A Comprehensive Data Repository for Fake Health News Detection
We introduce the FakeHealth, a new data repository for fake health news detection. Following a preliminary analysis to demonstrate its features, we consider additional potential directions for better identifying fake news.
By Enyan Dai and Suhang Wang, PennState.
You may not be surprised that 81.5% of the U.S. population search for health information online. Actually, around 70% of them treat the internet as the first source to get healthcare information. However, a large number of fake health news is poisoning the online environment. For example, a popular health news piece, “Ginger is 10,000x more effective at killing cancer than chemo,” which generated around 1 million engagements on Facebook, turned out to be a misleading claim. These statements are threatening public health. One of the solutions is developing machine learning models to automatically detect the fake news and even present explanations of the detection results. The success of these algorithms heavily relies on high-quality labeled datasets. To facilitate the community, we collected and released a comprehensive data repository: FakeHealth, which could inspire various research directions around fake health news detection [1].
Dataset Description
FakeHealth consists of two datasets, i.e., HealthStory and HealthRelease, which correspond to news stories and press releases, respectively. Both are checked and graded by HealthNewsReview.org.
Here is the pipeline of the collection process. As Figure 1 shows, the repository was collected with four steps:
- The reviews were crawled from HealthNewsReview.org.
- The news crawler collected the source news contents with the source URLs obtained in step 1.
- The social engagements could be collected from Twitter with the news titles, news URLs, and the crawlers.
- The user crawler used the engagements obtained in step 3 to construct a user network.

Figure 1: Overview of the collection pipeline.
The datasets of FakeHealth contain news contents, news reviews, social engagements, and user network. These rich features will enable exploration of various directions in fake health news detection [1, 2].
- News contents: text is provided along with the source publisher, image links, and other side information, which benefits the development of algorithms utilizing publisher credibility, visuals, and other information in addition to article style for better detection performance.
- Social engagements: around 500k tweets, 29k replies and their 14k retweets related to the health news (containing the news headline or URL) are crawled in FakeHealth. Thus, social context-based fake news detection could be investigated on this repository.
- User network: user network consists of user profiles, user timelines, and user friend profiles. The abundant information of users could help us develop more sophisticated models that pay more attention to the users that less likely to be misled.
- News reviews: it covers the labels (ratings) of the news, tags, images, and news sources. Apart from these rich side information, one important characteristic of the news reviews in FakeHealth is that explanations to the labels are provided in the news reviews. Specifically, ten criteria are set to evaluate the news. The ground truth of the criteria and their corresponding explanations are covered. Figure 2 shows an example of one criterion and its explanation for “Virtual reality to help detect early risk of Alzheimer’s”:

Figure 2: An example of health news evaluation criterion and explanation.
Exploratory analysis
Next, we conduct some primary analysis to demonstrate its quality and explore potential features for fake health news detection.
News topics: A fair fake news dataset should have similar topic distributions across the fake category and real category. Otherwise, the detector trained on the dataset is likely to be a topic detector instead of a fake news detector. Here we could visualize the frequent words of the headline with a word cloud to compare their topics.

Figure 3: The word cloud of news headline for real and fake news on HealthStory and HealthRelease.
As expected, the covered topics of real and news in both datasets are quite similar. For instance, from (a) and (b) we can find the real and fake news in HealthStory have many common topics such as “cancer,” “heart,” and “brain.” We also have a similar observation in HealthRelease. Both real and fake news in HealthRelease mainly focus on cancer, surgery, and therapy. This implies that the topics of true and fake news are consistent in FakeHealth.
News resources: When we estimate the credibility of the information, we usually consider whether the sources are trustable. This common sense indicates that the news from certain sources is more trustable. Here, we compare the average ratings of ten news agencies in FakeHealth.
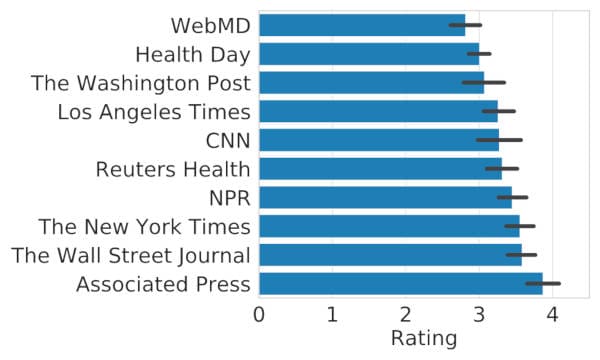
Figure 4: The average ratings of news from different sources in FakeHealth.
As Figure 4 shows, the ratings of news publishers actually differ a lot. Their 95% confidence interval of mean ratings nearly do not overlap. This indicates that the news sources could be a feature for fake news detection.
News Social Engagements: In order to make the datasets feasible with the models using social engagements, FakeHealth crawls a large number of related tweets, retweets, and replies. Through the datasets, we find that the number of tweets that interact with fake health news is quite similar to the real ones. We further conduct sentiment analysis to the replies with VANDER [3]. We find that in HealthStory, the replies towards tweets about real health news tend to be more positive than the ones to tweets about fake health news. This indicates that the social context might be useful for fake news detection.
User credibility: Another interesting aspect of the social context is user credibility. It has been reported that bots are slightly more likely to participate in the spread of fake news than in the spread of real news [4]. In order to check whether a similar trend exists in FakeHealth, we use Botometer API to plot the bot-likelihood cumulative distribution function of users who only involve with real news and users who involve with fake news.
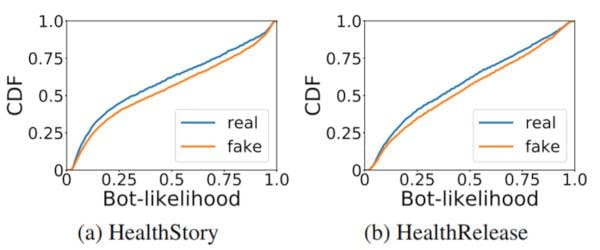
Figure 5: Cumulative distribution functions showing bot-likelihood distributions of users involved in real and fake health news.
As Figure 5 shows, in both HealthStory and HealthRelease, the users who propagate fake news are slightly more likely to be bots. This observation implies that user credibility is reasonable to be considered for fake health news detection.
Potential Research Directions
With the massive side information obtained for the news pieces, a number of potential applications will benefit from FakeHealth. Such as:
- Explainable fake health news detection
- Knowledge-based fake health news detection
- Credibility-based fake health news detection
- Multi-Modal fake News detection
- Analysis of Fake Health News Propagation.
References
[1] Dai, E., Sun, Y., & Wang, S. (2020). Ginger Cannot Cure Cancer: Battling Fake Health News with a Comprehensive Data Repository. arXiv preprint arXiv:2002.00837.
[2] Zhou, X., & Zafarani, R. (2018). Fake news: A survey of research, detection methods, and opportunities. arXiv preprint arXiv:1812.00315.
[3] Hutto, C. J., & Gilbert, E. (2014, May). Vader: A parsimonious rule-based model for sentiment analysis of social media text. In Eighth international AAAI conference on weblogs and social media.
[4] Vosoughi, S., Roy, D., & Aral, S. (2018). The spread of true and false news online. Science, 359(6380), 1146-1151.
Bios: Enyan Dai is a first-year Ph.D. student in the College of Information Sciences and Technology, The Pennsylvania State University. His research interests lie in social media mining and machine learning, especially about fake news detection, weakly supervised learning, and generative models.
Suhang Wang is an assistant professor of the College of Information Sciences and Technology, The Pennsylvania State University. His research mainly focuses on data mining and machine learning with applications to social media mining. He started working on fake news detection in social media since 2016 and has published 10+ top-tier conference and journal papers such as KDD and WSDM on this topic.
Related: