The Rise of Generative Adversarial Networks
A comprehensive overview of Generative Adversarial Networks, covering its birth, different architectures including DCGAN, StyleGAN and BigGAN, as well as some real-world examples.
By Kailash Ahirwar.

Credit: https://en.wikipedia.org/wiki/Edmond_de_Belamy
5 years back, Generative Adversarial Networks(GANs) started a revolution in deep learning. This revolution has produced some major technological breakthroughs. Generative Adversarial Networks were introduced by Ian Goodfellow and others in the paper titled “Generative Adversarial Networks” — https://arxiv.org/abs/1406.2661. Academia accepted GANs with open hands and industry welcomed GANs with much fanfare too. The rise of GANs was inevitable.
First, the best thing about GANs is their nature of learning, which is unsupervised. GANs don’t need labeled data, which makes GANs powerful as the boring work of data labeling is not required.
Second, the potential use-cases of GANs have put GANs at the center of conversations. They can generate high-quality images, enhance photos, generate images from text, convert images from one domain to another, change the appearance of the face image as age progresses and many more. The list is endless. We will cover some of the widely popular GAN architectures in this article.
Third, the endless research put around GANs is so mesmerizing that it grabs the attention of every other industry. We will be talking about major technological breakthroughs in the later section of this article.
The Birth
Generative Adversarial Network or GAN for short is a setup of two networks, a generator network, and a discriminator network. These two networks can be neural networks, ranging from convolutional neural networks, recurrent neural networks to auto-encoders. In this setup, two networks are engaged in a competitive game and trying to outdo each other, simultaneously, helping each other at their own tasks. After thousands of iterations, if everything goes well, the generator network gets perfect at generating realistically looking fake images and the discriminator network gets perfect at telling whether the image shown to it is fake or real. In other terms, the generator network transforms a random noise vector from a latent space(Not all GANs sample from a latent space) to a sample from real data set. Training a GAN is a very intuitive process. We simultaneously train both networks and they both get better with time.
GANs have plenty of real-world use cases like image generation, artwork generation, music generation, and video generation. Also, they can enhance the quality of your images, stylize or colorize your images, generate faces and can perform many more interesting tasks.
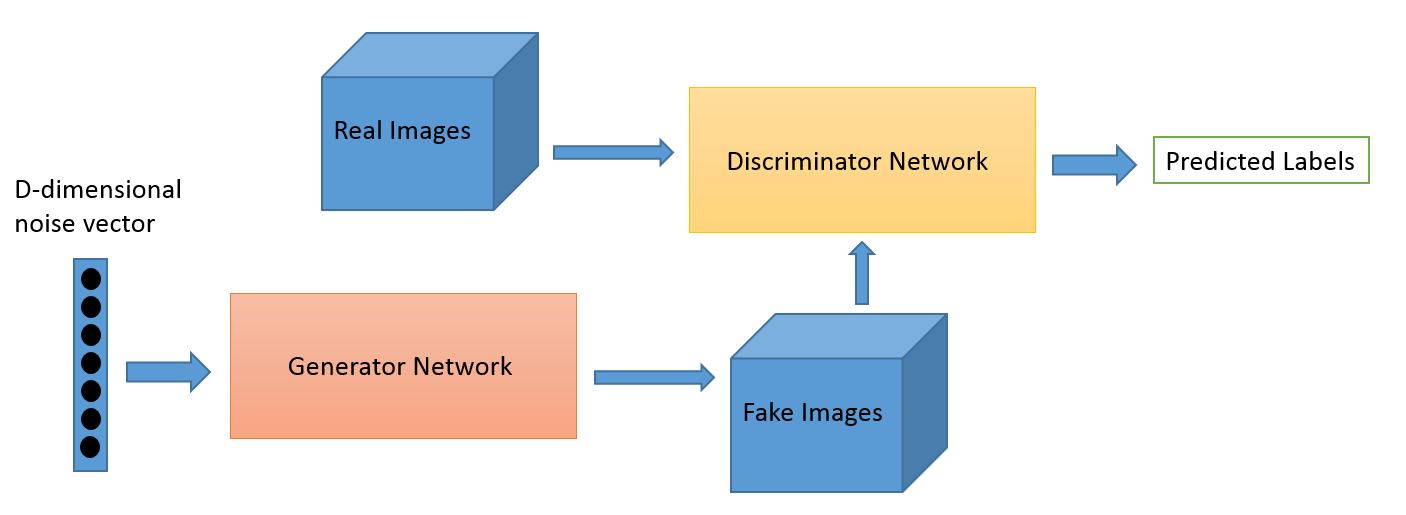
Credit: O’Reilly
The above image shows the architecture of a vanilla GAN network. First, a D-dimensional noise vector is sampled from a latent space and fed to the generator network. The generator network converts this noise vector to an image. Then this generated image is fed to the discriminator network for classification. The discriminator network keeps getting images from the real dataset and the images generated by the generator network. Its job is to discriminate between real and fake images. All GAN architectures follow the same design. This was the birth of GANs. Now explore the adolescent stage of GANs.
The Adolescence
In its adolescence, GANs produced widely popular architectures like DCGAN, StyleGAN, BigGAN, StackGAN, Pix2pix, Age-cGAN, CycleGAN. These architectures were presented with very promising results. By looking at the results, it was pretty clear that the GANs have reached in its adolescent stage. Let’s explore these architectures in detail.
DCGAN
For the first time, convolutional neural networks were used within GANs and achieved impressive results. Before this, CNNs have shown unprecedented results in supervised computer vision tasks. But in GANs, CNNs were unexplored. DCGANs were introduced in the paper titled “Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks” by Alec Radford, Luke Metz, Soumith Chintala. It was a major milestone in GANs research as it introduced major architectural changes to tackle problems like training instability, mode collapse, and internal covariate shift. Since then, numerous GAN architectures were introduced based on the architecture of DCGAN.

Source: https://arxiv.org/pdf/1511.06434.pdf
BigGAN
This is the latest development in GANs for image generation. A Google intern and two researchers from Google’s DeepMind division released a paper titled “Large Scale GAN Training for High Fidelity Natural Image Synthesis”, available at https://arxiv.org/abs/1809.11096. This paper is an internship project by Andrew Brock from Heriot-Watt University in collaboration with Jeff Donahue and Karen Simonyan from DeepMind.

Source: https://arxiv.org/pdf/1809.11096.pdf
These images are generated by BigGAN and as you see they are of impressive quality. For the first time, GANs have generated images with high fidelity and low variety gap. Previous highest Inception Score was 52.52 and BigGAN achieved an Inception Score of 166.3, which was 100% better than the State of the art(SOTA). Also, they improved The Frechet Inception Distance (FID) score from 18.65 to 9.6. These were very impressive results and I hope to see more development in this area. The most important improvement was orthogonal regularization to the generator.

Source: https://arxiv.org/pdf/1809.11096.pdf
Isn’t it impressive!
StyleGAN
StyleGAN is another major breakthrough in GANs research. StyleGAN was introduced by Nvidia, in the paper titled “A Style-Based Generator Architecture for Generative Adversarial Network”, available at the following link https://arxiv.org/pdf/1710.10196.pdf.

Source: https://medium.com/syncedreview/gan-2-0-nvidias-hyperrealistic-face-generator-e3439d33ebaf
StyleGAN sets a new record in Face generation tasks. At the core of the algorithm is the style transfer techniques or style mixing. Apart from generating faces, it can generate high-quality images of cars, bedrooms etc. This is a major improvement in the GANs field and an inspiration for fellow deep learning researchers.
StackGAN
StackGANs were proposed by Han Zhang, Tao Xu, Hongsheng Li, and others in their paper titled StackGAN: Text to Photo-Realistic Image Synthesis with Stacked Generative Adversarial Networks, which is available at the following link: https://arxiv.org/pdf/1612.03242.pdf. They used StackGANs to explore text-to-image synthesis with impressive results. A StackGAN is a pair of networks that generate realistic looking images when provided with a text description. My book titled “Generative Adversarial Networks Projects” has a chapter dedicated to StackGANs.

Source: https://arxiv.org/pdf/1612.03242.pdf
As you can see in the above image, StackGAN generated realistically looking images of birds when provided with a text description. The most important thing is that the generated images correctly resembles the text provided. Text-to-image synthesis has many real-world applications like generating images from text descriptions, converting a story in textual form to comic form, to create internal representations of text descriptions.
CycleGAN
CycleGANs have some really interesting use-cases, such as converting photos to paintings and vice versa, converting a picture taken in summer to a photo taken in winter and vice versa, or converting pictures of horses to pictures of zebras and vice versa. CycleGANs were proposed by Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A. Efros in a paper titled “Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks”, which is available at the following link: https://arxiv.org/pdf/1703.10593. CycleGANs explore different image-to-image translation use-cases.

Source: https://arxiv.org/pdf/1703.10593.pdf
Pix2pix
For image-to-image translation tasks, pix2pix also shown impressive results. Be it converting night images to day images or vice versa, colorizing black and white images, translating sketches to photos and many more, Pix2pix has excelled in all these use-cases. The pix2pix network was introduced by Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros in their paper titled “Image-to-Image Translation with Conditional Adversarial Networks”, which is available at the following link: https://arxiv.org/abs/1611.07004.
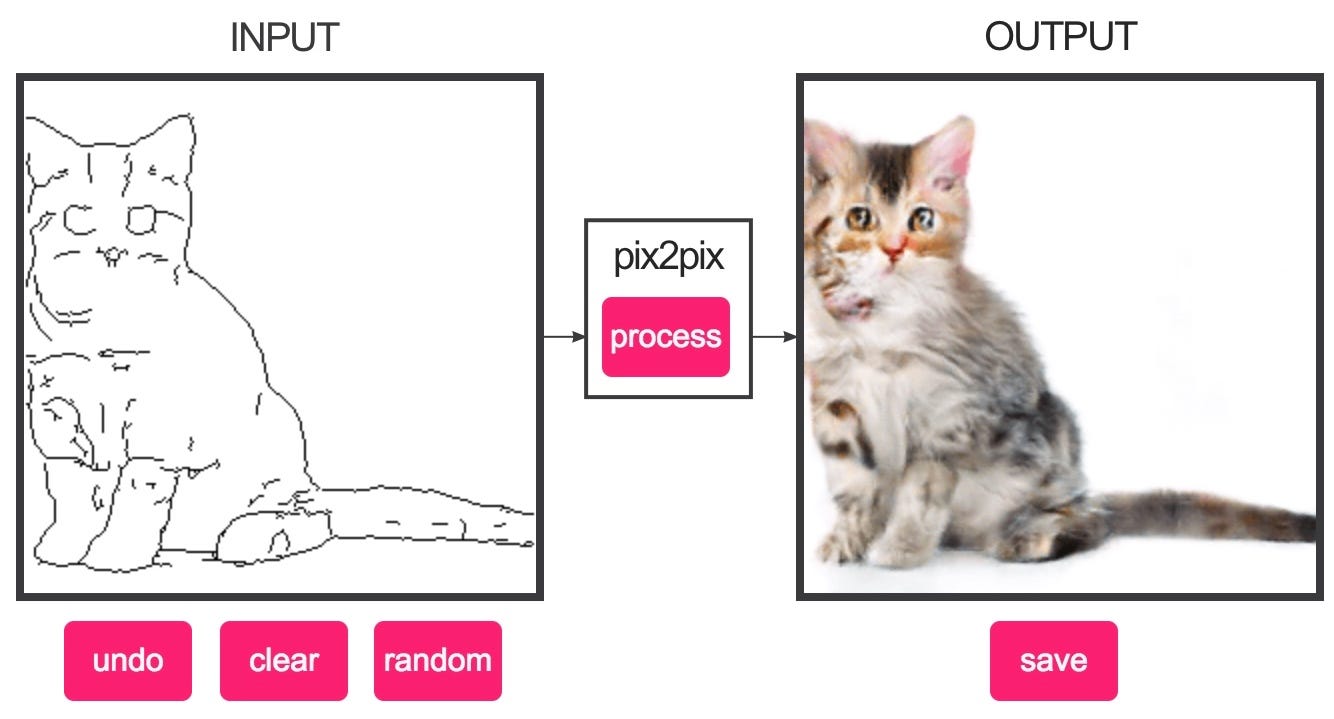
Credit: https://phillipi.github.io/pix2pix/
This was an interactive demo, capable of generating real images from sketches.
Age-cGAN (Age Conditional Generative Adversarial Networks)
Face aging has many industry use cases, including cross-age face recognition, finding lost children, and in entertainment. Face aging with Conditional GANs was proposed by Grigory Antipov, Moez Baccouche, and Jean-Luc Dugelay in their paper titled Face Aging with Conditional Generative Adversarial Networks, which is available at the following link: https://arxiv.org/pdf/1702.01983.pdf.

This image shows how Age-cGAN translated face from the source age to the target age.
These were some widely popular GAN architectures. Besides these, there are thousands of GAN architectures. It depends on your requirements which architecture will suit your need.
The Rise
As Famous Theoretical Physicist Richard Feynman says:
“What I can’t create, I don’t understand”
The idea behind GANs was to train networks which understand the data. GANs now started to understand the data, with this understanding they started to create realistic looking images. Let’s witness the rise of GANs.
Edmond de Belamy
Edmond de Belamy, a painting created by Generative Adversarial Networks was sold for a staggering amount of $432, 500 at Christie’s auction. It was a big step in the progress of GANs. For the first time, the whole world witnessed GANs and their potential. Before this, GANs were mostly confined in research labs and used by machine learning engineers. This act became an entry of GANs to the general public.

This Person Does Not Exist
You may be familiar with the website https://thispersondoesnotexist.com. Last month, this was all over the Internet. The website, https://thispersondoesnotexist.com created by Philip Wan, who is a software engineer at Uber. He created this website based on the code released by NVIDIA titled StyleGAN. Every time you hit refresh, it generates a new fake face, which looks surprisingly real unable to tell whether it is fake or not. This is scary AF but disruptive at the same time. This technology has the potential to create endless virtual worlds.

Source: https://thispersondoesnotexist.com/
Isn’t it amazing!
Deep Fakes
DeepFakes is another scary AF but disruptive technology. Based on GANs, this can paste people’s faces onto a target person in videos. DeepFakes was all over the Internet too. People speculated the downsides of this technology. But for AI researchers, this was a major breakthrough. This technology has the potential to save millions of dollars in the film industry where hours of editing required to change stuntman’s face with actors face.
This technology will always be scary, but it is up to us to use it for social good.

The Trend
StyleGAN currently is the sixth most trending python project on GitHub. The number of named GANs till now proposed are in thousands. This repository has a list of popular GANs and their respective papers https://github.com/hindupuravinash/the-gan-zoo
In Real-world
GANs have been used to enhance the graphics of games. I am super excited about this use-case of GANs. Recently, NVIDIA released a video, in which, it showed how GANs are used to gamify the environment in the video.
Conclusion
In this article, we have seen how GANs rose to fame and became a global phenomenon. I hope, we see the democratization of GANs in the coming years. In this article, we started with the birth of GANs. Then, we explored some widely popular GAN architectures. Finally, we witnessed the rise of GANs. When I see negative press around GANs, I am baffled. I believe, it is our responsibility to make everyone aware of the repercussions of GANs and how can we ethically and morally use GANs for our best. Let’s all come together and spread positivity around GANs. GANs have so much potential to create new industries and jobs. We just have to make sure that it doesn’t go into wrong hands.
Original. Reposted with permission.
Bio: Kailash Ahirwar is a Machine Learning and Deep Learning Enthusiast, Democratising Machine Learning and Deep Learning, making it available for one and all.
Resources:
- On-line and web-based: Analytics, Data Mining, Data Science, Machine Learning education
- Software for Analytics, Data Science, Data Mining, and Machine Learning
Related:
- Which Face is Real?
- My favorite mind-blowing Machine Learning/AI breakthroughs
- State of Deep Learning and Major Advances: H2 2018 Review