Topics Extraction and Classification of Online Chats
This article provides covers how to automatically identify the topics within a corpus of textual data by using unsupervised topic modelling, and then apply a supervised classification algorithm to assign topic labels to each textual document by using the result of the previous step as target labels.
By Elena Pedrini, Data Science Engineer
The combination of unsupervised and supervised machine learning approaches can be a great solution when we want to classify unlabelled data, i.e. data for which we don’t have the information we want to classify for. This blog post goes through a possible solution to
- first, automatically identify the topics within a corpus of textual data by using unsupervised topic modelling,
- then, apply a supervised classification algorithm to assign topic labels to each textual document by using the result of the previous step as target labels.
This project has used the data of the Customer Relationship Management team of a Fintech company, specifically the online chats of their customers in UK and Italy.
Methodology

1. Gather online chat texts
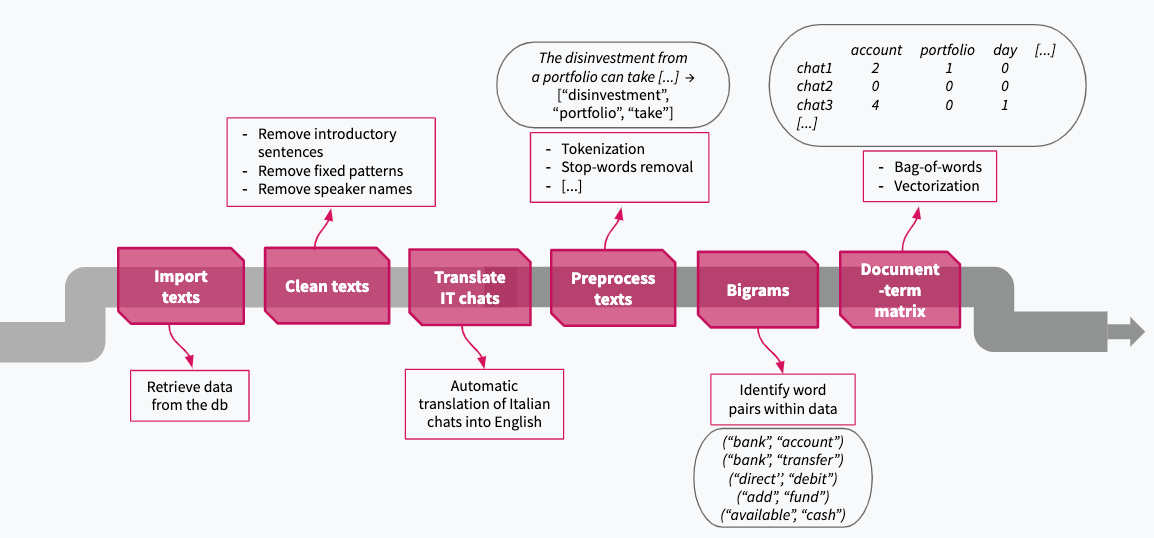
The first step is to retrieve the textual data and transform it into a compatible form for the model we want to use. In this case the usual NLP data preparation techniques have been applied, on top of other ad-hoc transformations for the specific nature of this dataset:
- remove the parts of the text repeated in every chat;
- apply automatic translation in order to have the whole corpus written in a single language, English in this case. Another option would be to keep the texts in their original language and then apply independent preprocessing pipelines and machine learning models for each language;
- preprocess the texts using tokenisation, lemmatisation, stop-words and digits removal;
- add n-grams to the dataset to guide the topic model. The assumption here is that short sequences of words treated as single entities, or tokens, usually contain useful information to identify the topics of a sentence. Only bigrams turned out to be meaningful in this context — indeed they significantly improved the topic model performance;
- use count vectorisation to transform the data into a numeric term-document matrix, having chat documents as rows, single tokens as columns and the corresponding frequencies as values (frequency of the selected token in the given chat). This so-called Bag-of-Words (BoW) approach does not take into account words order, which should not play a crucial role in the topics identification.
2. Extract topics
At this point the dataset is in the right shape for the Latent Dirichlet Allocation (LDA) model, the probabilistic topic model which has been implemented in this work. A document-term matrix is in fact the type of input which the model requires in order to infer probabilistic distributions on:
- a set of latent (i.e. unknown) topics across the documents;
- the words in the corpus vocabulary (the set of all words used in the dataset), by looking at the topics in the document in which the word is contained and the other topic assignments for that particular word across the corpus.

LDA outputs K topics (where K is given to the model as parameter) in the form of high-dimensional vectors where each component represents the weight for a particular word in the vocabulary. By looking at the terms with the highest weights it’s possible to manually give a name to the K topics, improving human interpretability of the output.

LDA also provides a topic distribution for each document in the dataset as a sparse vector (few components with high weights, all the rest with 0 weight), making it easier to interpret the high-dimensional topic vectors and extract the relevant topics for each text.

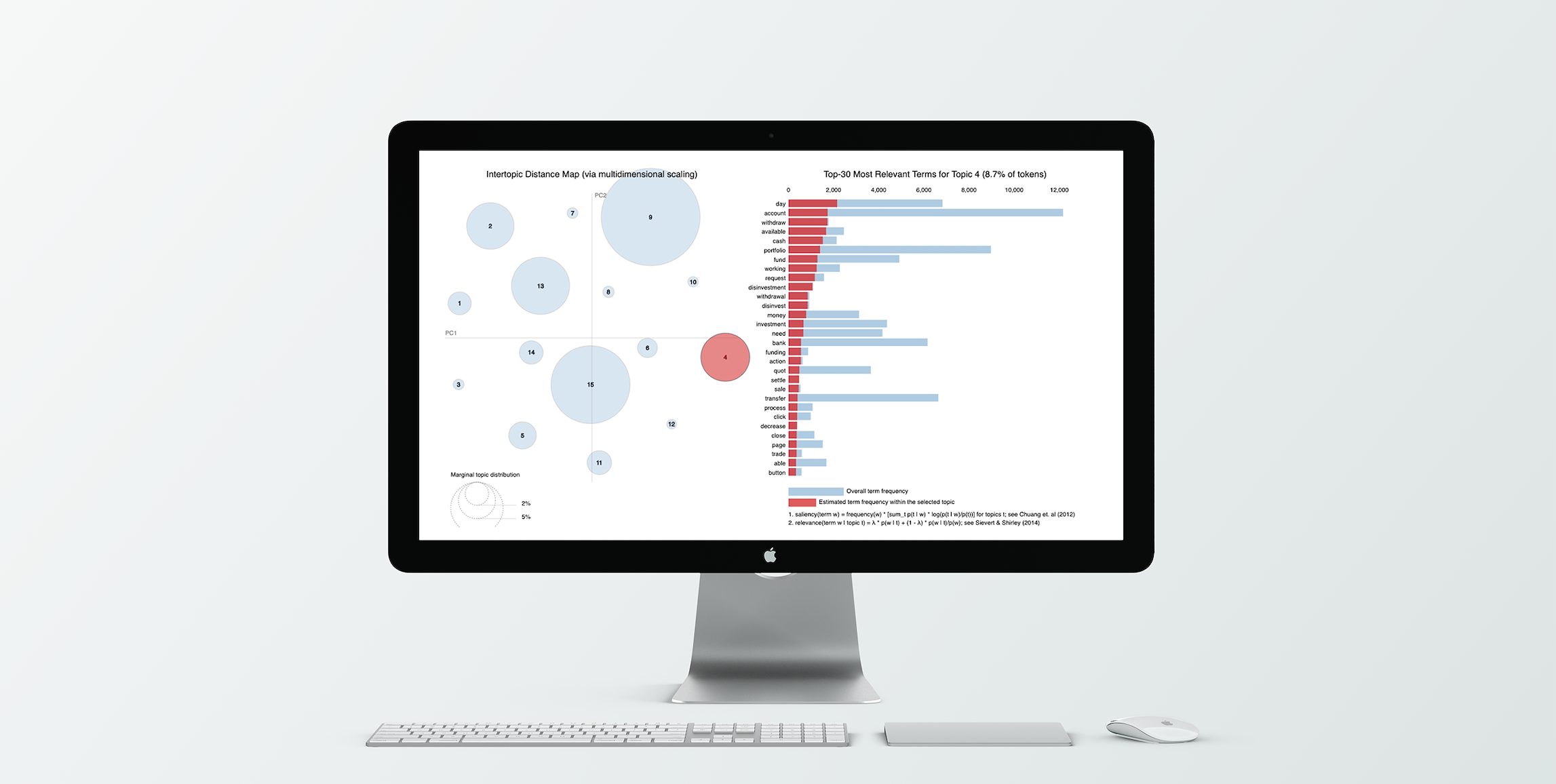
LDA output visualised with the pyLDAvis library. The model has been trained on about 10k chats, containing both English and Italian chats (translated into English). K=15 is the number of topics which has performed best among the tested values, according to the perplexity score. In the chart above, each circle on the left-hand side represents a topic with the size proportional to its frequency in the corpus; the right-hand side shows the overall relevance of the given token across the corpus. In the interactive visualisation, the bars on the right update after hovering over a topic circle to show the relevance of the tokens in the selected topic (red bars) as opposed to the relevance of the same tokens in the whole corpus (grey bars).
3. Assign topic labels to chats
So the LDA model provides topic weights for each document it is trained on. Now the transition to a supervised approach becomes straightforward: the vector component with the highest weight is picked and the corresponding topic is used as target label for the given chat document. In order to increase the confidence of the labels assignment, only the texts with a dominant topic weight above 0.5 have been retained in the following steps (other thresholds have been tested too but 0.5 was the value which has allowed to keep at the same time a reasonable proportion of online chats in the dataset as well as a good degree of confidence in the assignments).
4. Classify new chats
After building a setting compatible with a supervised machine learning algorithm, the multinomial logistic regression model has been trained and tested to classify new chats to the corresponding topic labels. The classification results in terms of precision and recall have been above 0.96 (on average among the 15 topic classes) across all the iterations of the 4-fold cross-validation technique used.
There are obviously many aspects that can be tweaked and improved (e.g. handle topic classes imbalance, improve automatic translation accuracy, try using different flows for each language instead of a single one for all translated texts, etc.), but there is definitely evidence that this approach could identify meaningful and interesting topical information out of a corpus of unstructured texts and provide an algorithm that accurately assigns topics to previously unseen online chats texts.
So what?
This analysis applied to a business context similar to the one presented here shows the effectiveness of a simple framework that companies can implement internally to have an idea of the type of enquiries, complaints or issues their customers have. It can also be a starting point to have a sense of the customers sentiment or feeling about a particular product, service or bug, without explicitly asking them for a feedback. It’s a fast and efficient way to gather insights about the interactions between consultants and customers, especially if this is complemented by metadata about the conversation (e.g. date, duration) and other types of information (e.g. client sign-up date, online activity, previous complaints, etc.).
Bio: Elena Pedrini is a Data Science Engineer and holds a MSc Big Data Science. She is passionate about everything that concerns data science and machine learning.
Original. Reposted with permission.
Related:
- Understanding NLP and Topic Modeling Part 1
- An Overview of Topics Extraction in Python with Latent Dirichlet Allocation
- How to Create a Vocabulary for NLP Tasks in Python