools and services necessary for them.
As exciting as the progress is, it’s bad news for both companies and individuals who have invested heavily in AI skills. Today, they give you a solid competitive advantage, as training a competent ML engineer requires plenty of time spent reading papers, and a solid math background to start with. However, as the tools get better, this won’t be the case anymore. It’ll become more about reading tutorials than scientific papers. If you don’t realize your advantage soon, a band of interns with a library may eat your lunch. Especially, if the interns have better data, which brings us to my next point…
Data is more important than fancy AI architectures
Let’s say that you have two AI startup founders, Alice and Bob. Their companies raised around the same amount of money, and are fiercely competing over the same market. Alice invests in the best engineers, PhDs with a good track record in AI research. Bob hires mediocre but competent engineers, and invests her (“Bob” is short for Roberta!) money in securing better data. On which company would you bet your money?
My money would be squarely on Bob. Why? At its essence, machine learning works by extracting information from a dataset and transferring it to the model weights. A better model is more more efficient at this process (in terms of time and/or overall quality), but assuming some baseline of adequacy (that is, the model is actually learning something) better data will trump a better architecture.
To illustrate this point, let’s have a quick and dirty test. I created two simple convolutional networks, a “better” one, and a “worse” one. The final dense layer of the better model had 128 neurons, while the worse one had to make due with only 64. I trained them on subsets of the MNIST dataset of increasing size, and plotted the models’ accuracy on the test set vs the number of samples they were trained on.
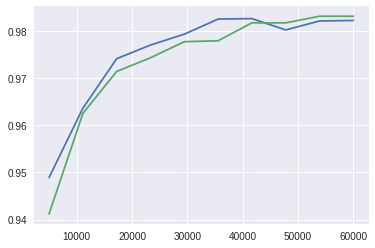
Blue is the “better” model, green the “worse” model.
The positive effect of training dataset size is obvious (at least until the models start to overfit and accuracy plateaus). My “better” model, blue line, clearly outperforms the “worse” model, green line. However, what I want to point out is that the accuracy of the “worse” model trained on 40 thousand samples is better than of the “better” model at 30 thousand samples!
In my toy example we are dealing with a relatively simple problem, and we have a comprehensive dataset. In real life, we usually don’t have such a luxury. In many cases, you never escape the part of the graph in which increasing the dataset has such a dramatic effect.
What is more, Alice’s engineers in fact aren’t competing just with Bob’s people. Due to the open culture of the AI community and its emphasis on knowledge sharing, they are also competing with researchers at Google, Facebook, Microsoft, and thousands of universities around the world. Taking the best performing architecture currently described in the literature and retraining it on your own data is a battle tested strategy if your goal is to solve a problem (as opposed to making an original contribution to science). If there’s nothing really good available right now, it’s often a matter of waiting a quarter or two until someone comes up with a solution. Especially that you can do things like host a Kaggle competition to incentivize researchers to look into your particular problem.
Good engineering is always important, but if you are doing AI, the data is what creates the competitive advantage. The billion dollar question is, however, if you are going to be able to maintain your advantage.
In AI, maintaining your competitive advantage is hard
With her superior dataset Bob successfully competes with Alice, and she’s doing great. She launches her product and is steadily gaining market share. She can even start hiring better engineers, as the word on the street is that her company is the place to be.

Photo by Alex Holyoake on Unsplash
Chuck has some catching up to do, but he has a lot more money than Bob. This matters when it comes to building the dataset. It’s very hard to accelerate an engineering project by throwing money at it. In fact, assigning too many new people can hinder development. Creating a dataset, however, is a different sort of problem. Usually, it requires a lot of manual human labor — and you can easily scale it by hiring more people. Or it could be that someone has the data — then all you have to do is pay for a license. In any case — the money makes it go a lot faster.
Why was Chuck able to raise more money than Bob?
When a founder raises a round, they are trying to balance two objectives potentially at odds with each other. They need to raise enough money to be able to win. But they cannot raise too much money, because that will lead to excessive dilution. Taking an external investor means selling part of the company. The founding team must maintain a high enough stake in the startup, lest their lose their motivation (running a startup is a hard job!).
The investors, on the other hand, want to invest in ideas that have a huge potential upside, but they must control for risk. As the perceived risk increases, they will ask for bigger chunk of the company for every dollar they pay.
When Bob was raising money, it was a leap of faith that AI can actually help with her product. Regardless of her qualities as founder, or how good her team was, it wasn’t out of the question that the problem she had been attacking was simply intractable. Chuck’s situation is very different. He knows the problem is tractable: Bob’s product is the living proof!
One of Bob’s potential responses to this challenge is raising another round. She should be in a good position for that, as (for the time being) she is still leading in the race. However, the situation may be more complicated. What if Chuck can secure access to the data through a strategic relationship? For example, imagine we are talking talking about a cancer diagnosis startup. Chuck could use his insider position at an important medical institution and secure a sweetheart deal with said institution. It could well be impossible for Bob to match that.

Your product should be defensible, ideally by having a deep moat.
So, how would you go about building a maintainablecompetitive advantage for an AI product? Some time ago I had the pleasure of talking to Antonio Criminisi from Microsoft Research. His idea is that the project’s secret sauce shouldn’t consist only of AI. For example, his InnerEye project uses AI and classical (not ML based) computer vision to analyze radiological images. To some extent, this may be at odds with why you are doing an AI startup in the first place. The ability to just throw data at a model and see it work is incredibly attractive. However, a traditional software component, the sort of which requires programmers to think about algorithms and utilize some hard to gain domain knowledge, is much more difficult to reproduce.
AI is best used like a lever
One way of categorizing something in a business is whether it adds value directly, or provides leverage to some other value source. Let’s take an an ecommerce company as an example. If you created a new product line you added value directly. There was nothing, now there are widgets, and the customers can pay for them. Establishing a new distribution channel, on the other hand, is a lever. By starting to sell your widgets on Amazon, you can double your sales volume. Cutting costs is also leverage. If you negotiate a better deal with the Chinese widget supplier, you can double your gross margin.
Levers have the potential to move the needle further than direct force application. However, a lever only works when it’s coupled with a direct value source. A minuscule number doesn’t stop to be small if you double or triple it. If you have no widgets to sell, getting a new distribution channel is a waste of time.
How should we look at AI in this context? There are plenty of companies that try to make AI their direct product (APIs for image recognition and the like). This can be very tempting if you are an AI expert. However, this is a singularly bad idea. First, you are competing with companies like Google and Amazon. Second, making a generic AI product that is genuinely useful is crazy hard. For example, I have always wanted to use Google’s Vision API. Unfortunately, we never ran into a customer whose needs would be adequately matched by the offering. It was always too much, or not enough, and custom development was preferable to the exercise of fitting a square peg in a round hole.
A much better option is to treat AI as a lever. You can take an existing, working business model and supercharge it with AI. For example, if you have a process which depends on human cognitive labor, automating it away will do wonders for your gross margins. Some examples I can think of are ECG analysis, industrial inspection, satellite image analysis. What is also exciting here is that, because AI stays in the backend, you have some non-AI options to build and maintain your competitive advantage.
Conclusion
AI is a truly transformational technology. However, basing your startup on it is a tricky business. You shouldn’t rely solely on your AI skills, as they are depreciating due to larger market trends. Building AI models may be very interesting, but what really matters is having better data than the competition. Maintaining a competitive advantage is hard, especially if you encounter a competitor who is richer than you, which is very likely to happen if your AI idea takes off. You should aim to create a scalable data collection process which is hard to reproduce by your competition. AI is well suited to disrupt industries which rely on the cognitive work of low qualified humans, as it allows to automate this work.
Bio: Ric Szopa (Twitter, Facebook, LinkedIn) is the CTO in Residence at Inovo.vc. Prior to Inovo, Ric was the CTO at MicroscopeIT, a software house specializing in computer vision, robotics, and microscope image processing. Before that he worked on YouTube’s database infrastructure at Google, in Mountain View, California and Zurich, Switzerland. Ric studied Philosophy at the University of Warsaw and Artificial Intelligence at the Katholieke Universiteit Leuven. His personal interests include Deep Learning, history, and playing the Ukulele.
Original. Reposted with permission.
Related:
- What were the most significant machine learning/AI advances in 2018?
- Building AI to Build AI: The Project That Won the NeurIPS AutoML Challenge
- Top Active Blogs on AI, Analytics, Big Data, Data Science, Machine Learning – updated