 State of Data Science and Machine Learning 2020: 3 Key Findings
State of Data Science and Machine Learning 2020: 3 Key Findings
 State of Data Science and Machine Learning 2020: 3 Key Findings
State of Data Science and Machine Learning 2020: 3 Key FindingsKaggle recently released its State of Data Science and Machine Learning report for 2020, based on compiled results of its annual survey. Read about 3 key findings in the report here.
Kaggle recently released the most results of its annual State of Data Science and Machine Learning survey for 2020.
For the fourth year, Kaggle surveyed its community of data enthusiasts to share trends within a quickly growing field. Based on responses from 20,036 Kaggle members, we’ve created this report focused on the 13% (2,675 respondents) who are currently employed as data scientists.
The overview of the report can be viewed online here. Alternatively, you can look at the survey's executive summary, or view and interact with the survey's raw data.
While we recommend everyone take the time to look over the results in detail on their own, here we bring you 3 key findings highlighted in the survey's report.
1. Salary Gap
Pay for data scientists is covered in the report starting on page 11. Apples to apples comparisons are made of salary distributions for both US and India based data scientists, as are more difficult global distributions and median salaries by a number of select countries. While these apples to oranges comparisons are much less straight forward — considerations such as national cost of living differences and differences between data scientist pay distributions and distributions for all national professions are clearly not considered — the median salary for data scientists by country on page 14 nonetheless demonstrates a dramatic gap in global data scientist salaries.
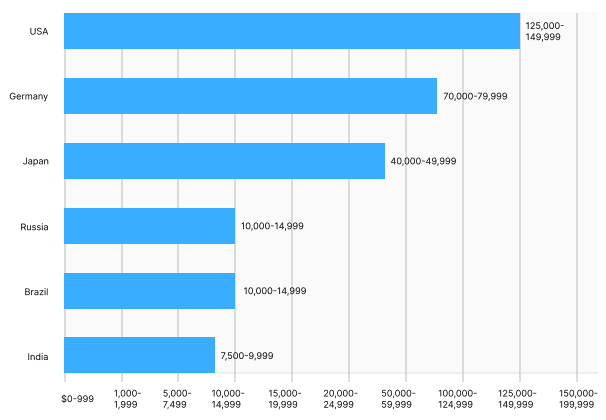
Looking at the most common salaries by country, we see that US companies are more likely to pay higher salaries. Companies in Germany and Japan follow, with significantly higher salaries than the other included regions.
Recalling that this is a compilation of survey responses, this is simply a reporting of raw data. If anyone was so interested, the raw data could be leveraged to perform a more in-depth and nuanced analysis and comparison of global data scientist salaries.
2. JupyterLab is the Main Development Environment
This should come as little surprise to many, but JupyterLab retains the top spot for most-used interactive development environment, with 74.1% of respondents reporting using it.
Jupyter-based IDEs continue to be the go-to tool for data scientists, with around three-quarters of Kaggle data scientists using it. However, this has decreased from last year’s 83%. Visual Studio Code is in the second spot with just over 33%.

The rest of the list contains a mix of mostly Python based IDEs and multipurpose text editors, alongside RStudio and MATLAB. This list could provide some evidence of Python's relative dominance in the field, but also remind us of R's continued strong position, as well as MATLAB's persistence. We can also confirm that more traditional IDEs are not leveraged heavily in data science and machine learning, perhaps not as heavily as they may be in other programming disciplines — though we do not have such data readily available for comparison.
3. Top Methods & Algorithms
Page 19 of the report displays the top used methods and algorithms in data science.
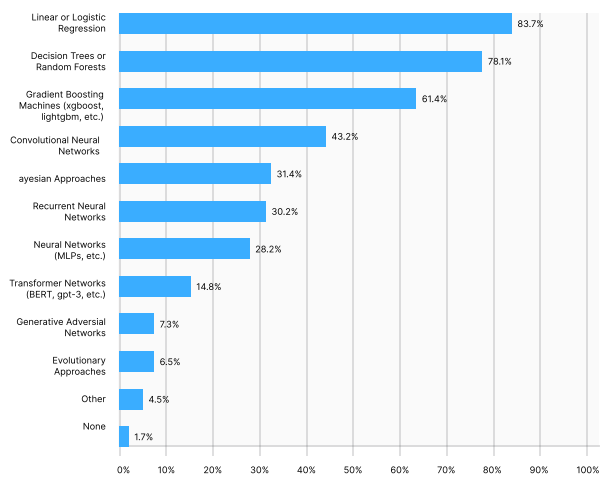
The most commonly used algorithms were linear and logistic regression, followed closely by decision trees and random forests. Of more complex methods, gradient boosting machines and convolutional neural networks were the most popular approaches.
Unsurprisingly, linear regression, logistic regression, various decision tree methods, and gradient boosting machines take the top spots. The next tier of methods consists of a number of neural network architectures alongside Bayesian method. Finally, specialized neural network architectures such as transformers and GANs, as well as evolutionary approaches, round out the list.
Don't forget to have a look at the entire report for yourself, to find out more about additional topics such as the data scientist profile, data science teams, enterprise machine learning adoption, automated machine learning usage, and more. And don't forget that the raw data is available for those interested in munging and exploring.
Related:
- Top Data Science and Machine Learning Methods Used in 2018, 2019
- Machine Learning is Happening Now: A Survey of Organizational Adoption, Implementation, and Investment
- International alternatives to Kaggle for Data Science / Machine Learning competitions