Google Unveils TAPAS, a BERT-Based Neural Network for Querying Tables Using Natural Language
The new neural network extends BERT to interact with tabular datasets.

Querying relational data structures using natural languages has long been a dream of technologists in the space. With the recent advancements in deep learning and natural language understanding(NLU), we have seen attempts by mainstream software packages such as Tableau or Salesforce.com to incorporate natural language to interact with their datasets. However, those options remain extremely limited, constrained specific data structures and hardly resemble a natural language interaction. At the same time, we continue hitting milestones in question-answering models such as Google’s BERT or Microsoft’s Turing-NG. Could we leverage those advancements to interact with tabular data? Recently, Google Research unveiled TAPAS( Table parser), a model based on the BERT architecture that process questions and answers against tabular datasets.
Interacting with tabular data is natural language is one of those scenarios that looks conceptually trivial and results in a nightmare in the real world. Most attempts to solve this issue have been based on semantic parsing methods that process a natural language sentence and generate the corresponding SQL. That approach works in very constrained scenarios but is hardly scalable to real natural language interactions. Let’s take the following example the following datasets of American wrestling champions. The table to the right represents some possible questions that can be executed against that dataset.

Some questions such as #1: “Which wrestler had the most number of reigns?” directly maps to a SQL sentence “SELECT TOP Name ORDER BY No. Of Reigns DESC”. Those queries are easy to process by a semantic parser. However, queries such as #5: “Which of the following wrestlers were ranked in the bottom 3? Out of these, who had more than one reign?” are conversational natural and more difficult to process. Additionally, if you factor in common conversational elements such as ambiguity, long-form sentences or synonymous, just to list a few, you start getting a picture of the complexity of using natural language to interact with tabular data.
The TAPAS Approach
Instead of creating a model that is constrained to a specific table structure, Google decided to follow a more holistic approach building a neural network that can be adapted to any form of a tabular dataset. To accomplish that, Google decided to based TAPAS in its famous BERT encoder architecture that set new records for natural language models a couple of years ago. TAPAS extends the BERT model in four fundamental areas:
- Additional Embeddings
- Cell Selection
- Aggregation-Operation-Prediction
- Inference
Additional Embeddings
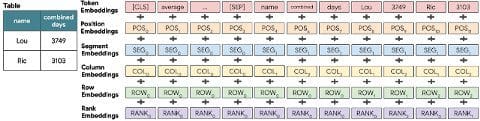
The most notable addition to the base BERT model is the use of extra embeddings for encoding the textual input. Tapas leverages learned embeddings for the row and column indexes as well as for one special rank index that represents the order of elements in numerical columns. More specifically, TAPAS adds the following types of positional embeddings:
- Position ID: Just like BERT, this embedding represents the index of the token in the flattened sequence.
- Segment ID: Encodes a table header as 0 and a table cell as 1.
- Column/Row ID: The index of the column or row containing the token.
- Rank ID: This embedding is designed to process superlative questions from numeric values. If the cell values are numbers, this embedding sorts them and assign them a value based on their numeric rank.
- Previous Answer: This embedding is designed for scenarios such as question #5 that combines multiple questions. Specifically, this embedding indicates whether a cell token was the answer to a previous question.
In TAPAS, every language input is encoded as the sum of the different embeddings that represent word, position and segment as illustrated in the following figure:
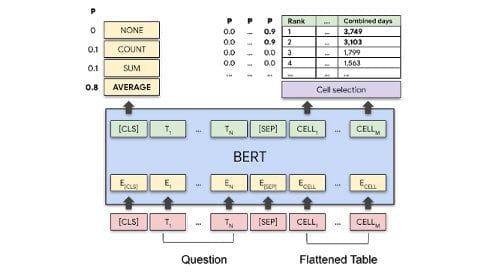
Cell Selection
TAPAS also extends BERT with a classification layer that can select the subset of the table cells and scores the probability that those cells will be in the final answer or they can be used to compute the final answer. This step is important to optimize query processing time.
Aggregation Operation Prediction
TAPAS includes an aggregation operator as part of the output to indicate which mathematical operations such as SUM, COUNT, AVERAGE or others need to be applied to the target cells.
Inference
In the TAPAS model, the data selection is not exact but based on probabilities. TAPAS also extends BERT with an inference layer to predict the most likely outcome of the operators and cells that need to be selected.
You should think about these enhancements about adapting BERT’s state of the art question-answering capabilities to tabular datasets. Let’s go back to our sample wrestling dataset and try to answer the question “Average time as a champion for top 2 wrestlers?” TAPAS uses the base BERT model to encode both the questions and the table. Subsequently, the aggregation-operation prediction layer determines that the AVG operation has a high probability of being used in the answer. Similarly, the cell selection layer detects that cells with the numbers 3,749 and 3,103 also have a high probability to form part of the answer.
Pretraining
To follow BERT’s steps, Google pre-trained TAPAS using a dataset of 6.2 million table-text pairs from the English Wikipedia dataset. The maximum number of cells per table was about 500. Additionally, TAPAS was trained using weak and strong supervision models to learn how to answer questions from a table.
TAPAS in Action
Google evaluated TAPAS using three fundamental datasets: SQA, WikiTableQuestions (WTQ) and WikiSQL and a series of state-of-the-art models trained using them. In all benchmarks, TAPAS showed levels of performance vastly superior to alternatives as shown in the following charts:
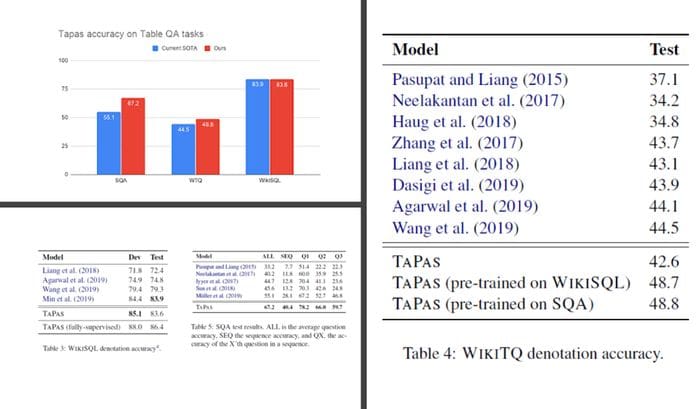
TAPAS is a very interesting approach to leverage natural language to interact with tabular datasets. The results are still highly theoretical and there are questions as to whether this approach will scale to really large datasets. However, the ideas seem to be directionally correct. Leveraging some of the advancements in transformer-based models like BERT to interact with tabular datasets can open new possibilities in the space.
Original. Reposted with permission.
Related:
- BERT, RoBERTa, DistilBERT, XLNet: Which one to use?
- Why BERT Fails in Commercial Environments
- Natural Language Processing Recipes: Best Practices and Examples