Automate Hyperparameter Tuning for Your Models
When we create our machine learning models, a common task that falls on us is how to tune them. So that brings us to the quintessential question: Can we automate this process?

When we create our machine learning models, a common task that falls on us is how to tune them.
People end up taking different manual approaches. Some of them work, and some don’t, and a lot of time is spent in anticipation and running the code again and again.
So that brings us to the quintessential question: Can we automate this process?
A while back, I was working on an in-class competition from the “How to win a data science competition” Coursera course. Learned a lot of new things, one among them being Hyperopt — A bayesian Parameter Tuning Framework.
And I was amazed. I left my Mac with hyperopt in the night. And in the morning I had my results. It was awesome, and I did avoid a lot of hit and trial.
This post is about automating hyperparameter tuning because our time is more important than the machine.
So, What is Hyperopt?

From the Hyperopt site:
Hyperopt is a Python library for serial and parallel optimization over awkward search spaces, which may include real-valued, discrete, and conditional dimensions
In simple terms, this means that we get an optimizer that could minimize/maximize any function for us. For example, we can use this to minimize the log loss or maximize accuracy.
All of us know how grid search or random-grid search works.
A grid search goes through the parameters one by one, while a random search goes through the parameters randomly.
Hyperopt takes as an input space of hyperparameters in which it will search and moves according to the result of past trials.
Thus, Hyperopt aims to search the parameter space in an informed way.
I won’t go in the details. But if you want to know more about how it works, take a look at this paper by J Bergstra. Here is the documentation from Github.
Our Dataset
To explain how hyperopt works, I will be working on the heart dataset from UCI precisely because it is a simple dataset. And why not do some good using Data Science apart from just generating profits?
This dataset predicts the presence of a heart disease given some variables.
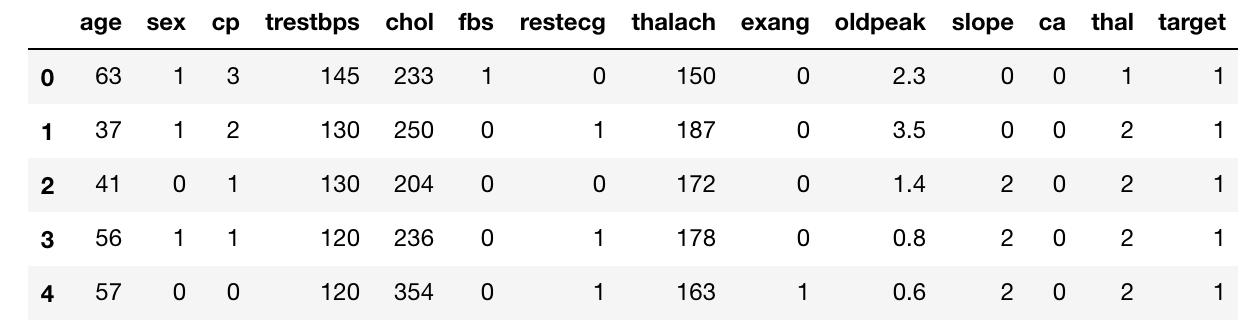
This is a snapshot of the dataset :
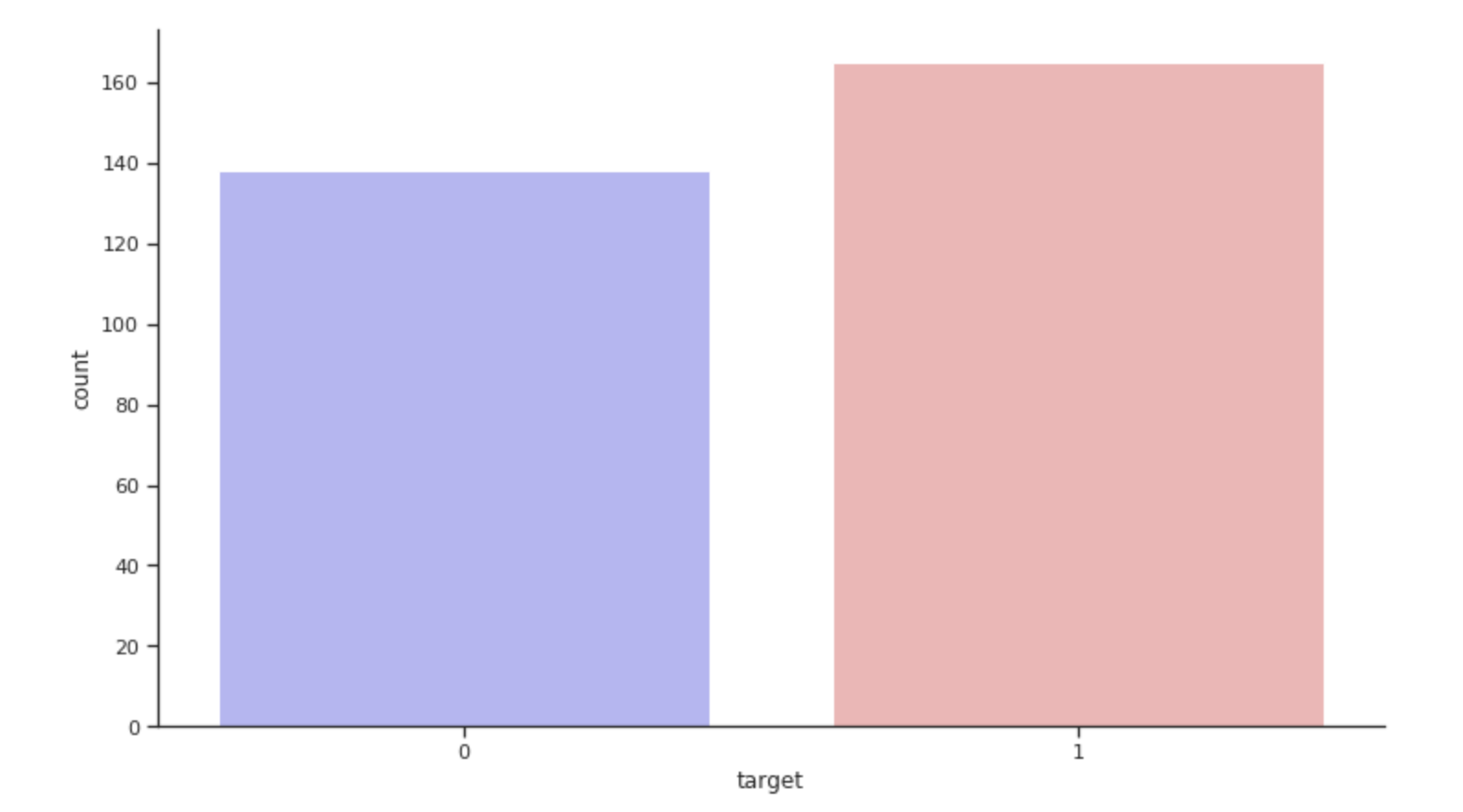
This is how the target distribution looks like:
Hyperopt Step by Step

So, while trying to run hyperopt, we will need to create two Python objects:
- An Objective function: The objective function takes the hyperparameter space as the input and returns the loss. Here we call our objective function
objective - A dictionary of hyperparams: We will define a hyperparam space by using the variable
spacewhich is actually just a dictionary. We could choose different distributions for different hyperparameter values.
In the end, we will use the fmin function from the hyperopt package to minimize our objective through the space.
You can follow along with the code in this Kaggle Kernel.
1. Create the objective function
Here we create an objective function which takes as input a hyperparameter space:
- We first define a classifier, in this case, XGBoost. Just try to see how we access the parameters from the space. For example
space[‘max_depth’] - We fit the classifier to the train data and then predict on the cross-validation set.
- We calculate the required metric we want to maximize or minimize.
- Since we only minimize using
fminin hyperopt, if we want to minimizeloglosswe just send our metric as is. If we want to maximize accuracy we will try to minimize-accuracy
2. Create the Space for your classifier

Now, we create the search space for hyperparameters for our classifier.
To do this, we end up using many of hyperopt built-in functions which define various distributions.
As you can see in the code below, we use uniform distribution between 0.7 and 1 for our subsample hyperparameter. We also give a label for the subsample parameterx_subsample. You need to provide different labels for each hyperparam you define. I generally add a x_ before my parameter name to create this label.
You can also define a lot of other distributions too. Some of the most useful stochastic expressions currently recognized by hyperopt’s optimization algorithms are:
hp.choice(label, options)— Returns one of the options, which should be a list or tuple.hp.randint(label, upper)— Returns a random integer in the range [0, upper).hp.uniform(label, low, high)— Returns a value uniformly betweenlowandhigh.hp.quniform(label, low, high, q)— Returns a value like round(uniform(low, high) / q) * qhp.normal(label, mu, sigma)— Returns a real value that’s normally-distributed with mean mu and standard deviation sigma.
There are a lot of other distributions. You can check them out here.
3. And finally, Run Hyperopt

Once we run this, we get the best parameters for our model. Turns out we achieved an accuracy of 90% by just doing this on the problem.
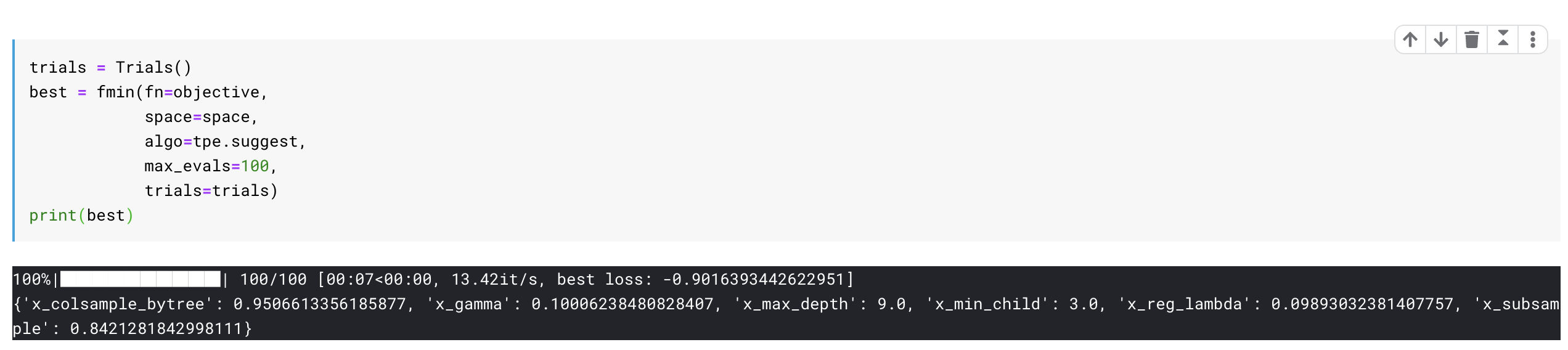
Now we can retrain our XGboost algorithm with these best params, and we are done.
Conclusion
Running the above gives us pretty good hyperparams for our learning algorithm. And that saves me a lot of time to think about various other hypotheses and testing them.
I tend to use this a lot while tuning my models. From my experience, the most crucial part in this whole procedure is setting up the hyperparameter space, and that comes by experience as well as knowledge about the models.
So, Hyperopt is an awesome tool to have in your repository but never neglect to understand what your models does. It will be very helpful in the long run.
You can get the full code in this Kaggle Kernel.
Continue Learning
If you want to learn more about practical data science, do take a look at the “How to win a data science competition” Coursera course. Learned a lot of new things from this course taught by one of the most prolific Kaggler.
Thanks for the read. I am going to be writing more beginner-friendly posts in the future too. Follow me up at Medium or Subscribe to my blog to be informed about them. As always, I welcome feedback and constructive criticism and can be reached on Twitter @mlwhiz.
Also, a small disclaimer - There might be some affiliate links in this post to relevant resources as sharing knowledge is never a bad idea.
Bio: Rahul Agarwal is a Data Scientist at Walmart Labs.
Original. Reposted with permission.
Related:
- How to Automate Hyperparameter Optimization
- Keras Hyperparameter Tuning in Google Colab Using Hyperas
- Automated Machine Learning: Just How Much?