Why you should NOT use MS MARCO to evaluate semantic search
If we want to investigate the power and limitations of semantic vectors (pre-trained or not), we should ideally prioritize datasets that are less biased towards term-matching signals. This piece shows that the MS MARCO dataset is more biased towards those signals than we expected and that the same issues are likely present in many other datasets due to similar data collection designs.
By Thiago Guerrera Martins, Principal Data Scientist @ Verizon Media

MS MARCO is a collection of large scale datasets released by Microsoft with the intent of helping the advance of deep learning research related to search. It was our first choice when we decided to create a tutorial showing how to setup a text search application with Vespa. It was getting a lot of attention from the community, in great part due to the intense competition around leaderboards. Besides, being a large and challenging annotated corpus of documents, it checked all the boxes at the time.
We followed up the first basic search tutorial with a blog post and a tutorial on how to use ML in Vespa to improve the text search application. So far so good. Our first issue came when we were writing the third tutorial on how to use (pre-trained) semantic embeddings and approximate nearest neighbor search to improve the application. At this point we started to realize that maybe the full-text ranking MS MARCO dataset was not the best way to go.
After looking more closely at the data, we started to realize that the dataset was highly biased towards term-matching signals. And by that I mean, much more than we expected.
But we know it is biased …
Before we go on to the data, we must say that we expected bias in the dataset. According to the MS MARCO dataset paper, they built the dataset by:
- Sampling queries from Bing’s search logs.
- Filtering out non question queries.
- Retrieve relevant documents for each question using Bing from its large-scale web index.
- Automatically extract relevant passages from those documents
- Human editors then annotate passages that contain useful and necessary information for answering the questions
Looking at steps 3 and 4 (and maybe 5), it is not surprising to find bias in the dataset. And to be fair, I think the bias is recognized as an issue in the literature. The surprise was the degree of the bias that we observed and how this might affect experiments involving semantic search.
Semantic embeddings setup
Our main goal was to illustrate how we can create out-of-the-box semantic aware text search applications by using term-matching and semantic signals. This combined with Vespa’s ability to perform Approximate Nearest Neighbor search would allow users to build such applications at scale.
In the results presented next we use BM25 scores as our term-matching signal and the sentence BERT model to generate embeddings to represent the semantic signal. Similar results were obtained with simpler term-matching signals and other semantic models like Universal Sentence Encoder. More details and code can be found in the tutorial.
Combining signals
We started with a reasonable baseline involving only term-matching signals. Next, we got promising results when we used only semantic signals in the application, just to sanity check the setup and to confirm that there was indeed relevant information contained in the embeddings. After that, the obvious follow up was to combine both signals.
Vespa offers a lot of possibilities here as we can combine term-matching and semantic signals, both in the match phase and in the ranking phase. In the match phase, we can use the nearestNeighbor operator for the semantic vectors and the multitude of operators usually used for term-matching such as the usuals AND and OR grammar to combine query tokens or useful approximations like weakAND. In the ranking phase, we can use well known ranking features such as BM25 and the Vespa tensor evaluation framework to do whatever we want with input signals such as the semantic embeddings.
It was when we started to experiment with all these possibilities that we began to question the usefulness of the MS MARCO dataset for this type of experiment. The main point was that, although the semantic signals were doing a decent job in isolation, the improvements would disappear when term-matching signals were taken into account.
We were expecting a significant intersection between term-matching and semantic signals since both should contain information about query document relevance. However, the semantic signals need to complement the term-matching signals for it to be valuable, given that they are more expensive to store and compute. This means that they should match relevant documents that would not otherwise be matched by term-matching signals.
However, this was not the case, as far as we could see it. So, we decided to look more closely at the data.
Term-matching bias
To better investigate what was going on, we collected query-document data from Vespa about both relevant and random documents. For example, the next graph shows the empirical distribution of the sum of dot-products between the query and title embeddings and between the query and body embeddings. The blue histogram shows the distribution for random (and therefore likely non-relevant to the queries) documents. The red histogram shows the same information but now conditioned on the fact that the documents are relevant to the queries.
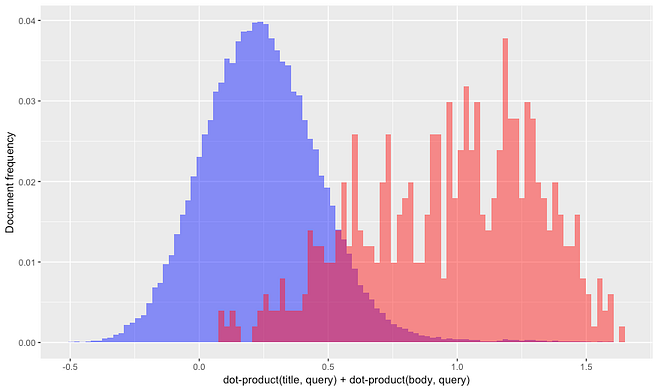
As expected, we got much higher scores on average for relevant documents. Great. Now, let’s look at a similar graph for the BM25 scores. The results are similar but much more extreme in this case. Relevant documents have much higher BM25 scores, to the point where almost no relevant document has low enough signal to be excluded from being retrieved by term-matching signals. This means that, after accounting for term-matching, there are almost no relevant documents left to be matched by semantic signals. This is true even if the semantic embeddings are informative.
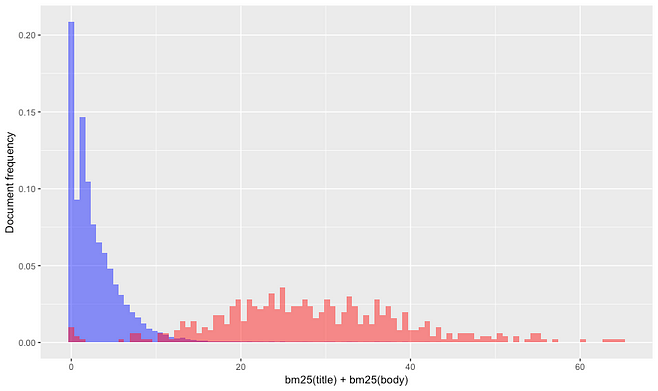
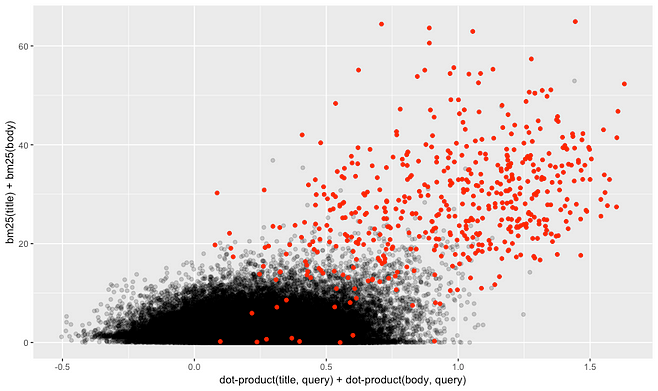
In such a scenario, the best we can hope for is that both signals are positively correlated for relevant documents, showing that both carry information about query-document relevance. This seems indeed to be the case in the scatter plot below that visually shows a much stronger correlation between BM25 scores and embedding scores for the relevant documents (red) than between the scores of the general population (black).
Remarks and conclusion
At this point, a reasonable observation would be that we are talking about pre-trained embeddings and that we could get better results if we fine-tuned the embeddings to the specific application at hand. This might very well be the case but there are at least two important considerations to be taken into account: cost and overfitting. The resource/cost consideration is important but more obvious to be recognized. You either have the money to pursue it or not. If you do, you still should check to see if the improvement you get is worth the cost.
The main issue, in this case, relates to overfitting. It is not easy to avoid overfitting when using big and complex models such as Universal Sentence Encoder and sentence BERT. Even if we use the entire MS MARCO dataset, which is considered a big and important recent developments to help advance the research around NLP tasks, we only have around 3 million documents and 300 thousand labeled queries to work with. This is not necessarily big relative to such massive models.
Another important observation is that BERT-related architectures have dominated the MSMARCO leaderboards for quite some time. Anna Rogers wrote a good piece about some of the challenges involved on the current trend of using leaderboards to measure model performance in NLP tasks. The big takeaway is that we should be careful when interpreting those results as it becomes hard to understand if the performance comes from architecture innovation or excessive resources (read overfitting) being deployed to solve the task.
But despite all those remarks, the most important point here is that if we want to investigate the power and limitations of semantic vectors (pre-trained or not), we should ideally prioritize datasets that are less biased towards term-matching signals. This might be an obvious conclusion, but what is not obvious to us at this moment is where to find those datasets since the bias reported here are likely present in many other datasets due to similar data collection designs.
Thanks to Lester Solbakken and Jon Bratseth.
Bio: Thiago Guerrera Martins (@Thiagogm) is a Principal Data Scientist @ Verizon Media and works on the open-sourced search engine vespa.ai. He has a PhD in Statistics.
Original. Reposted with permission.
Related:
- How To Build Your Own Feedback Analysis Solution
- A simple and interpretable performance measure for a binary classifier
- Tokenization and Text Data Preparation with TensorFlow & Keras