Implementing MLOps on an Edge Device
This article introduces developers to MLOps and strategies for implementing MLOps on edge devices.
By Felix Baum, Qualcomm Technologies
The lifecycle of traditional software is arguably quite straight forward. At its simplest, you develop, test, and deploy the software, and then release a new version with features, updates, and/or fixes as needed. To facilitate this, traditional software development often relies on DevOps, which involves Continuous Integration (CI), Continuous Delivery (CD), and Continuous Testing (CT) to reduce development time while continuously delivering new releases and maintaining quality.
When it comes to machine learning (ML) modeling, it’s easy to think that the ML workflow follows a similar pattern. After all, it should just be a matter of creating and training an ML model, deploying it, and releasing a new version as required. But the environment in which ML systems operate complicates things. For starters, the ML systems themselves are inherently different from traditional software due to their data-driven, non-deterministic behaviour. And as recent global events have highlighted, our world is constantly changing, so ML practitioners must anticipate that the real-world data on which production models1 infer, will inevitably change too.
As a result, a special kind of DevOps for ML has emerged, called MLOps (short for “machine learning and operations”), to help manage this constant change and the subsequent need for model redeployments. MLOps embraces DevOps’ continuous integration and continuous delivery, but replaces the continuous testing phase with continuous training. This continuous training of new models, which includes redeployment of those new models and all of the technical efforts that go along with it, aims to address three notable aspects of ML projects:
- The need for “explainability” as to how and why a model makes certain predictions. This is especially important for auditing purposes to meet regulations and/or certain levels of predictive performance.
- Model decay, which is the reduction of the production model’s predictive performance over time, due to new and changing real-world data encountered by the model.
- The continuous development and enhancements to the model driven by business requirements.
Continuous training, and indeed MLOps in general, embrace the idea that the model will constantly and inevitably change, which means organizations implement MLOps strategies and tactics to varying degrees.
As MLOps have evolved, a number of organizations have put forth frameworks for best practices. One prominent example is Google’s MLOps guidelines which describes three levels of MLOps implementations adopted by organizations:
- MLOps level 0: Manual Process: the need for model training and deployment are formally recognized, but are performed manually, often in an ad-hoc fashion through scripts and interactive processes. This level generally lacks continuous integration and continuous delivery.
- MLOps level 1: ML pipeline automation: this level introduces a pipeline for continuous training. Data and model validation are automated, and triggers are in place to retrain the model with fresh data when its performance degrades.
- MLOps level 2: CI/CD pipeline automation: the ML workflow has been automated to the point where data scientists are able to update both the model and pipeline with reduced intervention from developers.
Organizations that have implemented MLOps level 2 or MLOps level 3 may even make use of so called “shadow models”, which are models that are trained in parallel while the production model runs, using a different training dataset for each. When a new production model is needed, a shadow model can be quickly selected and deployed.
To better understand how and when these different levels of MLOps can be implemented, consider the following examples.
Example 1: Packaging Robots
A simple example is a robot at the end of an assembly line, that uses computer vision powered by ML to analyze and package up products. The ML model may have been trained to recognize square and rectangular boxes of a limited range of sizes. However, the business will now introduce new shapes and sizes for its packages, so a new ML model is created and deployed. In this scenario a development team at MLOps level 0 would manually create, train, and deploy a new model, pre-emptively before the new types of packages start rolling down the assembly line. Given the limited domain of the robot’s capabilities, this level of MLOps may suffice.
Example 2: Speech Recognition
Consider a mobile app for speech recognition that can sense or identify context (e.g., tone or emotion) based on how people speak. Over time, new phrases and slangs come along, and the general style of how people talk changes. In this scenario an ML model will likely exhibit model decay over a long period of time.
This is an example where the guidelines of MLOps level 1 could potentially help. Under MLOps level 1, a system could be run on the device, to monitor the model’s predictive performance. If performance approaches or falls below a threshold, the system triggers an alert to the team that a new model should be trained using fresh data, and then deployed to replace the production model.
Example 3: Sudden Outliers in the Stock Market
Earlier this year, the price of oil entered negative territory. If an ML model makes predictions based on the price of oil but has only been trained with positive prices, how will it perform when it suddenly encounters a negative stock price? In this situation, team members will need to be alerted to the problem immediately, and must be in a position to quickly train and redeploy a new model.
Here, an implementation of MLOps level 2 could be beneficial. At this level, much of the pipeline for training and deploying a new model has been automated, so data scientists should be able to handle most or all of the pipeline without developer assistance. Moreover, the degree of automation should allow them to focus updating, training, and deploying a new model as quickly and as reliably as possible.
Implementing MLOps For Edge Devices
Many of today’s premium edge devices are well positioned for MLOps. Not only are they more than capable of hosting large models, but they are often equipped with specialized vector processors optimized to run inference. On such example is the Hexagon Digital Signal Processor (DSP) found on the Qualcomm® Snapdragon™ line of mobile platforms which powers many of today’s premium devices2. In addition, such processors are usually backed by a rich SDK and toolset for artificial intelligence (AI), that developers use to optimize and load models onto the device. It is these SDKs and tools that can be integrated into an MLOps pipeline to facilitate the model deployment process.
The general process for working with the SDK in the context of the ML workflow is as follows:
- The ML model is designed and trained using a framework such as TensorFlow.
- The converter tool in the Qualcomm Neural Processing SDK is used to convert that model to a proprietary format, optimized for execution on Snapdragon.
- API calls from the Qualcomm Neural Processing SDK are added to the app to load the data onto the Qualcomm® Hexagon™ processor and to run inference.
- Once loaded and the app is running, the model has been deployed to edge for inference on real-world data.

In the context of MLOps, steps 1, 2, and 4 from above, would be repeated throughout the product’s lifecycle as model updates are required. And depending on the level of MLOps that has been implemented, developers may build additional entities such as monitoring tools, that run on the edge device to gauge the model’s predictive performance. They may also build some sort of alert and/or trigger that can start a new iteration of the ML workflow.
A Closer Looks at MLOps Pipeline
Looking at this a bit closer, there are a number of tools and phases to integrate into an MLOps pipeline model deployment script. The following shows an example pipeline built on the Qualcomm Neural Processing SDK:
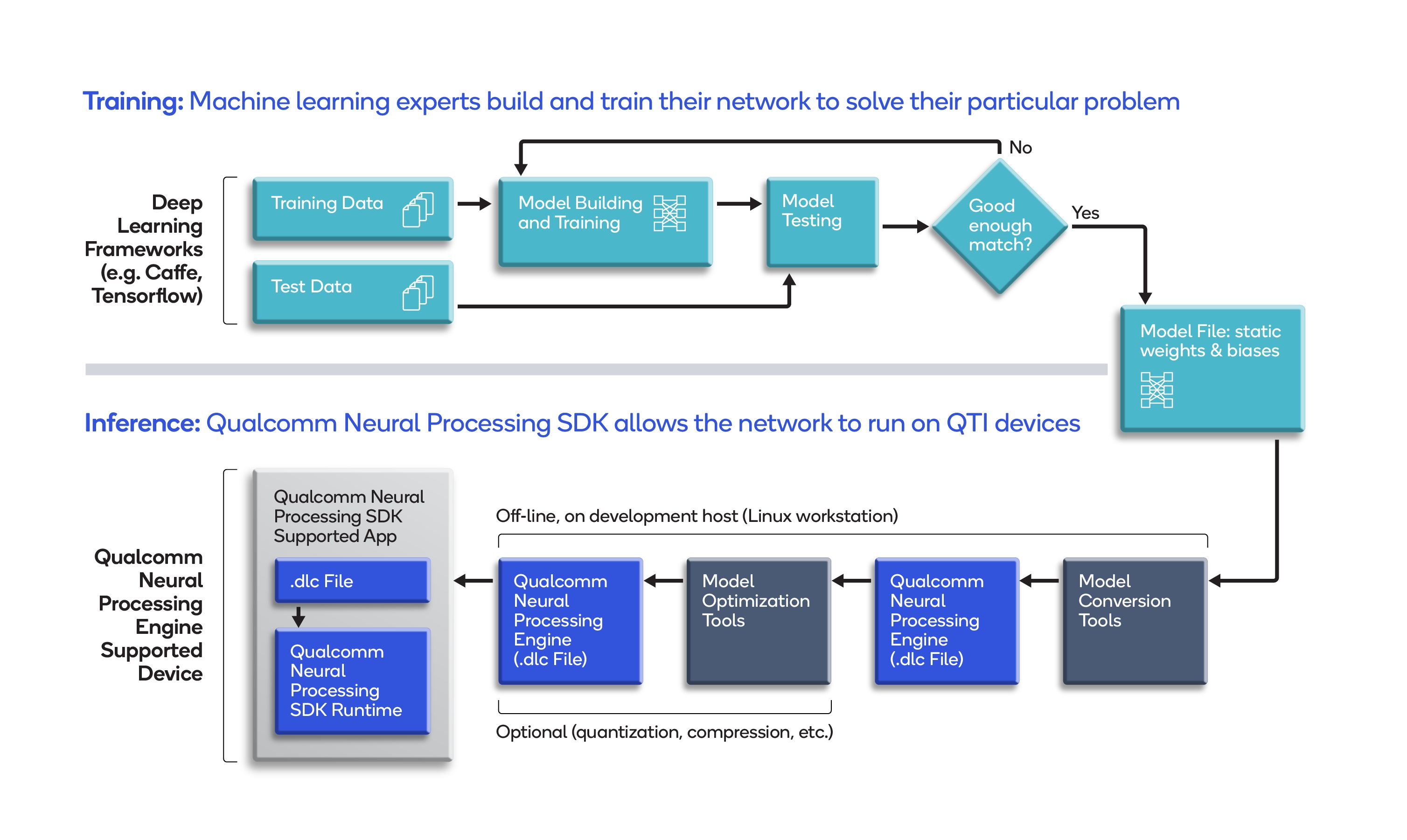
In the upper half of the workflow, an ML model is trained in an ML framework. In the lower half of the workflow, the SDK’s tools are used to convert the model to edge device’s proprietary format, and optionally, to optimize the model for the edge device. In the context of MLOps, it’s these tools that would be invoked either manually or as part of automated build scripts.
Developers can also implement different methods to reload a new model into the app running on the edge device. One method is to run services on the device that automatically pull down the new model and restart the app (or even restart the whole device) with new model, but that could disrupt service while the restart is in progress. Alternatively, the app itself could watch for the presence of new model files at runtime, and re-invoke the necessary APIs to load the new model. Yet another option is to use a push approach, in which over-the-air updates initiated by a server push a new model to the device.
Depending on the app’s architecture, each of these options may incur different levels of downtime as the model is deployed and the app switches to using it. Developers will therefore need to weigh the complexity of implementing each technique, with the potential downtime required to deploy a new model.
Conclusion
ML systems are inherently different to traditional software because they are non-deterministic, and operate in a world of constantly-evolving, ever-changing data. But thanks to formal methodologies like MLOps, developers have the tools they need to strategize and implement robust ML solutions.
With ML gaining such prominence in edge computing on so many devices today, it’s exciting to see how this hardware, in conjunction with their SDKs and tools, can support an effective MLOps pipeline.
- A production model refers to the ML model that has been deployed for inference on real-world data.
- https://www.statista.com/statistics/233415/global-market-share-of-applications-processor-suppliers/
Bio: Felix Baum manages the digital signal processor (DSP) software products for Qualcomm Technologies and is instrumental in supporting Hexagon DSP in connectivity, audio, voice, sensor fusion, computer vision and machine learning use cases.
Original. Reposted with permission.
Related:
- Taming Complexity in MLOps
- Demystifying the AI Infrastructure Stack
- A Tour of End-to-End Machine Learning Platforms