Testing Your Machine Learning Pipelines
Let’s take a look at traditional testing methodologies and how we can apply these to our data/ML pipelines.
By Kristina Young, Senior Data Scientist
When it comes to data products, a lot of the time there is a misconception that these cannot be put through automated testing. Although some parts of the pipeline can not go through traditional testing methodologies due to their experimental and stochastic nature, most of the pipeline can. In addition to this, the more unpredictable algorithms can be put through specialised validation processes.
Let’s take a look at traditional testing methodologies and how we can apply these to our data/ML pipelines.
Testing Pyramid
Your standard simplified testing pyramid looks like this:

This pyramid is a representation of the types of tests that you would write for an application. We start with a lot of Unit Tests, which test a single piece of functionality in isolation of others. Then we write Integration Tests which check whether bringing our isolated components together works as expected. Lastly we write UI or acceptance tests, which check that the application works as expected from the user’s perspective.
When it comes to data products, the pyramid is not so different. We have more or less the same levels.
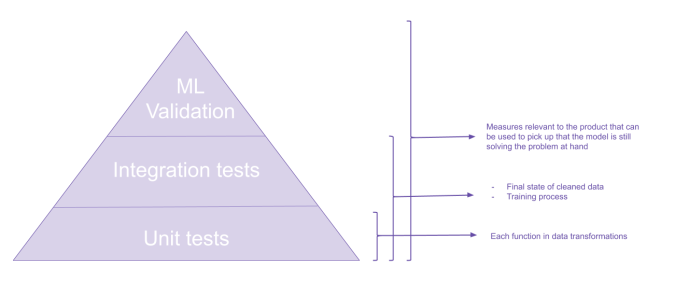
Note that the UI tests would still take place for the product, but this blog post focuses on tests most relevant to the data pipeline.
Let’s take a closer look at what each of these means in the context of Machine Learning, and with the help fo some sci-fi authors.
Unit tests
“It’s a system for testing your thoughts against the universe, and seeing whether they match” Isaac Asimov.
Most of the code in a data pipeline consists of a data cleaning process. Each of the functions used to do data cleaning has a clear goal. Let’s say, for example, that one of the features that we have chosen for out model is the change of a value between the previous and current day. Our code might look somewhat like this:
def add_difference(asimov_dataset):
asimov_dataset['total_naughty_robots_previous_day'] =
asimov_dataset['total_naughty_robots'].shift(1)
asimov_dataset['change_in_naughty_robots'] =
abs(asimov_dataset['total_naughty_robots_previous_day'] -
asimov_dataset['total_naughty_robots'])
return asimov_dataset[['total_naughty_robots', 'change_in_naughty_robots',
'robot_takeover_type']]
Here we know that for a given input we expect a certain output, therefore, we can test this with the following code:
import pandas as pd
from pandas.testing import assert_frame_equal
import numpy as np
from unittest import TestCase
def test_change():
asimov_dataset_input = pd.DataFrame({
'total_naughty_robots': [1, 4, 5, 3],
'robot_takeover_type': ['A', 'B', np.nan, 'A']
})
expected = pd.DataFrame({
'total_naughty_robots': [1, 4, 5, 3],
'change_in_naughty_robots': [np.nan, 3, 1, 2],
'robot_takeover_type': ['A', 'B', np.nan, 'A']
})
result = add_difference(asimov_dataset_input)
assert_frame_equal(expected, result)
For each piece of independent functionality, you would write a unit test, making sure that each part of the data transformation process has the expected effect on the data. For each piece of functionality you should also consider different scenarios (is there an if statement? then all conditionals should be tested). These would then be ran as part of your continuous integration (CI) pipeline on every commit.
In addition to checking that the code does what is intended, unit tests also give us a hand when debugging a problem. By adding a test that reproduces a newly discovered bug, we can ensure that the bug is fixed when we think that is fixed, and we can ensure that the bug does not happen again.
Lastly, these tests not only check that the code does what is intended, but also help us document the expectations that we had when creating the functionality.
Integration tests
Because “The unclouded eye was better, no matter what it saw.” Frank Herbert.
These tests aim to determine whether modules that have been developed separately work as expected when brought together. In terms of a data pipeline, these can check that:
- The data cleaning process results in a dataset appropriate for the model
- The model training can handle the data provided to it and outputs results (ensurign that code can be refactored in the future)
So if we take the unit tested function above and we add the following two functions:
def remove_nan_size(asimov_dataset):
return asimov_dataset.dropna(subset=['robot_takeover_type'])
def clean_data(asimov_dataset):
asimov_dataset_with_difference = add_difference(asimov_dataset)
asimov_dataset_without_na = remove_nan_size(asimov_dataset_with_difference)
return asimov_dataset_without_na
Then we can test that combining the functions inside clean_data will yield the expected result with the following code:
def test_cleanup():
asimov_dataset_input = pd.DataFrame({
'total_naughty_robots': [1, 4, 5, 3],
'robot_takeover_type': ['A', 'B', np.nan, 'A']
})
expected = pd.DataFrame({
'total_naughty_robots': [1, 4, 3],
'change_in_naughty_robots': [np.nan, 3, 2],
'robot_takeover_type': ['A', 'B', 'A']
}).reset_index(drop=True)
result = clean_data(asimov_dataset_input).reset_index(drop=True)
assert_frame_equal(expected, result)
Now let’s say that the next thing we do is feed the above data to a logistic regression model.
from sklearn.linear_model import LogisticRegression
def get_reression_training_score(asimov_dataset, seed=9787):
clean_set = clean_data(asimov_dataset).dropna()
input_features = clean_set[['total_naughty_robots',
'change_in_naughty_robots']]
labels = clean_set['robot_takeover_type']
model = LogisticRegression(random_state=seed).fit(input_features, labels)
return model.score(input_features, labels) * 100
Although we don’t know the expectation, we can ensure that we always result in the same value. It is useful for us to test this integration to ensure that:
- The data is consumable by the model (a label exists for every input, the types of the data are accepted by the type of model chosen, etc)
- We are able to refactor our code in the future, without breaking the end to end functionality.
We can ensure that the results are always the same by providing the same seed for the random generator. All major libraries allow you to set the seed (Tensorflow is a bit special, as it requires you to set the seed via numpy, so keep this in mind). The test could look as follows:
from numpy.testing import assert_equal
def test_regression_score():
asimov_dataset_input = pd.DataFrame({
'total_naughty_robots': [1, 4, 5, 3, 6, 5],
'robot_takeover_type': ['A', 'B', np.nan, 'A', 'D', 'D']
})
result = get_reression_training_score(asimov_dataset_input, seed=1234)
expected = 40.0
assert_equal(result, 50.0)
There won’t be as many of these kinds of tests as unit tests, but they would still be part of your CI pipeline. You would use these to check the end to end functionality for a component and would therefore test more major scenarios.
ML Validation
Why? “To exhibit the perfect uselessness of knowing the answer to the wrong question.” Ursula K. Le Guin.
Now that we have tested our code, we need to also test that the ML component is solving the problem that we are trying to solve. When we talk about product development, the raw results of an ML model (however accurate based on statistical methods) are almost never the desired end outputs. These results are usually combined with other business rules before consumed by a user or another application. For this reason, we need to validate that the model solves the user problem, and not only that the accuracy/f1-score/other statistical measure is high enough.
How does this help us?
- It ensures that the model actually helps the product solve the problem at hand
- For example, a model that classifies a snake bite as deadly or not with 80% accuracy is not a good model if the 20% that is incorrect leads to patients not getting the treatment that they need.
- It ensures that the values produced by the model make sense in terms of the industry
- For example, a model that predicts changes in price with 70% accuracy is not a good model, if the end price displayed to the user has a value that’s too low/high to make sense in that industry/market.
- It provides an extra layer of documentation of the decisions made, helping engineers joining the team later in the process.
- It provides visibility of the ML components of the product in a common language understood by clients, product managers and engineers in the same way.
This kind of validation should be ran periodically (either through the CI pipeline or a cron job), and its results should be made visible to the organisation. This ensures that progress in the data science components is visible to the organisation, and ensures that issues caused by changes or stale data are caught early.
Conclusion
After all “Magic’s just science that we don’t understand yet” Arthur C. Clarke.
ML components can be tested in various ways, bringing us the following advantages:
- Resulting in a data driven approach to ensure that the code does what is expected
- Ensuring that we can refactor and cleanup code without breaking the functionality of the product
- Documenting functionality, decisions and previous bugs
- Providing visibility of the progress and state of the ML components of a product
So don’t be afraid, if you have the skillset to write the code, you have the skillset to write the test and gain all of the above advantages ????.
So long and thanks for all the testing!
Bio: Kristina Young is a Senior Data Scientist at BCG Digital Ventures. She has previously worked at SoundCloud as a Backend and Data Engineer in the Recommendations team. Her previous experience is as a consultant and researcher. She has worked as a back end, web and mobile developer in the past on a variety of technologies.
Original. Reposted with permission.
Related:
- 5 Step Guide to Scalable Deep Learning Pipelines with d6tflow
- How I Got Better at Machine Learning
- Data Pipelines, Luigi, Airflow: Everything you need to know