A Deep Learning Dream: Accuracy and Interpretability in a Single Model
IBM Research believes that you can improve the accuracy of interpretable models with knowledge learned in pre-trained models.

I recently started a new newsletter focus on AI education. TheSequence is a no-BS( meaning no hype, no news etc) AI-focused newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers and concepts. Please give it a try by subscribing below:

Machine learning is a discipline full of frictions and tradeoffs but none more important like the balance between accuracy and interpretability. In principle, highly accurate machine learning models such as deep neural networks tend to be really hard to interpret while simpler models like decision trees fall short in many sophisticated scenarios. Conventional machine learning wisdom tell us that accuracy and interpretability are opposite forces in the architecture of a model but its that always the case? Can we build models that are both highly performant and simple to understand? An interesting answer can be found in a paper published by researchers from IBM that proposes a statistical method for improving the performance of simpler machine learning models using the knowledge from more sophisticated models.
Finding the right balance between performance and interpretability in machine learning models is far from being a trivial endeavor. Psychologically, we are more attracted towards things we can explain while the homo- economicus inside us prefers the best outcome for a given problem. Many real world data science scenarios can be solved using both simple and highly sophisticated machine learning models. In those scenarios, the advantages of simplicity and interpretability tend to outweigh the benefits of performance.
The Advantages of Machine Learning Simplicity
The balance between transparency and performance can be described as the relationship between research and real world applications. Most artificial intelligence(AI) research these days is focused on uberly sophisticated disciplines such as reinforcement learning or generative models. However, when comes to practical applications the trust in simpler machine learning models tend to prevail. We see this all the time with complex scenarios in computational biology and economics being solved using simple sparse linear models or complex instrumented domains such as semi-conductor manufacturing addressed using decision trees. There are many practical advantages to simplicity in machine learning models that can’t be easily overlooked until you are confronted with a real world scenario. Here are some of my favorites:
- Small Datasets: Companies usually have limited amounts of usable data collected for their business problems. As such, simple models are many times preferred here as they are less likely to overfit the data and in addition can provide useful insight.
- Resource-Limited Environments: Simple models are also useful in settings where there are power and memory constraints.
- Trust: Simpler models inspired trust in domain experts which are often responsible for the results of the models.
Despite the significant advantages of simplicity in machine learning models, we can’t simply neglect the benefits of top performant models. However, what if we could improve the performance of simpler machine learning models using the knowledge from more sophisticated alternatives? This is the path that IBM researchers decided to follow with a new method called ProfWeight.
ProfWeight
The idea behind ProfWeight is incredibly creative to the point of resulting counter intuitive to many machine learning experts. Conceptually, ProfWeight transfers information from a pre-trained deep neural network that has a high test accuracy to a simpler interpretable model or a very shallow network of low complexity and a priori low test accuracy. In that context, ProfWeight uses a sophisticated deep learning model as a high-performing teacher which lessons can be used to teach the simple, interpretable, but generally low-performing student model.
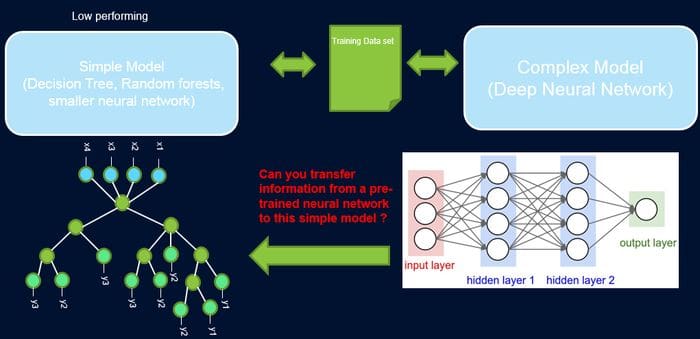
To implement the knowledge transfer between the teacher and student models, ProfWeight introduces probes which are weights in samples according to the difficulty of the network to classify them. Each probe takes its input from one of the hidden layers and processes it through a single fully connected layer with a softmax layer in the size of the network output attached to it. The probe in a specific layer serves as a classifier that only uses the prefix of the network up to that layer. Despite its complexity, ProfWeight can be summarized in four main steps:
- Attach and train probes on intermediate representations of a high performing neural network.
- Train a simple model on the original dataset.
- Learn weights for examples in the dataset as a function of the simple model and the probes.
- Retrain the simple model on the final weighted dataset.
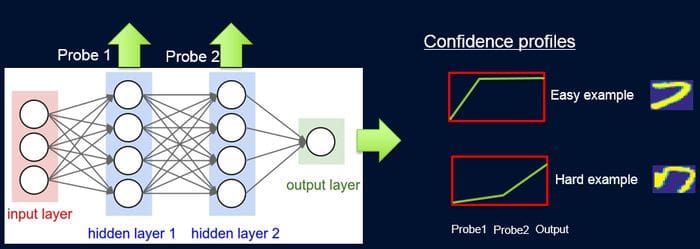
The entire ProfWeight model can be seen as a pipeline of probing, obtaining confidence weights, and re-training. For computing the weights, the IBM team used different techniques such as area under the curve(AUC) or rectified linear units(ReLu).
The Results
IBM tested ProfWeight across different scenarios and benchmarked the results against traditional models. One of those experiments focused on measuring the quality of metal produced in a manufacturing plant. The input dataset consist of different measurements during a metal manufacturing process such as acid concentrations, electrical readings, metal deposition amounts, time of etching, time since last cleaning, glass fogging and various gas flows and pressures. The simple model used by ProfWeight was a decision tree algorithm. For the complex teacher model was, IBM used a deep neural network with an input layer and five fully connected hidden layers of size 1024 which have shown accuracy of over 90% in this specific scenario. Using different variations of ProfWeight, the accuracy of the decision tree model improved from 74% to over 87% while maintaining the same levels of interpretability.
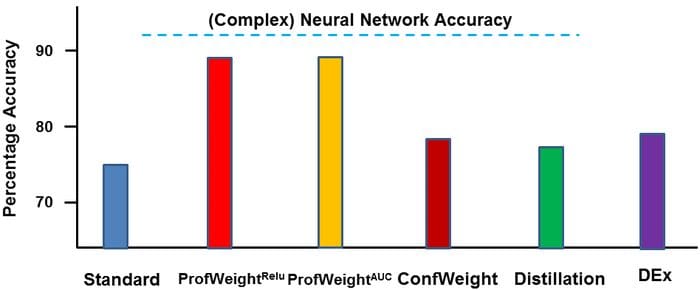
ProfWeight is one of the most creative approaches I’ve seen that try to solve the dilemma between transparency and performance in machine learning models. The results of ProfWeight showed that it might be possible to improve the performance of simpler machine learning model using the knowledge of complex alternatives. This work could be the basics for bridging different schools of thought in machine learning such as deep learning and statistical models.
Original. Reposted with permission.
Related:
- Microsoft’s DoWhy is a Cool Framework for Causal Inference
- A Curious Theory About the Consciousness Debate in AI
- DeepMind’s Three Pillars for Building Robust Machine Learning Systems