The Three Edge Case Culprits: Bias, Variance, and Unpredictability
Edge cases occur for three basic reasons: Bias – the ML system is too ‘simple’; Variance – the ML system is too ‘inexperienced’; Unpredictability – the ML system operates in an environment full of surprises. How do we recognize these edge cases situations, and what can we do about them?

iMerit is a leader in providing high-quality data for training data sets. In our latest blog post, we bring you the latest in recognising and handling edge cases in your ML systems. If you wish to talk to an expert and learn more about conquering your edge cases, please contact us.
Through training, machine learning (ML) systems learn to recognize patterns by associating inputs (e.g., pixel values, audio samples, text) to categories (e.g., object identities, words, sentiments). This association can be thought of as dividing the multi-dimensional space of possible inputs into regions representing categories, the regions being defined by decision boundaries. When, during testing or operation, an input falls beyond the edge of the region assigned to its category, the input will be mis-categorized. We call this an edge case.
Edge cases occur for three basic reasons:
- Bias – the ML system is too ‘simple’
- Variance – the ML system is too ‘inexperienced’
- Unpredictability – the ML system operates in an environment full of surprises.
How do we recognize these edge cases situations, and what can we do about them?
Bias
Bias shows up when an ML system cannot achieve good performance on its training data set. This is an indication that the architecture of the ML system, its model, does not have a structure that can represent the nuances in the training data. A very simple example is shown below:
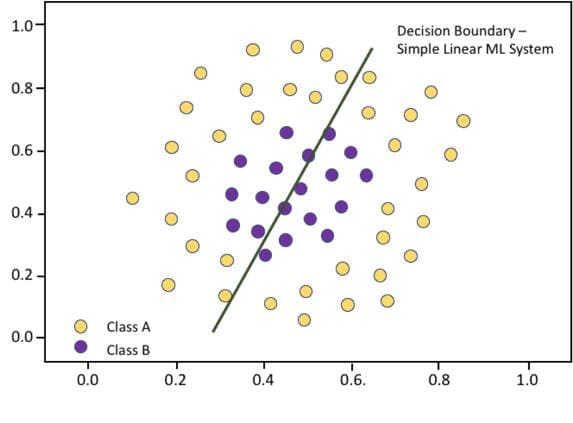
This chart shows the linear decision boundary implemented by a two-input, single-layer, two-neuron neural network. Having been trained to try to distinguish the purple from the yellow dots, it cannot do a good job because its simple linear decision boundary is inadequate to separate the classes.
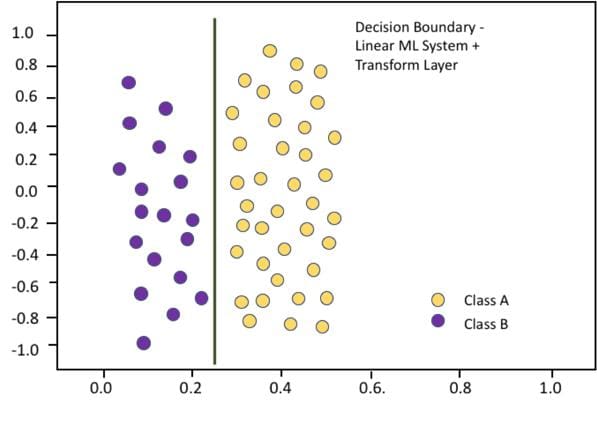
If we make the ML system a bit more complex by adding a pre-processing layer to transform the original inputs to polar coordinates, the purple and yellow dots line up differently in the new input space presented to the linear part of the ML system, and we get a decision boundary that looks like this. This more complex ML system performs well on the training data.
“The structure of the layers themselves can also make a big difference.”
Often the additional complexity needed to overcome bias in an ML system can be accomplished simply by adding processing units and layers. However, the structure of the layers themselves can also make a big difference. The ImageNet visual database has been used since 2010 to benchmark the performance of object recognition ML systems. The best performance on this data set jumped 10.8 percentage points in 2012, when Convolutional Neural Networks replaced earlier architectures that used pre-processing and Support Vector Machines, essentially a more sophisticated version of the simple ML system shown above.
Variance
When an ML system achieves good performance on its training data, but performs poorly in testing, the problem is often that the training data set is too small to adequately reflect the range of variability in the ML system’s operational environment.

The primary way to reduce edge cases caused by variance is to gather more training data.
For example, the object recognition system shown here does fine with adults, but apparently doesn’t have much experience with children.
Edge cases caused by variance issues is a large problem for automatic facial recognition systems. While these systems can be highly accurate in recognizing smartphone users, for example, they can produce inaccurate and troubling results when used for law enforcement. In a 2018 test, 28 members of the US Congress were falsely matched to mug shots in a database of 25,000 criminals.
The primary way to reduce edge cases caused by variance is to gather more training data. Studies have shown that ML system performance consistently improves as training data set size increases, even for data sets that are already very large.
In some cases, data augmentation can be used to increase the size of training data sets, by making small changes to the original data to represent variations such as object rotation, lighting, or pose. However, it is particularly important to ensure that training data is representative of important but possibly rare situations encountered in the operational environment, such as the appearance of children or extreme weather conditions.
Unpredictability
Machine learning relies on finding regular patterns in input data. There is always statistical variation in the data, but with an appropriate architecture and enough training data, an ML system can often find enough data regularity (achieve small enough bias and variance), to make reliable decisions and minimize edge cases.

However autonomous driving is an example of an environment that presents ML systems with such a high degree of variability that the possible situations are virtually endless. Training data can be gathered through many millions of miles of driving without encountering important edge cases. For example, in 2018 a woman was struck and killed by a self-driving car, because the ML system had never been trained to recognize and respond to a jaywalker with a bicycle.
Handling the virtually unlimited number of edge cases encountered in the unpredictable autonomous driving application is a particularly difficult challenge. Two avenues are being pursued to deal with this problem. One approach is to develop ‘checker’ ML systems, specifically trained to recognize dangerous or questionable systems and take overriding action to maintain safety.
Another approach is to train autonomous vehicle ML systems to better handle edge cases. One way is to use virtual road training environments to expand the range of training situations. Another way uses adversarial training, the technology famous for creating ‘deep fakes’, to greatly expand training sets, allowing ML systems to better handle novelty.
Overcoming Edge Cases
The table below summarizes how to recognize and deal with the edge cases resulting from ML bias, variance, and unpredictability:
| Culprit | How it Shows Up | What to Try |
| Bias | Poor training performance | Better ML system model |
| Variance | Poor test performance | More training data |
| Unpredictability | Operational surprises | Simulation Adversarial training |
Key takeaways
- Ensure your training and test data sets are large and diverse enough, (and of course accurately labeled!), to expose weaknesses in ML design and to sufficiently characterize the diversity of the operational environment
- For operational environments with high unpredictability, consider augmenting training data with examples generated through simulation and adversarial training.
- Monitor operations and respond to the inevitable appearance of new edge cases.