Advice for a Successful Data Science Career
This blog is meant to show that most everyone has had to expend quite a bit of effort to get where they are. They have to work hard, sometimes experience failure, show discipline, be persistent, be dedicated to their goals, and sometimes sacrifice or take risks.
By Michael Galarnyk, Data Scientist

I had previously written How to Build a Data Science Portfolio which covered the importance of showing potential employers what you can do instead of just telling them you can do something. This blog utilizes a Success is an Iceberg Image by Orysya Stus as a framework to show that a couple aspects of people’s journeys to their perceived data science success are often hidden from view. This blog is meant to show that most everyone has had to expend quite a bit of effort to get where they are. They have to work hard, sometimes experience failure, show discipline, be persistent, be dedicated to their goals, and sometimes sacrifice or take risks. With that, let’s get started!
Mistakes/Failures
A small sample of data science mistakes I've made so far ???? pic.twitter.com/EeiVmmAnuJ
— Caitlin Hudon ???????????? (@beeonaposy) April 29, 2019
As you can see in the GIF above that Caitlin Hudon (Lead Data Scientist at OnlineMedEd) created for her tweet, there are plenty of technical mistakes/failures people make in their daily model building.
most of us who code or do data science often see the end product of each others’ work — not the drafts and mistakes and decisions we make as part of the process. A little transparency around those steps goes a long way.
Jake VanderPlas seemed to echo a similar sentiment in a tweet about in open source people usually only see the finished product rather than the process.
So often in open source we see the finished product rather than the process… and that can be discouraging to people starting out who see all the apparent perfection around them.
But I would wager that behind the polished veneer of any successful open source project, there’s plenty of pain, agony, and self-doubt.
Along with technical failures, there are other kind of failures including the types you can wear (journal rejections, email rejections, etc). Caitlin K. Kirby literally wore her failures/rejections. There is an article in the Washington Post that details that her skirt was a handmade, knee-length garment made out of 17 rejection letters (journal rejections, email rejections, etc) she had gotten in the past five years.
Successfully defended my PhD dissertation today! In the spirit of acknowledging & normalizing failure in the process, I defended in a skirt made of rejection letters from the course of my PhD. #AcademicTwitter #AcademicChatter #PhDone
THANK YOU to everyone involved in my journey pic.twitter.com/FQbXYQ1Oov— Caitlin K. Kirby (@kirbycai) October 7, 2019
By the way if you want more stories of software/data science related rejection stories, there is an entire rejections site you can check out that might inspire you.
Hard Work/Tenacity
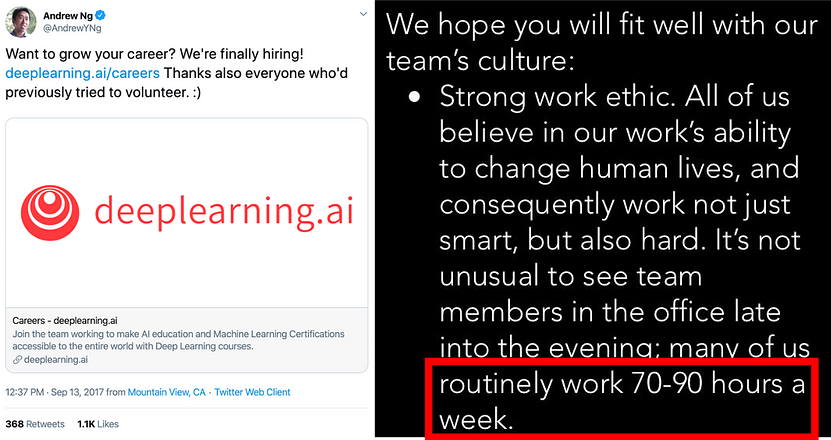
Most people have had to work hard to get where they are. I am definitely not saying you have to routinely work 70–90 hour weeks as that sounds unhealthy. Rachel Thomas’ post mentions how this sort of attitude can be discriminatory and counterproductive.
As much as possible, we need to get away from the shallow idea that the quantity of time worked is what matters. The tech industry’s obsession with ridiculously long hours is not only inaccessible to many disabled people and harmful to everyone’s health and relationships, but as Olivia Goldhill pointed out for Quartz at Work, research on productivity suggests it’s just inefficient:
As countless studies have shown, this simply isn’t true. Productivity dramatically decreases with longer work hours, and completely drops off once people reach 55 hours of work a week, to the point that, on average, someone working 70 hours in a week achieves no more than a colleague working 15 fewer hours.
Crazy long hours are also common in academia as Jake VanderPlas’ tweet mentions below.
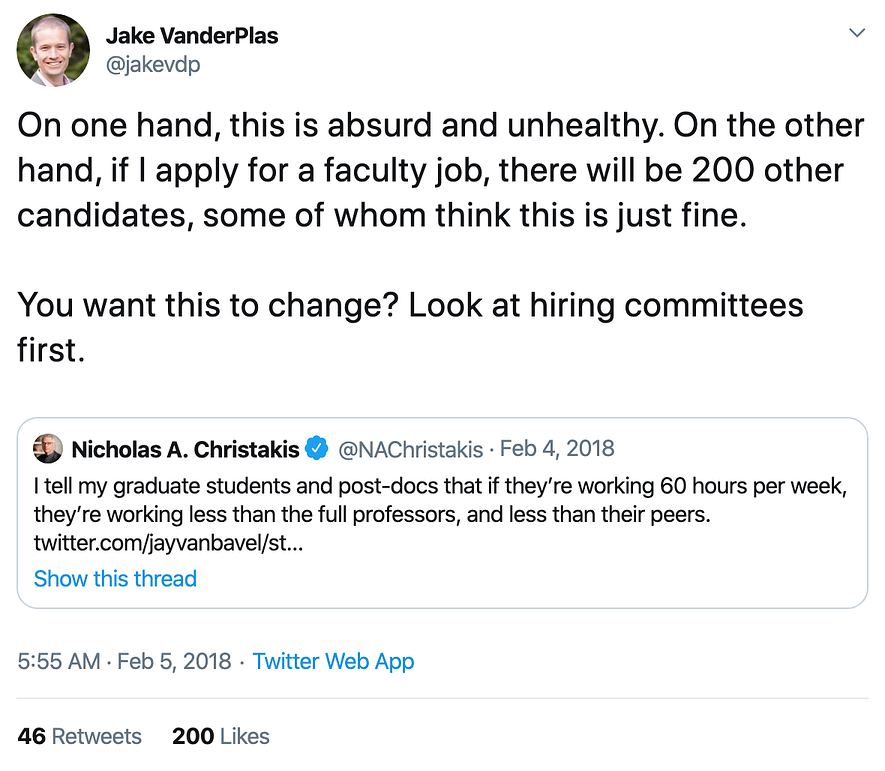
While this tweet isn’t a comment on the earlier tweet from Andrew Ng, I think it shows that there are different ways to be successful rather than working continuously. The author of the Python Data Science Handbook seems to be doing well. (Tweet by Jake VanderPlas)
Rather than hard work, maybe we should talk about tenacity or persistence as Jeremy Howard’s and Sylvain Gugger’s new book has a nice passage on being tenacious.

Content from tweet was an extract from Jeremy Howard’s and Sylvain Gugger’s new book.
In short, I think the best thing to take from this is that:
you will face many obstacles, both technical, and (even more difficult) people around you who don’t believe you’ll be successful. There’s one guaranteed way to fail, and that’s to stop trying.
Persistence
A lot of success in life is about being persistent. There are many stories of successful people like Kelly Peng, Data Scientist at Airbnb, who really persevered and kept on working and improving. In one of her blog posts, she went over how many places she applied for and interviewed with.
Applications: 475
Phone interviews: 50
Finished data science take-home challenges: 9
Onsite interviews: 8
Offers: 2
Time spent: 6 months
She clearly applied to a lot of jobs and kept on persisting. In her article, she even mentions how you need to keep on learning from your interviewing experiences.
Take note of all the interview questions you got asked, especially those questions you failed to answer. You can fail again, but don’t fail at the same spot. You should always be learning and improving.
Discipline/Dedication
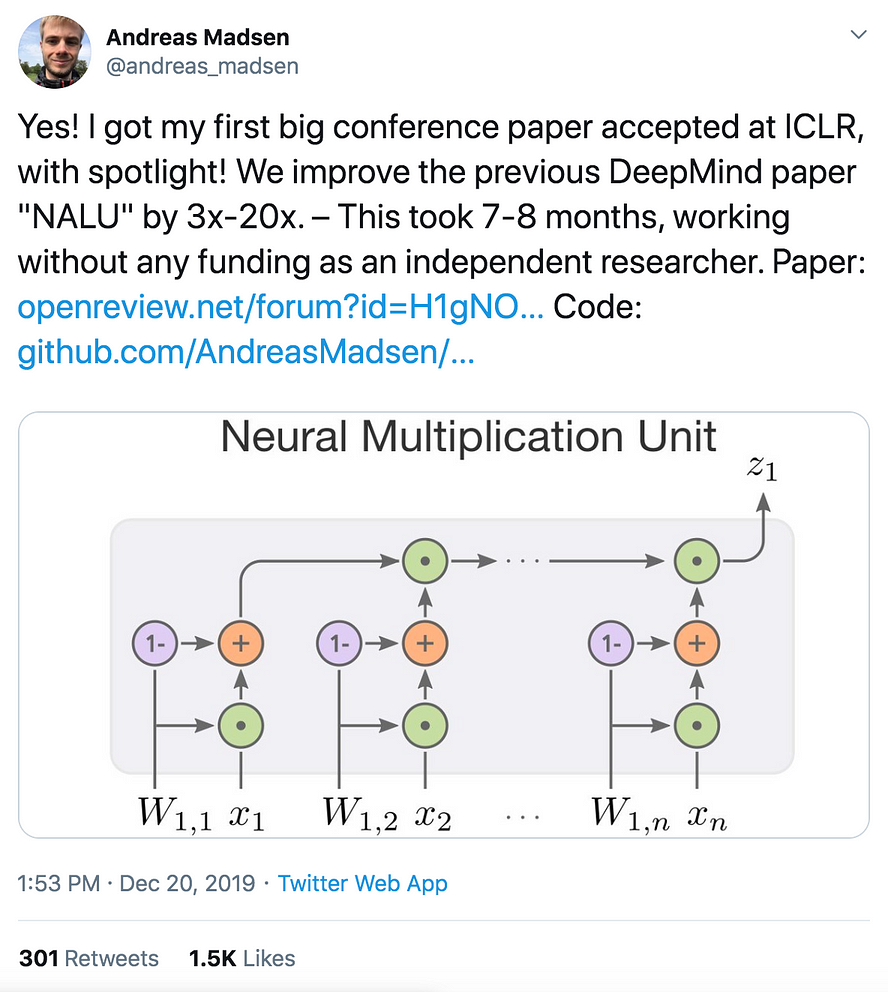
One of the major themes this article is that everyone has experienced some failure. The important part is that some people go to great lengths to achieve there goals. In a blog post published by Andreas Madsen, he described how hard it is to get into a top PhD program for AI (usually computer science departments). Essentially with all the professors he talked to, he was told he needed “1–2 publications in top ML venues” to get into a top phd program. He spent 7 months straight working on a research project without funding and without a supervisor in order to produce work that could be publishable.
Sacrifices/Taking Risks
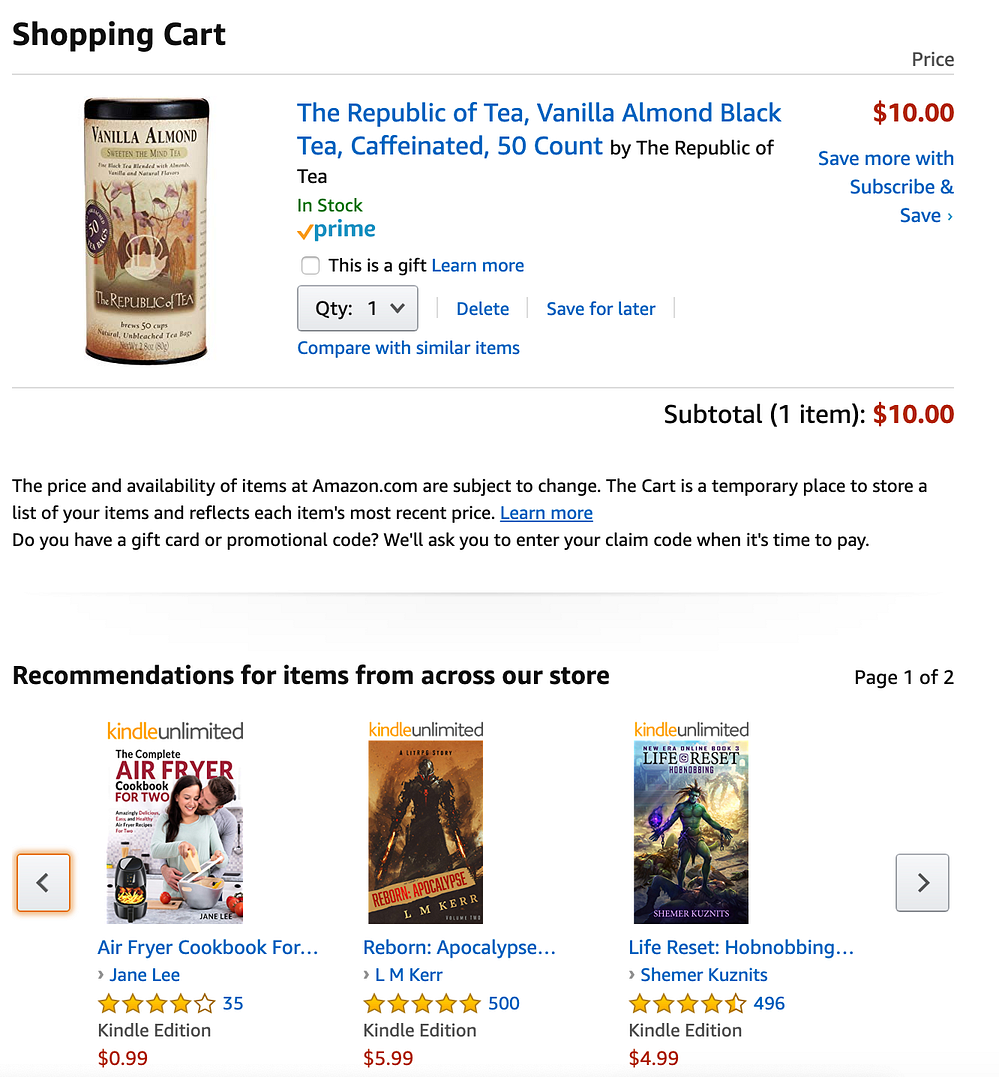
Sacrifices and risks can come in many different forms. One risk could be ignoring commands from above. When Greg Linden was at Amazon, he worked on a couple fun projects even though he was supposed to be working on other things. In one of his blog posts, he described a project which was:
making recommendations based on the items in your Amazon shopping cart. Add a couple things, see what pops up. Add a couple more, see what changes…I hacked up a prototype. On a test site, I modified the Amazon.com shopping cart page to recommend other items you might enjoy adding to your cart. Looked pretty good to me. I started showing it around.
There was a problem.
While the reaction was positive, there was some concern. In particular, a marketing senior vice-president was dead set against it…At this point, I was told I was forbidden to work on this any further. I was told Amazon was not ready to launch this feature. It should have stopped there.
Instead, I prepared the feature for an online test. I believed in shopping cart recommendations. I wanted to measure the sales impact.
I heard the SVP was angry when he discovered I was pushing out a test. But, even for top executives, it was hard to block a test. Measurement is good. The only good argument against testing would be that the negative impact might be so severe that Amazon couldn’t afford it, a difficult claim to make. The test rolled out.
The results were clear. Not only did it win, but the feature won by such a wide margin that not having it live was costing Amazon a noticeable chunk of change. With new urgency, shopping cart recommendations launched…
At the time, Amazon was certainly chaotic, but I suspect I was taking a risk by ignoring commands from above. As good as Amazon was, it did not yet have a culture that fully embraced measurement and debate.
While I don’t advocate ignoring advice from superiors, it seems like in some circumstances, taking risks can be beneficial for the company and for yourself.
Conclusion

Hopefully you find some of the advice and examples from this blog to be useful on your data science journey. Keep in mind that a lot of advice from successful people suffers from survivorship bias. Always take advice or shared experiences with a grain of salt. If you have any questions, thoughts on the post, or just want to share your own experiences, feel free to reach out in the comments below or through Twitter.
Bio: Michael Galarnyk is a Data Scientist and Corporate Trainer. He currently works at Scripps Translational Research Institute. You can find him on Twitter (https://twitter.com/GalarnykMichael), Medium (https://medium.com/@GalarnykMichael), and GitHub (https://github.com/mGalarnyk).
Original. Reposted with permission.
Related:
- Getting up and Running with Python: Installing Anaconda on Windows
- Understanding Decision Trees for Classification in Python
- Python Tuples and Tuple Methods