Simple Question Answering (QA) Systems That Use Text Similarity Detection in Python
How exactly are smart algorithms able to engage and communicate with us like humans? The answer lies in Question Answering systems that are built on a foundation of Machine Learning and Natural Language Processing. Let's build one here.
By Andrew Zola, Content Manager at Artmotion
Artificial Intelligence (AI) is no longer an abstract idea that conjures up images from sci-fi movies. Today, AI has evolved considerably, and it’s now able to recognize speech, make decisions, and work alongside humans to complete tasks at a larger scale.
So instead of robots that are trying to take over the planet, we think about Alexa, Siri, or a customer service chatbot. But how exactly are these smart algorithms able to engage and communicate with us like humans?
The answer lies in Question Answering (QA) systems that are built on a foundation of Machine Learning (ML) and Natural Language Processing (NLP).
What are QA Systems?
QA systems can be described as a technology that provides the right short answer to a question rather than giving a list of possible answers. In this scenario, QA systems are designed to be alert to text similarity and answer questions that are asked in natural language.
But some also derive information from images to answer questions. For example, when you’re clicking on image boxes to prove that you’re not a robot, you’re actually teaching smart algorithms about what’s in a particular image.
This is only possible because of NLP technologies like Google’s Bidirectional Encoder Representations from Transformers (BERT). Anyone who wants to build a QA system can leverage NLP and train machine learning algorithms to answer domain-specific (or a defined set) or general (open-ended) questions.
There are plenty of datasets and resources online, so you can quickly start training smart algorithms to learn and process massive quantities of human language data.
To boost efficiency and accuracy, NLP programs also use both inference and probability to guess the right answer. Over time, they have become very good at it!
For businesses, the advantage of deploying QA systems is that they are highly user-friendly. Once the enterprise QA system is built, anyone can use it. In fact, if you have engaged with Alexa or used Google Translate, you have experienced NLP at work.
In an enterprise setting, they can be used for much more than chatbots and voice assistants. For example, smart algorithms can be trained to do the following:
- Administration (find and contextualize information to automate the process of searching, modifying, and managing documents)
- Customer service (with chatbots that can engage customers as well as identify new leads by analyzing profiles, phrases, and other data)
- Marketing (by being alert to mentions about the company or brand online)
But circling back to the topic at hand, let’s take a look at how it works.
How Do You Build a Robust QA System?
To answer the question in a manner that can be technical and easily understood, I’ll show you how to build a simple QA system based on string similarity measurement, and sourced using a closed domain.
The following example is based on Ojokoh and Ayokunle’s research, Fuzzy-Based Answer Ranking in Question Answering Communities.
QA system with approximate match function is simple as:
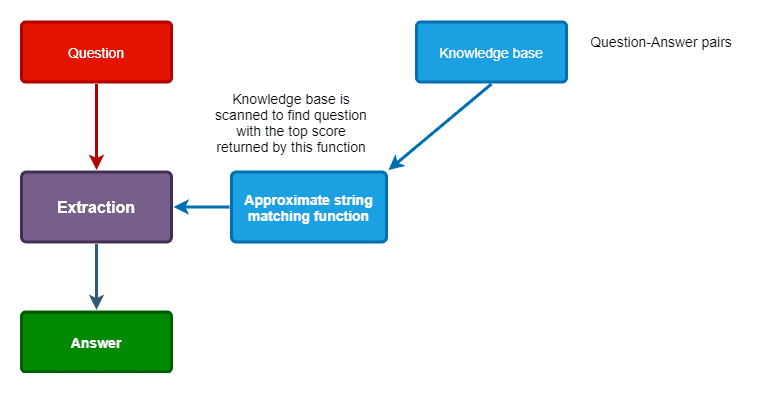
In this scenario, we’ll use a small set of data of question-answer pairs in a CSV file. In the real world, enterprises will use highly specialized databases with hundreds of thousands of samples.
Prerequisites
To run these examples, you need Python 3, Jupyter Lab and python-Levenshtein module.
First load the data:
import pandas as pd
data = pd.read_csv('qa.csv')
# this function is used to get printable results
def getResults(questions, fn):
def getResult(q):
answer, score, prediction = fn(q)
return [q, prediction, answer, score]
return pd.DataFrame(list(map(getResult, questions)), columns=["Q", "Prediction", "A", "Score"])
test_data = [
"What is the population of Egypt?",
"What is the poulation of egypt",
"How long is a leopard's tail?",
"Do you know the length of leopard's tail?",
"When polar bears can be invisible?",
"Can I see arctic animals?",
"some city in Finland"
]
data
| Question | Answer |
| Who determined the dependence of the boiling o... | Anders Celsius |
| Are beetles insects? | Yes |
| Are Canada 's two official languages English a... | yes |
| What is the population of Egypt? | more than 78 million |
| What is the biggest city in Finland? | Greater Helsinki |
| What is the national currency of Liechtenstein? | Swiss franc |
| Can polar bears be seen under infrared photogr... | Polar bears are nearly invisible under infrare... |
| When did Tesla demonstrate wireless communicat... | 1893 |
| What are violins made of? | different types of wood |
| How long is a leopard's tail? | 60 to 110cm |
In its simplest form, QA systems can only answer questions if the questions and answers are matched perfectly.
import re
def getNaiveAnswer(q):
# regex helps to pass some punctuation signs
row = data.loc[data['Question'].str.contains(re.sub(r"[^\w'\s)]+", "", q),case=False)]
if len(row) > 0:
return row["Answer"].values[0], 1, row["Question"].values[0]
return "Sorry, I didn't get you.", 0, ""
getResults(test_data, getNaiveAnswer)
| Q | Prediction | A | Score | |
| 1 | What is the population of Egypt? | What is the population of Egypt? | more than 78 million | 1 |
| 2 | What is the population of egypt | Sorry, I didn't get you. | 0 | |
| 3 | How long is a leopard's tail? | How long is a leopard's tail? | 60 to 110cm | 1 |
| 4 | Do you know the length of leopard's tail? | Sorry, I didn't get you. | 0 | |
| 5 | When polar bears can be invisible? | Sorry, I didn't get you. | 0 | |
| 6 | Can I see arctic animals? | Sorry, I didn't get you. | 0 | |
| 7 | some city in Finland | Sorry, I didn't get you. | 0 |
As you can see from the above, a small grammatical mistake can quickly derail the whole process. It’s the same result if you use string pre-processing of source and query texts like punctuation symbols removal,lowercasing, etc.
So how can we improve our results?
To improve results, let’s switch things up a little and use approximate string matching. In this scenario, our system will be enabled to accept grammatical mistakes and minor differences in the text.
There are many ways to deploy approximate string matching protocols, but for our example, we will use one of the implementations of string metrics called Levenshtein distance. In this scenario, the distance between two words is the minimum number of single-character edits (insertions, deletions, or substitutions) that are needed to change one word into the other.
Let’s deploy the Levenshtein Python module on the system. It contains a set of approximate string matching functions that we can experiment with.
from Levenshtein import ratio
def getApproximateAnswer(q):
max_score = 0
answer = ""
prediction = ""
for idx, row in data.iterrows():
score = ratio(row["Question"], q)
if score >= 0.9: # I'm sure, stop here
return row["Answer"], score, row["Question"]
elif score > max_score: # I'm unsure, continue
max_score = score
answer = row["Answer"]
prediction = row["Question"]
if max_score > 0.8:
return answer, max_score, prediction
return "Sorry, I didn't get you.", max_score, prediction
getResults(test_data, getApproximateAnswer)
| Q | Prediction | A | Score | |
| 1 | What is the population of Egypt? | What is the population of Egypt? | more than 78 million | 1.000000 |
| 2 | What is the poulation of egypt | What is the population of Egypt? | more than 78 million | 0.935484 |
| 3 | How long is a leopard's tail? | How long is a leopard's tail? | 60 to 110cm | 1.000000 |
| 4 | Do you know the length of leopard's tail? | How long is a leopard's tail? | Sorry, I didn't get you. | 0.657143 |
| 5 | When polar bears can be invisible? | Can polar bears be seen under infrared photogr... | Sorry, I didn't get you. | 0.517647 |
| 6 | Can I see arctic animals? | What is the biggest city in Finland? | Sorry, I didn't get you. | 0.426230 |
| 7 | some city in Finland | What is the biggest city in Finland? | Sorry, I didn't get you. | 0.642857 |
As you can see from the above, even minor grammatical mistakes can generate the correct answer (and a score below 1.0 is highly acceptable).
To make our QA system even better, go ahead and adjust max_score coefficient of our function to be more accommodating.
from Levenshtein import ratio
def getApproximateAnswer2(q):
max_score = 0
answer = ""
prediction = ""
for idx, row in data.iterrows():
score = ratio(row["Question"], q)
if score >= 0.9: # I'm sure, stop here
return row["Answer"], score, row["Question"]
elif score > max_score: # I'm unsure, continue
max_score = score
answer = row["Answer"]
prediction = row["Question"]
if max_score > 0.3: # threshold is lowered
return answer, max_score, prediction
return "Sorry, I didn't get you.", max_score, prediction
getResults(test_data, getApproximateAnswer2)
| Q | Prediction | A | Score | |
| 0 | What is the population of Egypt? | What is the population of Egypt? | more than 78 million | 1.000000 |
| 1 | What is the poulation of egypt | What is the population of Egypt? | more than 78 million | 0.935484 |
| 2 | How long is a leopard's tail? | How long is a leopard's tail? | 60 to 110cm | 1.000000 |
| 3 | Do you know the length of leopard's tail? | How long is a leopard's tail? | 60 to 110cm | 0.657143 |
| 4 | When polar bears can be invisible? | Can polar bears be seen under infrared photogr... | Polar bears are nearly invisible under infrare... | 0.517647 |
| 5 | Can I see arctic animals? | What is the biggest city in Finland? | Greater Helsinki | 0.426230 |
| 6 | some city in Finland | What is the biggest city in Finland? | Greater Helsinki | 0.642857 |
The results above evidence that even when different words are used, the system can respond with the correct answer. But if you took a closer look, the 5th result looks like a false positive.
This means that we have to take it to the next level and leverage advanced libraries that have been made available by the likes of Facebook and Google to overcome these challenges.
The example above is a simple demonstration of how this works. The code is quite simple and impractical to use with large volumes and iterations on a massive dataset.
The well-known BERT library, developed by Google, is better suited for enterprise tasks. AI-powered QA systems that you’ve already engaged with use far more advanced databases and engage in continuous machine learning.
What’s your experience building enterprise QA systems? What challenges did you face? How did you overcome them? Share your thoughts and experiences in the Comments section below.
The source code for this article can be found HERE.
Bio: Andrew Zola (@DrewZola) is Content Manager at Artmotion: A bank for your data. He has many passions, but the main one is writing about technology. Furthermore, learning about new things and connecting with diverse audiences is something that has always amazed and excited Andrew.
Related:
- This Microsoft Neural Network can Answer Questions About Scenic Images with Minimum Training
- Salesforce Open Sources a Framework for Open Domain Question Answering Using Wikipedia
- Why you should NOT use MS MARCO to evaluate semantic search