Working with Spark, Python or SQL on Azure Databricks
Here we look at some ways to interchangeably work with Python, PySpark and SQL using Azure Databricks, an Apache Spark-based big data analytics service designed for data science and data engineering offered by Microsoft.
By Ajay Ohri, Data Science Manager
Azure Databricks is an Apache Spark-based big data analytics service designed for data science and data engineering offered by Microsoft. It allows collaborative working as well as working in multiple languages like Python, Spark, R and SQL. Working on Databricks offers the advantages of cloud computing - scalable, lower cost, on demand data processing and data storage.
Here we look at some ways to interchangeably work with Python, PySpark and SQL. We learn how to import in data from a CSV file by uploading it first and then choosing to create it in a notebook. We learn how to convert an SQL table to a Spark Dataframe and convert a Spark Dataframe to a Python Pandas Dataframe. We also learn how to convert a Spark Dataframe to a Permanent or Temporary SQL Table.
Why do we need to learn how to interchange code between SQL, Spark and Python Panda Dataframe? SQL is great for easy writing and readable code for data manipulation, Spark is great for speed for big data as well as Machine Learning, while Python Pandas can be used for everything from data manipulation, machine learning as well as plotting in seaborn or matplotlib libraries.
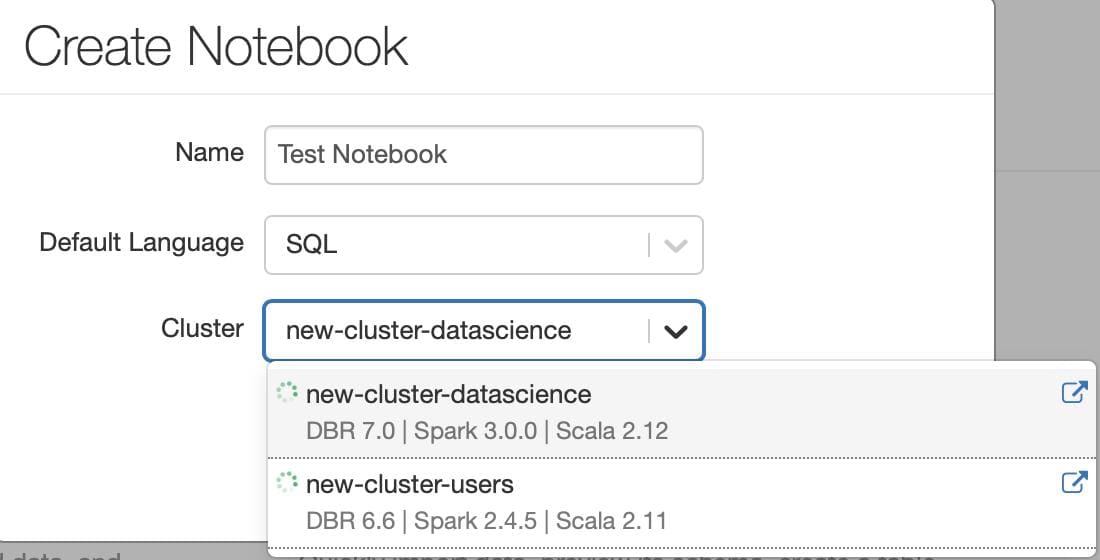
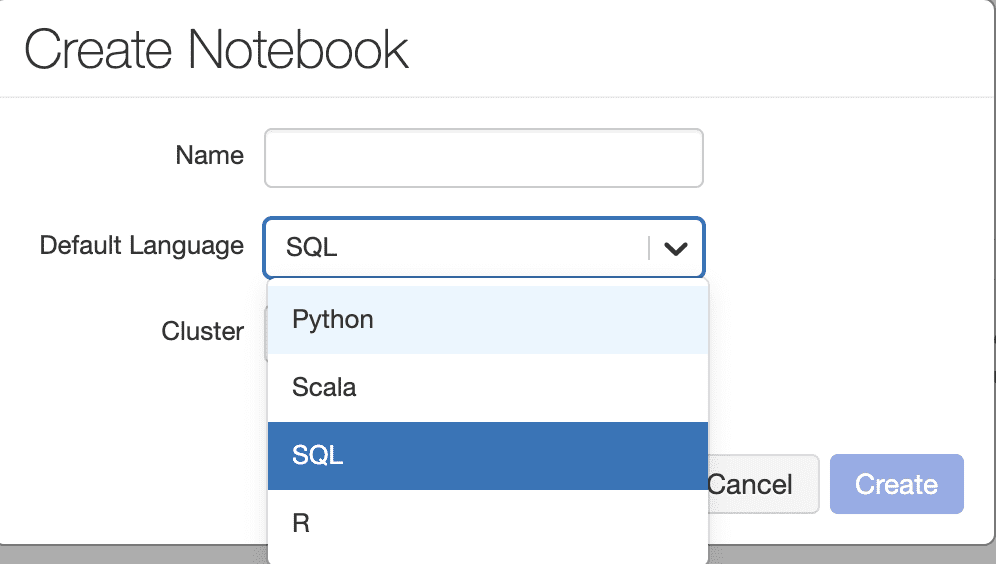
We choose a SQL notebook for ease and then we choose appropriate cluster with appropriate RAM, Cores, Spark version etc. Even though it is a SQL notebook we can write python code by typing %python in front of code in that cell.
Now let's begin the basics of data input, data inspection and data interchange
Step 1 Reading in Uploaded Data
%python
# Reading in Uploaded Data
# File location and type
file_location = "/FileStore/tables/inputdata.csv"
file_type = "csv"
# CSV options
infer_schema = "false"
first_row_is_header = "true"
delimiter = ","
# The applied options are for CSV files. For other file types, these will be ignored.
df = spark.read.format(file_type) \
.option("inferSchema", infer_schema) \
.option("header", first_row_is_header) \
.option("sep", delimiter) \
.load(file_location)
display(df)
Step 2 Create a temporary view or table from SPARK Dataframe
%python #Create a temporary view or table from SPARK Dataframe temp_table_name = "temp_table" df.createOrReplaceTempView(temp_table_name)
Step 3 Creating Permanent SQL Table from SPARK Dataframe
--Creating Permanent SQL Table from SPARK Dataframe
permanent_table_name = "cdp.perm_table"
df.write.format("parquet").saveAsTable(permanent_table_name)
Step 4 Inspecting SQL Table
--Inspecting SQL Table select * from cdp.perm_table
Step 5 Converting SQL Table to SPARK Dataframe
%python
#Converting SQL Table to SPARK Dataframe
sparkdf = spark.sql("select * from cdp.perm_table")
Step 6 Inspecting SPARK Dataframe
%python #Inspecting Spark Dataframe sparkdf.take(10)
Step 7 Converting Spark Dataframe to Python Pandas Dataframe
%python #Converting Spark Dataframe to Python Pandas Dataframe %python pandasdf=sparkdf.toPandas()
Step 8 Inspecting Python Dataframe
%python #Inspecting Python Dataframe pandasdf.head()
References
- Introduction to Azure Databricks - https://www.slideshare.net/jamserra/introduction-to-azure-databricks-83448539
- Dataframes and Datasets - https://docs.databricks.com/spark/latest/dataframes-datasets/index.html
- Optimize conversion between PySpark and pandas DataFrames - https://docs.databricks.com/spark/latest/spark-sql/spark-pandas.html
- pyspark package - https://spark.apache.org/docs/latest/api/python/pyspark.html
Bio: Ajay Ohri is Data Science Manager (Publicis Sapient) and author of 4 books on data science including R for Cloud Computing and Python for R Users.
Related: