A Beginner’s Guide to the CLIP Model
CLIP is a bridge between computer vision and natural language processing. I'm here to break CLIP down for you in an accessible and fun read! In this post, I'll cover what CLIP is, how CLIP works, and why CLIP is cool.
By Matthew Brems, Growth Manager @ Roboflow
You may have heard about OpenAI's CLIP model. If you looked it up, you read that CLIP stands for "Contrastive Language-Image Pre-training." That doesn't immediately make much sense to me, so I read the paper where they develop the CLIP model – and the corresponding blog post.
I'm here to break CLIP down for you in a – hopefully – accessible and fun read! In this post, I'll cover:
- what CLIP is,
- how CLIP works, and
- why CLIP is cool.
What is CLIP?
CLIP is the first multimodal (in this case, vision and text) model tackling computer vision and was recently released by OpenAI on January 5, 2021. From the OpenAI CLIP repository, "CLIP (Contrastive Language-Image Pre-Training) is a neural network trained on a variety of (image, text) pairs. It can be instructed in natural language to predict the most relevant text snippet, given an image, without directly optimizing for the task, similarly to the zero-shot capabilities of GPT-2 and 3."
Depending on your background, this may make sense -- but there's a lot in here that may be unfamiliar to you. Let's unpack it.
- CLIP is a neural network model.
- It is trained on 400,000,000 (image, text) pairs. An (image, text) pair might be a picture and its caption. So this means that there are 400,000,000 pictures and their captions that are matched up, and this is the data that is used in training the CLIP model.
- "It can predict the most relevant text snippet, given an image." You can input an image into the CLIP model, and it will return for you the likeliest caption or summary of that image.
- "without directly optimizing for the task, similarly to the zero-shot capabilities of GPT-2 and 3." Most machine learning models learn a specific task. For example, an image classifier trained on classifying dogs and cats is expected to do well on the task we've given it: classifying dogs and cats. We generally would not expect a machine learning model trained on dogs and cats to be very good at detecting raccoons. However, some models -- including CLIP, GPT-2, and GPT-3 -- tend to perform well on tasks they aren't directly trained to do, which is called "zero-shot learning."
- "Zero-shot learning" is when a model attempts to predict a class it saw zero times in the training data. So, using a model trained on exclusively cats and dogs to then detect raccoons. A model like CLIP, because of how it uses the text information in the (image, text) pairs, tends to do really well with zero-shot learning -- even if the image you're looking at is really different from the training images, your CLIP model will likely be able to give a good guess for the caption for that image.
To put this all together, the CLIP model is:
- a neural network model built on hundreds of millions of images and captions,
- can return the best caption given an image, and
- has impressive "zero-shot" capabilities, making it able to accurately predict entire classes it's never seen before!
When I wrote my Introduction to Computer Vision post, I described computer vision as "the ability for a computer to see and understand what it sees in manner similar to humans."
When I've taught natural language processing, I described NLP in a similar way: "the ability for a computer to understand language in manner similar to humans."
CLIP is a bridge between computer vision and natural language processing.
It's not just a bridge between computer vision and natural language processing -- it's a very powerful bridge between the two that has a lot of flexibility and a lot of applications.
How does CLIP work?
In order for images and text to be connected to one another, they must both be embedded. You've worked with embeddings before, even if you haven't thought of it that way. Let's go through an example. Suppose you have one cat and two dogs. You could represent that as a dot on a graph, like below:
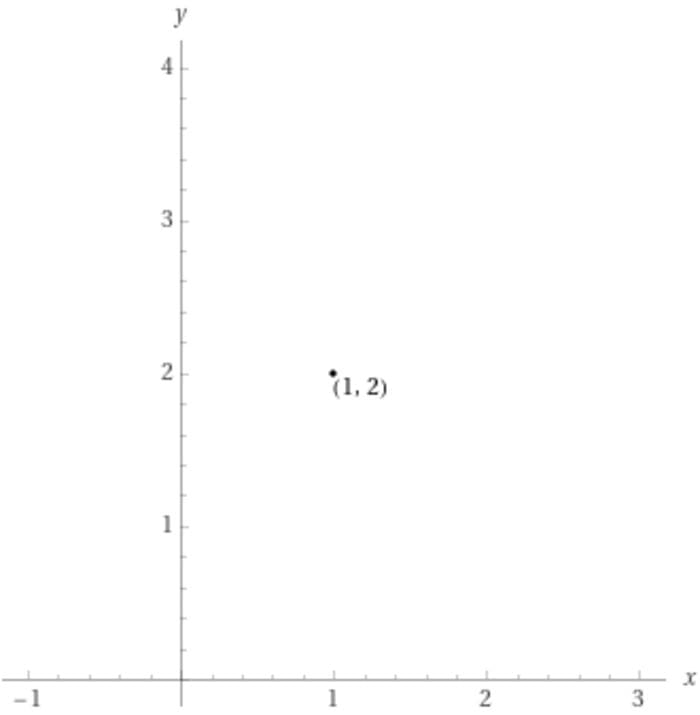
Embedding of "1 cat, 2 dogs." (Source.)
It may not seem very exciting, but we just embedded that information on the X-Y grid that you probably learned about in middle school (formally called Euclidean space). You could also embed your friends' pet information on the same graph and/or you could have chosen plenty of different ways to represent that information (e.g. put dogs before cats, or add a third dimension for raccoons).
I like to think of embedding as a way to smash information into mathematical space. We just took information about dogs and cats and smashed it into mathematical space. We can do the same thing with text and with images!
The CLIP model consists of two sub-models called encoders:
- a text encoder that will embed (smash) text into mathematical space.
- an image encoder that will embed (smash) images into mathematical space.
Whenever you fit a supervised learning model, you have to find some way to measure the "goodness" or the "badness" of that model – the goal is to fit a model that is as "most good" and "least bad" as possible.
The CLIP model is no different: the text encoder and image encoder are fit to maximize goodness and minimize badness.
So, how do we measure "goodness" and "badness?"
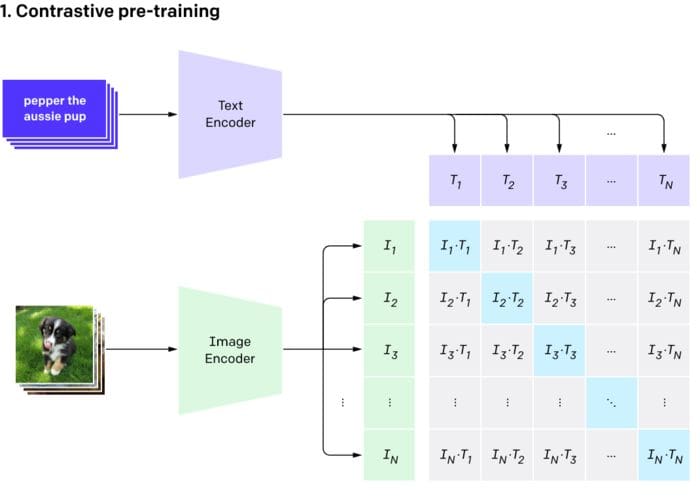
In the image below, you'll see a set of purple text cards going into the text encoder. The output for each card would be a series of numbers. For example, the top card, pepper the aussie pup would enter the text encoder – the thing smashing it into mathematical space – and come out as a series of numbers like (0, 0.2, 0.8).
The exact same thing will happen for the images: each image will go into the image encoder and the output for each image will also be a series of numbers. The picture of, presumably Pepper the Aussie pup, will come out like (0.05, 0.25, 0.7).
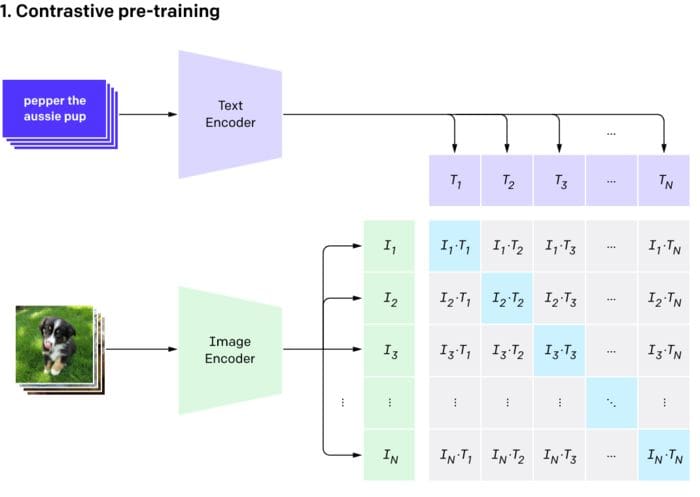
The pre-training phase. (Source.)
"Goodness" of our model
In an ideal world, the series of numbers for the text "pepper the aussie pup" will be very close (identical) to the series of numbers for the corresponding image. In fact, this should be the case everywhere: the series of numbers for the text should be very close to the series of numbers for the corresponding image. One way for us to measure "goodness" of our model is how close the embedded representation (series of numbers) for each text is to the embedded representation for each image.
There is a convenient way to calculate the similarity between two series of numbers: the cosine similarity. We won't get into the inner workings of that formula here, but rest assured that it's a tried and true method of seeing how similar two vectors, or series of numbers, are. (Though it isn't the only way!)
In the image above, the light blue squares represent where the text and image coincide. For example, T1 is the embedded representation of the first text; I1 is the embedded representation of the first image. We want the cosine similarity for I1 and T1 to be as high as possible. We want the same for I2 and T2, and so on for all of the light blue squares. The higher these cosine similarities are, the more "goodness" our model has!
"Badness" of our model
At the same time as wanting to maximize the cosine similarity for each of those blue squares, there are a lot of grey squares that indicate where the text and image don't align. For example, T1 is the text "pepper the aussie pup" but perhaps I2 is an image of a raccoon.

Picture of a raccoon with bounding box annotation. (Source.)
Cute though this raccoon is, we want the cosine similarity between this image (I2) and the text pepper the aussie pup to be pretty small, because this isn't Pepper the Aussie pup!
While we wanted the blue squares to all have high cosine similarities (as that measured "goodness"), we want all of the grey squares to have low cosine similarities, because that measures "badness."
Maximize cosine similarity of the blue squares; minimize cosine similarity of the grey squares. (Source.)
How do the text and image encoders get fit?
The text encoder and image encoder get fit at the same time by simultaneously maximizing the cosine similarity of those blue squares and minimizing the cosine similarity of the grey squares, across all of our text+image pairs.
Note: this can take a very long time depending on the size of your data. The CLIP model trained on 400,000,000 labeled images. The training process took 30 days across 592 V100 GPUs. This would have cost $1,000,000 to train on AWS on-demand instances!
Once the model is fit, you can pass an image into the image encoder to retrieve the text description that best fits the image – or, vice versa, you can pass a text description into the model to retrieve an image, as you'll see in some of the applications below!
CLIP is a bridge between computer vision and natural language processing.
Why is CLIP cool?
With this bridge between computer vision and natural language processing, CLIP has a ton of advantages and cool applications. We'll focus on the applications, but a few advantages to call out:
- Generalizability: Models are usually super brittle, capable of knowing only the very specific thing you trained them to do. CLIP expands knowledge of classification models to a wider array of things by leveraging semantic information in text. Standard classification models completely discard the semantic meaning of the class labels and simply enumerated numeric classes behind the scenes; CLIP works by understanding the meaning of the classes.
- Connecting text / images better than ever before: CLIP may quite literally be the "world's best caption writer" when considering speed and accuracy together.
- Already-labeled data: CLIP is built on images and captions that were already created; other state-of-the-art computer vision algorithms required significant additional human time spent labeling.
Why does @OpenAI's CLIP model matter?https://t.co/X7bnSgZ0or
— Joseph Nelson (@josephofiowa) January 6, 2021
Some of the uses of CLIP so far:
- CLIP has been used to index photos on sites like Unsplash.
- One Twitter user took celebrities including Elvis Presley, Beyoncé, and Billie Eilish, and used CLIP and StyleGAN to generate portraits in the style of "My Little Pony."
- Have you played Pictionary? Now you can play online at paint.wtf, where you'll be judged by CLIP.
- CLIP could be used to easily improve NSFW filters!
- Find photos matching a mood – for example, via a poetry passage.
- OpenAI has also created DALL-E, which creates images from text.
We hope you'll check out some of the above – or create your own! We've got a CLIP tutorial for you to follow. If you do something with it, let us know so we can add it to the above list!
It's important to note that CLIP is a bridge between computer vision and natural language processing. CLIP is not the only bridge between them. You could build those text and image encoders very differently or find other ways of connecting the two. However, CLIP has so far been an exceptionally innovative technique that has promoted significant additional innovation.
We're eager to see what you build with CLIP and to see the advancements that are built on top of it!
Bio: Matthew Brems is Growth Manager @ Roboflow.
Original. Reposted with permission.
Related:
- OpenAI Releases Two Transformer Models that Magically Link Language and Computer Vision
- Evaluating Object Detection Models Using Mean Average Precision
- Reducing the High Cost of Training NLP Models With SRU++