A 2019 Guide to Semantic Segmentation
Semantic segmentation refers to the process of linking each pixel in an image to a class label. These labels could include a person, car, flower, piece of furniture, etc., just to mention a few. We’ll now look at a number of research papers on covering state-of-the-art approaches to building semantic segmentation models.

Semantic segmentation refers to the process of linking each pixel in an image to a class label. These labels could include a person, car, flower, piece of furniture, etc., just to mention a few.
We can think of semantic segmentation as image classification at a pixel level. For example, in an image that has many cars, segmentation will label all the objects as car objects. However, a separate class of models known as instance segmentation is able to label the separate instances where an object appears in an image. This kind of segmentation can be very useful in applications that are used to count the number of objects, such as counting the amount of foot traffic in a mall.
Some of its primary applications are in autonomous vehicles, human-computer interaction, robotics, and photo editing/creativity tools. For example, semantic segmentation is very crucial in self-driving cars and robotics because it is important for the models to understand the context in the environment in which they’re operating.
We’ll now look at a number of research papers on covering state-of-the-art approaches to building semantic segmentation models, namely:
- Weakly- and Semi-Supervised Learning of a Deep Convolutional Network for Semantic Image Segmentation
- Fully Convolutional Networks for Semantic Segmentation
- U-Net: Convolutional Networks for Biomedical Image Segmentation
- The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation
- Multi-Scale Context Aggregation by Dilated Convolutions
- DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
- Rethinking Atrous Convolution for Semantic Image Segmentation
- Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
- FastFCN: Rethinking Dilated Convolution in the Backbone for Semantic Segmentation
- Improving Semantic Segmentation via Video Propagation and Label Relaxation
- Gated-SCNN: Gated Shape CNNs for Semantic Segmentation
Passionate about machine learning? Same! We’re curating each week’s biggest stories, best tutorials, and latest research so you don’t have to. Sign up for weekly updates delivered to your inbox.
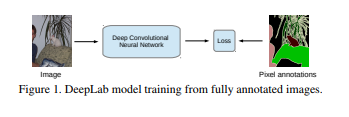
Weakly- and Semi-Supervised Learning of a Deep Convolutional Network for Semantic Image Segmentation (ICCV, 2015)
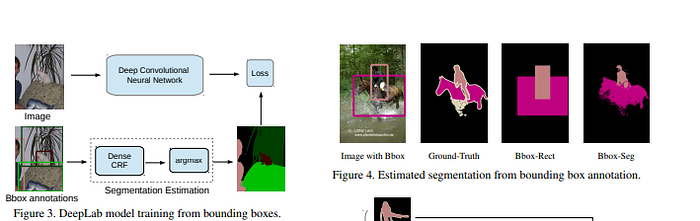
This paper proposes a solution to the challenge of dealing with weakly-labeled data in deep convolutional neural networks (CNNs), as well as a combination of data that’s well-labeled and data that’s not properly labeled.
In the paper, a combination of deep CNNs with a fully-connected conditional random field is applied.
Weakly- and Semi-Supervised Learning of a DCNN for Semantic Image Segmentation
Deep convolutional neural networks (DCNNs) trained on a large number of images with strong pixel-level annotations have...
On the PASCAL VOC segmentation benchmark, this model gives a mean intersection-over-union (IOU) score above 70%. One of the major challenges faced with this kind of model is that it requires images that are annotated at the pixel level during training.
The main contributions of this paper are:
- Introduction of Expectation-Maximization algorithms for bounding box or image-level training that can be applied to both weakly-supervised and semi-supervised settings.
- Proves that combining weak and strong annotations improves performance. The writers of this paper reach 73.9% IOU performance on PASCAL VOC 2012 after merging annotations from the MS-COCO datasets and PASCAL datasets.
- Proves that their approach achieves higher performance by merging a small number of pixel-level annotated images and a large number of bounding-box or image-level annotated images.
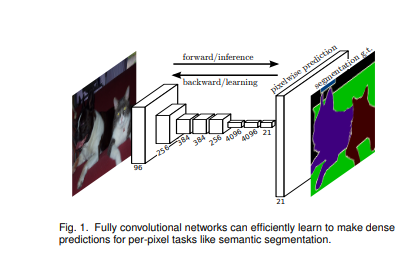
Fully Convolutional Networks for Semantic Segmentation (PAMI, 2016)
The model proposed in this paper achieves a performance of 67.2% mean IU on PASCAL VOC 2012.
Fully Convolutional Networks for Semantic Segmentation
Convolutional networks are powerful visual models that yield hierarchies of features. We show that convolutional...
Fully-connected networks take an image of any size and generate an output of the corresponding spatial dimensions. In this model, ILSVRC classifiersare cast into fully-connected networks and augmented for dense prediction using pixel-wise loss and in-network up-sampling. Training for segmentation is then done by fine-tuning. Fine-tuning is done by back-propagation on the entire network.
U-Net: Convolutional Networks for Biomedical Image Segmentation (MICCAI, 2015)
In biomedical image processing, it’s very crucial to get a class label for every cell in the image. The biggest challenge in biomedical tasks is that thousands of images for training are not easily accessible.
U-Net: Convolutional Networks for Biomedical Image Segmentation
There is large consent that successful training of deep networks requires many thousand annotated training samples. In...
This paper builds upon the fully convolutional layer and modifies it to work on a few training images and yield more precise segmentation.
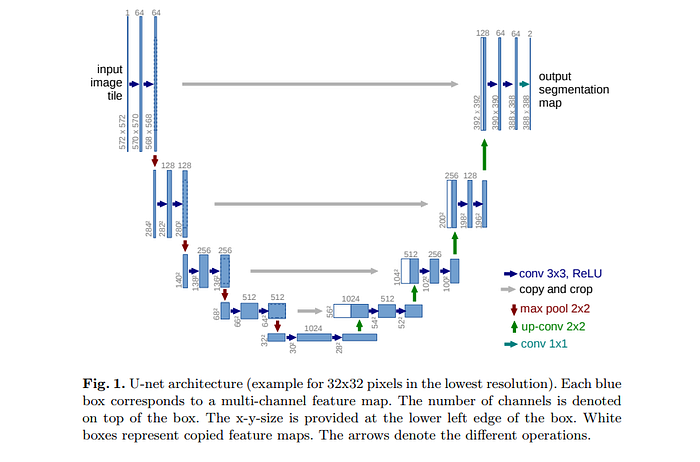
Since very little training data is available, this model uses data augmentation by applying elastic deformations on the available data. As illustrated in figure 1 above, the network architecture is made up of a contracting path on the left and an expansive path on the right.
The contracting path is made up of two 3x3 convolutions. Each of the convolutions is followed by a rectified linear unit and a 2x2 max pooling operation for downsampling. Every downsampling stage doubles the number of feature channels. The expansive path steps include an upsampling of the feature channels. This is followed by 2x2 up-convolution that halves the number of feature channels. The final layer is a 1x1 convolution that is used to map the component feature vectors to the required number of classes.
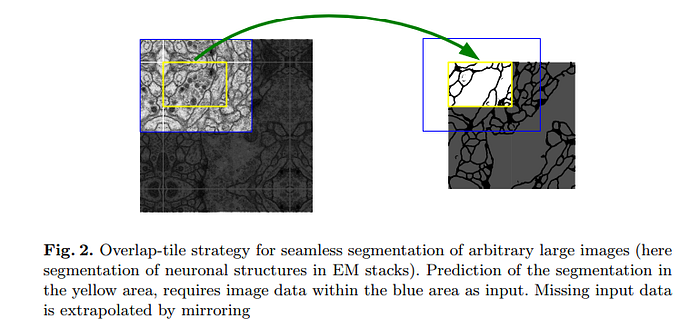
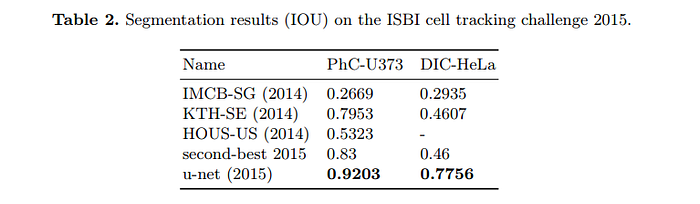
In this model, training is done using the input images, their segmentation maps, and a stochastic gradient descent implementation of Caffe. Data augmentation is used to teach the network the required robustness and invariance when very little training data is used. This model achieved a mean intersection-over-union (IOU) score of 92% on one of the experiments.
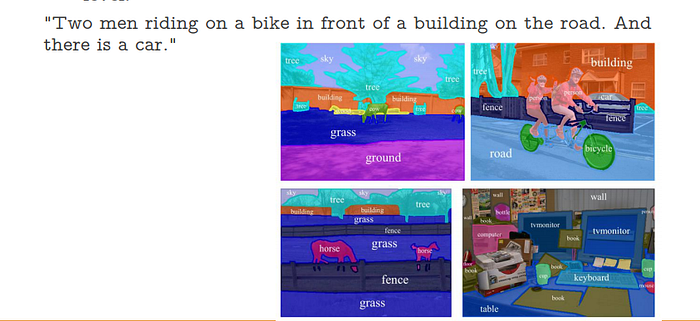
The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation (2017)
The idea behind DenseNets is that having each layer connected to every layer in a feed-forward manner makes the network easier to train and more accurate.
The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation
State-of-the-art approaches for semantic image segmentation are built on Convolutional Neural Networks (CNNs). The...
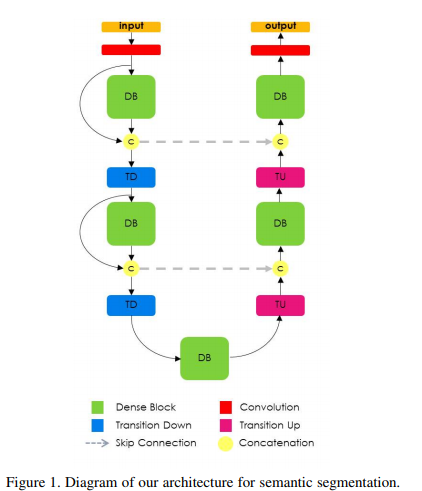
The model’s architecture is built in dense blocks of downsampling and upsampling paths. The downsampling path has 2 Transitions Down (TD) while the upsampling path has 2 Transitions Up (TU). The circle and arrows represent connectivity patterns within the network.
The main contributions of this paper are:
- Extends the DenseNet architecture to fully convolutional networks for use in semantic segmentation.
- Proposes upsampling paths from dense networks that perform better than other upsampling paths.
- Proves that the network can produce state-of-the-art results on standard benchmarks.
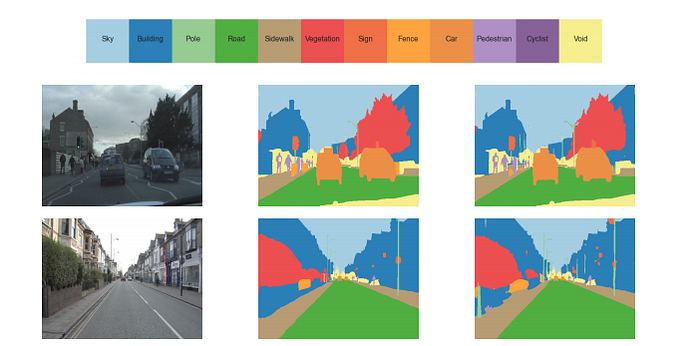
This model achieves a global accuracy of 88% on the CamVid dataset.