6 Lessons Learned in 6 Months as a Data Scientist
When transitioning into a Data Science career, a new mindset toward collaboration, data, and reporting is required. Learn from these recommendations on approaches you should consider to successfully develop into your dream job.

Photo by Artem Beliaikin on Unsplash.
Since my title flipped from consultant to data scientist six months ago, I’ve experienced a higher level of job satisfaction than I would have thought possible. To celebrate my first half year in this engaging field, here are six lessons I’ve collected along the way.
#1 — Read the arXiv paper
Probably you’re aware that reviewing arXiv is a good idea. It’s a wellspring of remarkable ideas and state-of-the-art advancements.
I’ve been pleasantly surprised, though, by the amount of actionable advice I come across on the platform. For example, I might not have access to 16 TPUs and $7k to train BERT from scratch, but the recommended hyperparameter settings from the Google Brain team are a great place to start fine-tuning (check Appendix A.3).
Hopefully, your favorite new package will have an enlightening read on arXiv to add color to its documentation. For example, I learned to deploy BERT using the supremely readable and abundantly useful write-up on ktrain, a library that sits atop Keras and provides a streamlined machine learning interface for text, image, and graph applications.
#2 — Listen to podcasts for tremendous situational awareness
Podcasts won’t improve your coding skills but will improve your understanding of recent developments in machine learning, popular packages and tools, unanswered questions in the field, new approaches to old problems, underlying psychological insecurities common across the profession, etc.
The podcasts I listen to on the day-to-day have helped me feel engaged and up-to-date on fast-moving developments in data science.
Here are my favorite podcasts right now: Resources to Supercharge your Data Science Learning in 2020
Recently I’ve been particularly excited to learn about advancements in NLP, follow the latest developments in GPUs and cloud computing, and question the potential symbiosis between advancements in artificial neural nets and neurobiology.
#3 — Read GitHub Issues
Based on my experience trawling this ocean of complaints for giant tuna of wisdom, here are three potential wins:
- I often get ideas from the ways others are using and/or misusing a package.
- It’s also useful to understand in what kinds of situations a package will tend to break in order to develop your sense of potential failure points in your own work.
- As you’re in your pre-work phase of setting up your environment and conducting model selection, you’d do well to take the responsiveness of developers and the community into account before adding an open source tool into your pipeline.
#4 — Understand the algorithm-hardware link
I’ve done a lot of NLP in the last six months, so let’s talk about BERT again.
In October 2018, BERT emerged and shook the world. Kind of like Superman after leaping a tall building in a single bound (crazy to think Superman couldn’t fly when originally introduced!)
BERT represented a step-change in the capacity of machine learning to tackle text processing tasks. Its state-of-the-art results are based in the parallelism of its transformer architecture running on Google’s TPU computer chip.

The feeling of training on GPUs for the first time. via GIPHY.
Understanding the implications of TPU and GPU-based machine learning is important for advancing your own capabilities as a data scientist. It is also a critical step toward sharpening your intuition about the inextricable link between machine learning software and the physical constraints of the hardware on which it runs.
With Moore’s law petering out around 2010, increasingly creative approaches will be needed to overcome the limitations in the data science field and continue to make progress toward truly intelligent systems.
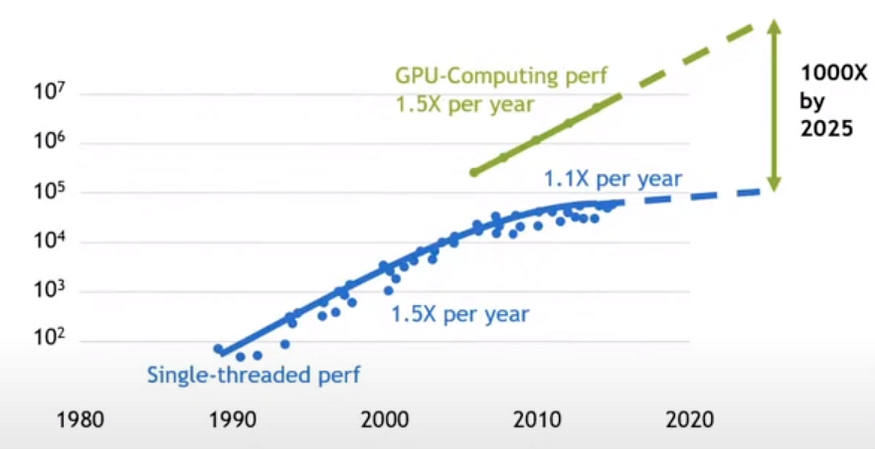
Chart from Nvidia presentation showing transistors per square millimeter by year. This highlights the stagnation in transistor count around 2010 and the rise of GPU-based computing.
I’m bullish on the rise of ML model-computing hardware co-design, increased reliance on sparsity and pruning, and even “no-specialized hardware” machine learning that looks to disrupt the dominance of the current GPU-centric paradigm.
#5 — Learn from the Social Sciences
There’s a lot our young field can learn from the reproducibility crisis in the Social Sciences that took place in the mid-2010s (and which, to some extent, is still taking place):

“p-value hacking” for data scientists. Comic by Randall Monroe of xkcd.
In 2011, an academic crowdsourced collaboration aimed to reproduce 100 published experiments and correlational psychological studies. And it failed — just 36% of the replications reported statistically significant results, compared to 97% of the originals.
Psychology’s reproducibility crisis reveals the danger, and responsibility, associated with sticking “science” alongside shaky methodology.
Data science needs testable, reproducible approaches to its problems. To eliminate p-hacking, data scientists need to set limits on how they investigate their data for predictive features and on the number of tests they run to evaluate metrics.
There are many tools that can help with experimentation management. I have experience with ML Flow — this excellent article by Ian Xiao mentions six others — as well as suggestions across four other areas of the machine learning workflow.
We can also draw many lessons from the fair share of missteps and algorithmic malpractice within the data science field in recent years.
For example, interested parties need to look no further than social engineering recommendation engines, discriminatory credit algorithms, and criminal justice systems that deepen the status quo. I’ve written a bit about these social ills and how to avoid them with effective human-centered design.
The good news is that there are many intelligent and driven practitioners working to address these challenges and prevent future breaches in public trust. Check out Google’s PAIR, Columbia’s FairTest, and IBM’s Explainability 360. Collaborations with social scientist researchers can yield fruitful results, such as this project on algorithms to audit for discrimination.
Of course, there are many other things we can learn from the social sciences, such as how to give an effective presentation.
It’s crucial to study the social sciences to understand where human intuition about data inference is likely to fail. Humans are very good at drawing conclusions from data in certain situations. The ways our reasoning breaks down is highly systematic and predictable.
Much of what we understand about this aspect of human psychology is captured in Daniel Kahneman’s excellent Thinking Fast and Slow. This book should be required reading for anyone interested in decision sciences.
One element of Kahneman’s research that’s likely to be immediately relevant to your work is his treatment of the anchoring effect, which “occurs when people consider a particular value for an unknown quantity.”
When communicating results from modeling (i.e., numbers representing accuracy, precision, recall, f-1, etc.), data scientists need to take special care to manage expectations. It can be useful to provide a degree of hand-waviness on a scale of “we are still hacking away at this problem, and these metrics are likely to change” to “this is the final product, and this is about how we expect our ML solution to perform in the wild.”
If you’re presenting intermediate results, Kahneman would recommend providing a range of values for each metric, rather than specific digits. For example, “The f-1 score, which represents the harmonic mean of other metrics represented in this table (precision and recall), falls roughly between 80–85%. This indicates some room for improvement.” This “hand-wavy” communication strategy decreases the risk that the audience will anchor on the specific value you’re sharing, rather than gain a directionally correct message about the results.
#6 — Connect data to business outcomes
Before you start work, make sure that the problem you’re solving is worth solving.
Your organization isn’t paying you to build a model with 90% accuracy, write them a report, piddle around in Jupyter Notebook, or even to enlighten yourself and others on the quasi-magical properties of graph databases.
You’re there to connect data to business outcomes.
Original. Reposted with permission.
Bio: Nicole Janeway Bills is a machine learning engineer with experience in commercial consulting with proficiency in Python, SQL, and Tableau, as well as business experience in natural language processing (NLP), cloud computing, statistical testing, pricing analysis, and ETL processes. Nicole focuses on connecting data with business outcomes and continues to develop personal technical skillsets.
Related: