 Spark NLP: Getting Started With The World’s Most Widely Used NLP Library In The Enterprise
Spark NLP: Getting Started With The World’s Most Widely Used NLP Library In The Enterprise
 Spark NLP: Getting Started With The World’s Most Widely Used NLP Library In The Enterprise
Spark NLP: Getting Started With The World’s Most Widely Used NLP Library In The EnterpriseThe Spark NLP library has become a popular AI framework that delivers speed and scalability to your projects. Check out what's under the hood and learn about how to getting started leveraging Spark NLP from John Snow Labs.
By David Talby, CTO, Pacific AI
AI Adoption in the Enterprise
The annual O’Reilly report on AI Adoption in the Enterprise was released in February 2019. It is a survey of 1,300 practitioners in multiple industry verticals, which asked respondents about revenue-bearing AI projects their organizations have in production. It’s a fantastic analysis of how AI is really used by companies today – and how that use is quickly expanding into deep learning, human-in-the-loop, knowledge graphs, and reinforcement learning.
The survey asks respondents to list all the ML or AI frameworks and tools that they use. This is the summary of the answers:
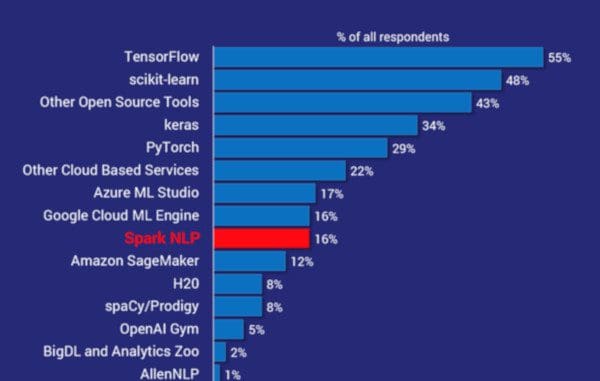
The 18-month-old Spark NLP library is the 7th most popular across all AI frameworks and tools (note the “other open source tools” and “other cloud services” buckets). It is also by far the most widely used NLP library – twice as common as spaCy. In fact, it is the most popular AI library in this survey following scikit-learn, TensorFlow, Keras, and PyTorch.
State-of-the-art Accuracy, Speed, and Scalability
This survey is in line with the uptick in adoption we’ve experienced in the past year, and the public case studies on using Spark NLP successfully in healthcare, finance, life science, and recruiting. The root causes for this rapid adoption lie in the major shift in state-of-the-art NLP that happened in recent years.
ACCURACY
The rise of deep learning for natural language processing in the past 3-5 years meant that the algorithms implemented in popular libraries, like spaCy, Stanford CoreNLP, nltk, and OpenNLP, are less accurate than what the latest scientific papers made possible.
Claiming to deliver state-of-the-art accuracy and speed has us constantly on the hunt to productize the latest scientific advances (yes, it is as fun as it sounds!). Here’s how we’re doing so far (on the en_core_web_lg benchmark, micro-averaged F1 score):
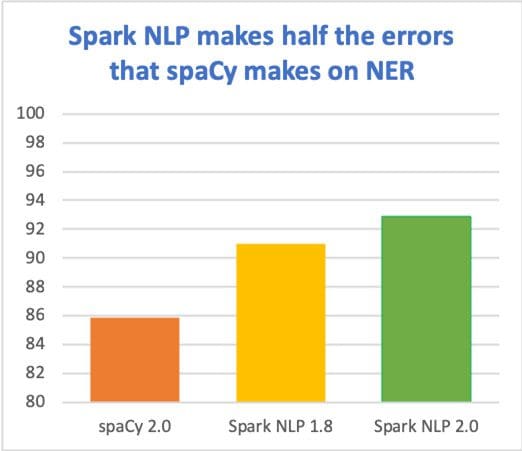
SPEED
Optimizations done to get Apache Spark’s performance closer to bare metal, on both a single machine and cluster, meant that common NLP pipelines could run orders of magnitude faster than what the inherent design limitations of legacy libraries allowed.
The most comprehensive benchmark to date, Comparing production-grade NLP libraries, was published a year ago on O’Reilly Radar. On the left is the comparison of runtimes for training a simple pipeline (sentence boundary detection, tokenization, and part of speech tagging) on a single Intel i5, 4-core, 16 GB memory machine:
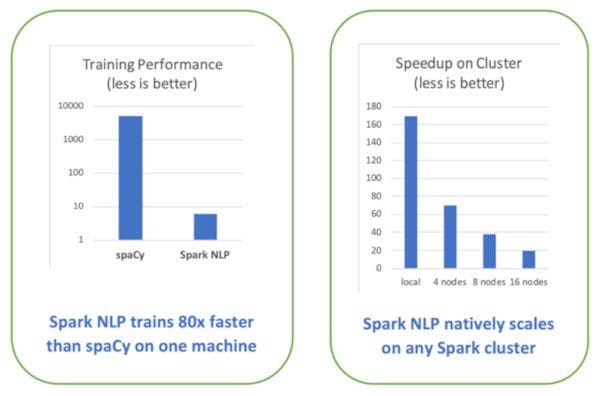
Being able to leverage GPU’s for training and inference has become table stakes. Using TensorFlow under the hood for deep learning enables Spark NLP to make the most of modern computer platforms – from nVidia’s DGX-1 to Intel’s Cascade Lake processors. Older libraries, whether or not they use some deep learning techniques, will require a rewrite to take advantage of these new hardware innovations that can add improvements to the speed and scale of your NLP pipelines by another order of magnitude.
SCALABILITY
Being able to scale model training, inference, and full AI pipelines from a local machine to a cluster with little or no code changes has also become table stakes. Being natively built on Apache Spark ML enables Spark NLP to scale on any Spark cluster, on-premise or in any cloud provider. Speedups are optimized thanks to Spark’s distributed execution planning and caching, which has been tested on just about any current storage and compute platform.
Other Drivers of Enterprise Adoption
PRODUCTION-GRADE CODEBASE
We make our living delivering working software to enterprises. This was our primary goal in contrast to research-oriented libraries like AllenNLP and NLP Architect.
PERMISSIVE OPEN SOURCE LICENSE
Sticking with an Apache 2.0 license was selected so that the library can be used freely, including in a commercial setting. This is in contrast to Stanford CoreNLP, which requires a paid license for commercial use, or the problematic ShareAlike CC licenses used for some spaCy models.
FULL PYTHON, JAVA, AND SCALA API’S
Supporting multiple programming languages does not just increase the audience for a library. It also enables you to take advantage of the implemented models without having to move data back and forth between runtime environments. For example, using spaCy, which is Python-only, requires moving data from JVM processes to Python processes in order to call it – resulting in architectures that are more complex and often much slower than necessary.
FREQUENT RELEASES
Spark NLP is under active development by a full core team in addition to community contributions. We release about twice a month – there were 26 new releases in 2018. We welcome contributions of code, documentation, models or issues – please start by looking at the existing issues on GitHub.
Getting Started
PYTHON
A major design goal of Spark NLP 2.0 was to enable people to get the benefits of Spark and TensorFlow without knowing anything about them. You shouldn’t have to know what a Spark ML estimator or transformer is, or what a TensorFlow graph or session is. These are all still available if you’re looking to build your own custom models or graphs, but they are now fronted by facades that get stuff done with minimal time and learning curve. We’ve also added 15 pre-trained pipelines and models that cover the most common use cases.
Installing Spark NLP for Python requires a one-line pip install or conda install. This installation page contains more detail about Jupyter and Databricks configurations. Live projects routines use the library also on Zeppelin, SageMaker, Azure, GCP, Cloudera, and vanilla Spark – inside and outside Kubernetes.
Once installed, here is what it takes to run sentiment analysis:
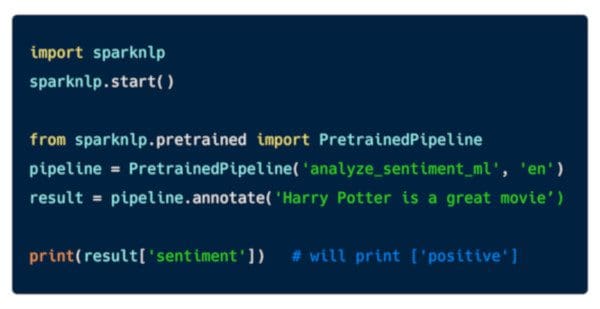
Here is all it takes to run named entity recognition with BERT embeddings:
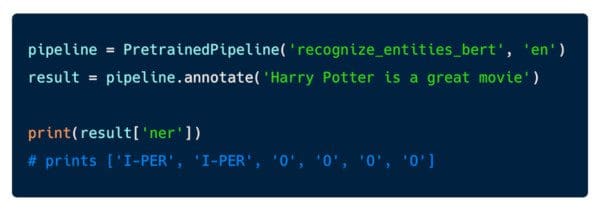
The pipeline object in these examples has two key methods – annotate(), which takes a string, and transform(), which takes a Spark data frame. These enable you to scale this code to process a large body of text on any Spark cluster.
SCALA
Spark NLP is written in Scala, required for it to operate directly on Spark data frames, with zero copying of data and while taking full advantage of the Spark execution planner and other optimizations. As a result, the library is a breeze to use for Scala and Java developers.
The library is published on Maven Center, so just adding the dependency in your Maven or SBT file is all it takes to install it. There’s a second dependency to add if you also want to install Spark NLP’s OCR (object character recognition) capabilities.
Once installed, here is what it takes to spell check a sentence:

The Scala and Python API’s are kept similar and 100% complete in every release.
UNDER THE HOOD
There’s a lot that goes behind the scenes in the few lines of codes shared above – and a lot that you can customize for your other applications. Spark NLP is heavily optimized towards training domain-specific NLP models – see for example the Spark NLP for Healthcare commercial extension – so all the tools for defining your pre-trained models, pipelines, and resources are in the public and documented APIs.
Here are the main steps taken by the named entity recognition with BERT Python code from the previous section:
- sparknlp.start() starts a new Spark session if there isn’t one, and returns it.
- PretrainedPipeline() loads the English language version of the explain_document_dl pipeline, the pre-trained models, and the embeddings it depends on.
- These are stored and cached locally.
- TensorFlow is initialized, within the same JVM process that runs Spark. The pre-trained embeddings and deep-learning models (like NER) are loaded. Models are automatically distributed and shared if running on a cluster.
- The annotate() call runs an NLP inference pipeline which activates each stage’s algorithm (tokenization, POS, etc.).
- The NER stage is run on TensorFlow – applying a neural network with bi-LSTM layers for tokens and a CNN for characters.
- Embeddings are used to convert contextual tokens into vectors during the NER inference process.
- The result object is a plain old local Python dictionary.
GIVE IT A GO!
The Spark NLP homepage has examples, documentation, and an installation guide.
If you’re looking to explore sample notebooks on your own, the Spark NLP Workshop has a pre-built Docker container that enables you to run a complete environment on your local machine by typing 3 one-liners.
Got questions? Us and the rest of the community are on the Spark NLP Slack channel every day to help you succeed.
Bio: David Talby is a chief technology officer at Pacific AI with extensive experience in building and operating web-scale data science and business platforms, as well as building world-class, Agile, distributed teams. Previously, he was with Microsoft’s Bing Group, where he led business operations for Bing Shopping in the US and Europe, and worked at Amazon both in Seattle and the UK, where he built and ran distributed teams that helped scale Amazon’s financial systems. David holds a PhD in computer science and Master’s degrees in both computer science and business administration.
Related: