6 Tips for Building a Training Data Strategy for Machine Learning
Without a well-defined approach for collecting and structuring training data, launching an AI initiative becomes an uphill battle. These six recommendations will help you craft a successful strategy.
By Wilson Pang, CTO, Appen.
Artificial intelligence (AI) and machine learning (ML) are frequently used terms these days. AI refers to the concept of machines mimicking human cognition. ML is an approach used to create AI. If AI is when a computer can carry out a set of tasks based on instruction, ML is a machine’s ability to ingest, parse, and learn from that data itself in order to become more accurate or precise about accomplishing that task.
Executives in industries such as automotive, finance, government, healthcare, retail, and tech may already have a basic understanding of ML and AI. However, not everyone is an expert in developing a training data strategy, a necessary first step for realizing a high return on machine learning investments.
AI systems learn by example, and the more, high-quality examples they have, the better they’ll learn. Insufficient or low-quality training data can result in unreliable systems that reach the wrong conclusions, makes poor decisions, can’t handle real-world variation, and introduce or perpetuate bias, among other problems. Poor data is also expensive. IBM estimated that poor data quality in the United States costs the country’s economy roughly $3.1 trillion per year.
Without a well-defined strategy for collecting and structuring the data you need to train, test, and tune AI systems, you run the risk of delayed projects, not being able to scale appropriately, and competitors outpacing you. Below are six tips for building a successful training data strategy.
1: Establish a Budget for Training Data
When launching a new machine learning project, the first thing to define is the objective you’re trying to achieve. That will tell you what type of data you need and how many “training items” — data points that have been categorized — you’ll need to train your system.
For example, training items for a computer vision or pattern recognition project would be image data that has been labeled by human annotators to identify the contents (trees, stop signs, people, cars, etc.) of the image. Furthermore, depending on what kind of solution you’re building, your model may need to be continuously retrained or refreshed. Your solution might require quarterly, monthly, or even weekly updates.
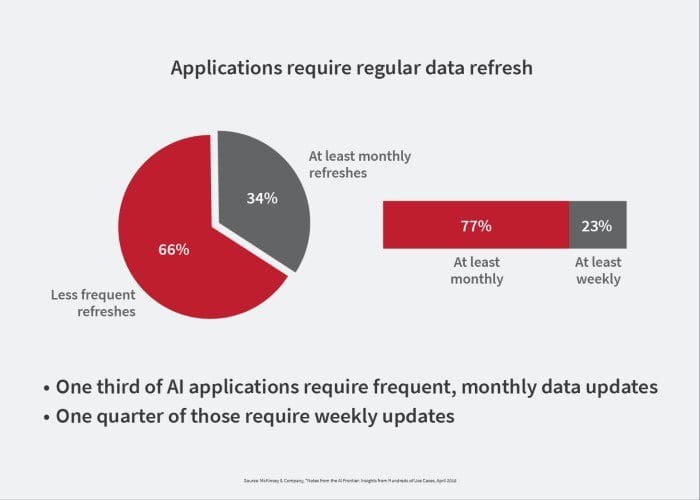
Once the training items and refresh rates have been determined, you can then evaluate your options for sourcing data, and calculate a budget.
It’s important to be clear-eyed about the time and money investment required to get the initiative off the ground, maintain it over time, and evolve the features and functionality — along with your business — so the solution stays relevant and useful to your customers. Starting a machine learning program is a long-term investment. Getting a great return requires a long-term strategy.
2: Source Appropriate Data
The type of data you’ll need depends on the kind of solution you’re building. Some data sourcing options include real-world usage data, survey data, public datasets, and synthetic data. For example, a speech recognition solution that understands spoken human commands must be trained on high-quality speech data (real-world data) that has been translated into text. A search solution needs text data annotated by human judges to tell it which results are the most relevant.
The most common types of data used in machine learning are image, video, speech, audio, and text. Before they’re used for machine learning, training data items must be annotated or labeled, to identify what they are. Annotation tells a model what to do with each piece of data. For example, if a data item for a virtual home assistant is the recording of someone saying “Order more double-A batteries,” the annotation might tell the system to start an order with a particular online retailer when it hears “order,” and to search on “AA batteries” when it hears “double-A batteries.”
3: Ensure Data Quality
Depending on the task, data annotation can be a relatively simple activity — but it’s also repetitive, time-consuming, and difficult to do right consistently. It requires a human touch.
The stakes are high because if you train a model on inaccurate data, the model will do the wrong thing. For example, if you train a computer vision system for autonomous vehicles with images of sidewalks mislabeled as streets, the results could be disastrous. Indeed, “poor data quality is enemy number one to the widespread, profitable use of machine learning.”
When we talk about quality here, we’re talking about both the accuracy and consistency of those labels. Accuracy is how close a label is to the truth. Consistency is the degree to which multiple annotations on various training items agree with one another.
4: Be Aware of and Mitigate Data Biases
Emphasizing data quality helps companies mitigate bias in their AI projects, which can be hidden until your AI-based solution reaches the market. At that point, the bias can be difficult to fix.
Bias generally comes from blind spots or unconscious preferences in the project team or training data, from the outset of a project. Bias in AI can manifest as uneven voice or facial recognition performance for different genders, accents, or ethnicities. As AI becomes more prevalent in our culture, now is the time to address built-in bias.
To avoid bias at the project level, actively build diversity into the teams defining your goals, roadmaps, metrics, and algorithms. Hiring a diverse team of data talent is easier said than done, but the stakes are high. If the internal makeup of your team doesn’t represent the external makeup of potential customers, then the end product risks only working for, or appealing to, a subset of people, and missing a mass-market opportunity or worse: bias might lead to real-world discrimination.
5: When Necessary, Implement Data Security Safeguards
Not every data project uses personally identifiable information (PII) or sensitive data. For solutions that do leverage that type of information, data security is more important than ever, especially when you’re working with the PII of your customers, financial or government records, or user-generated content. Increasingly, government regulations are dictating how companies must handle customer information.
Securing this confidential data protects your—and your customers’—information. Being transparent and ethical about your practices and sticking to your terms of service gives you a competitive advantage. Not doing so puts you at risk of scandal and negative impacts on your brand.
6: Select Appropriate Technology
The more intricate or nuanced your training data is, the better the outcome. Most organizations need large volumes of high-quality training data, fast and at scale. To achieve this, they must build a data pipeline that delivers sufficient volume at the speed needed to refresh their models. That’s why choosing the right data annotation technology is crucial.
The tool(s) you select must be able to handle the appropriate data types for your initiative, allow for flexible labeling workflow designs, manage individual annotator quality and throughput, and provide machine learning-assisted data labeling to augment human annotators’ performance.
Setting a Strategy Enables Successful AI
A recent study by IHS Markit revealed that 87% of organizations are adopting at least one form of transformative technology like AI, but only 26% believe that appropriate business models are in place to capture full value from these technologies.
Creating a solid training data strategy is the first step toward capturing the value of AI. That includes setting your budget, identifying your data sources, ensuring quality, and building in security. A clear data strategy can also help provide the steady pipeline of data that most machine learning models need for regular refreshes. A training data strategy alone won’t guarantee AI success, but it can help ensure companies are better positioned to leverage the benefits that AI offers.
Bio: Wilson Pang is an engineering and data science tech leader, and expert in big data, data science, distributed system engineering, search science, internet marketing and web applications. Wilson's passion is to drive business with data science and engineering innovation together with smart people having developed and growing talents.
Related: