Data Careers in Demand: Crowd Solutions Architect Explained
How can crowdsourcing support the applications of data teams at an organization? With an ever-increasing demand for more and higher quality data, a new role of the Crowd Solutions Architect (CSA) can leverage the potential of the masses to bring an advantage to a business's capability to deliver effective AI-driven solutions.
By Daria Baidakova, Director of Educational Programs at Toloka.
Within the career landscape of data-related roles, many professions co-exist, and their precise definitions are often subject to debate, even among those with years of experience behind them. This shouldn’t come as a surprise since the data career landscape is constantly evolving to meet increasing business challenges, and new roles are added virtually every year.
In a recent KDnuggets article, a handful of the most common data-related professions were explained:
- Data architect (concerned with managing and storing data).
- Data engineer (concerned with building and maintaining data pipelines).
- Data analyst (concerned with analysis and representation of data).
- Machine learning engineer (concerned with developing and optimizing machine learning algorithms).
- Data scientist (concerned with what insights data can offer).
In this article, we briefly assess another in-demand role – that of a crowd solutions architect.
Crowdsourcing
Today, more developers than ever before require large volumes of data to feed their AI models at every stage. As a result, labeling data has become a priority. Crowdsourcing, above all else, provides ample opportunity for this purpose. Say, you need to label your data: classify hundreds of thousands of web documents or transcribe a massive set of voice recordings. You basically have two ways of tackling such tasks:
- You can get a small group of specialists in the task-specific field, pay them handsomely, and wait for weeks or months for delivery.
- You attract a large pool of users, filter them by their skills, quickly pre-train them for the task at hand, get each one to contribute a small portion, and as a final step, aggregate what you’ve been able to gather. That way, you get a completed task in a much shorter span of time and at a lower cost.
In a book published by MIT Press, Daren Brabham defines crowdsourcing simply as an “integration of the energies of online communities… a deliberate blend of a bottom-up, open, creative process with top-down organizational goals.” Thus, crowdsourcing is essentially a type of large-scale outsourcing for data generation.
Group intelligence cluster (different data points represent different opinions or task segments) Source: Toloka.ai
Crowd Solutions Architect (CSA)
Now for the promised job. No crowdsourcing is possible without a CSA, whose role is to understand, model, and ultimately facilitate the execution of a crowdsourcing task. Although how comfortable one is in this role may depend on several factors (not least the IT infrastructure one gets to work with), speaking more broadly, this job is suitable for both novices and veterans. Be it an adequately trained newcomer who is eager to get their foot in the door, a medium-level Machine Learning specialist who wants to expand their skill set, or an established expert who wishes to utilize crowdsourcing for their company’s data labeling – all these are feasible scenarios happening all around.
Whatever your background, there are still entry requirements. Arguably, the most crucial is coding skill (Python, SQL, HTML, CSS, and JavaScript) and a decent grasp of ML and statistics. But that’s not all. What sets the CSA job apart from many other IT positions is that it requires two other key skills: understanding business goals and strategies and also knowing how to work not just with code but with human beings. While the former implies that one needs to fully comprehend commercial objectives (not merely technical aspects) of a task, the latter implies that one needs to be a people-oriented person ready to assist contributors when necessary. For this reason, some think of this job as an “engineer of both data and people.”
Applications
Both crowdsourcing and CSAs at work can be observed across multiple areas of research and product development. Among them are natural language processing, computer vision, dataset enrichment, and information retrieval.
All AI development today rests on three distinct paradigms: algorithms, hardware/performance, and data labeling. Whereas the first two have already become “commodities,” with many players using more or less the same tools and techniques, the last item on the list—data labeling—is the least explored of them, even though completions of most AI projects owe a major part of their success to accurate labeling.
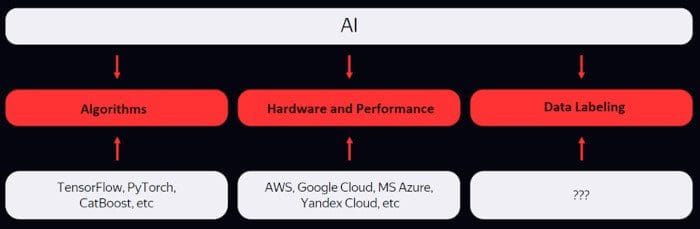
Source: Toloka.ai
Whoever can solve the problem of data labeling most effectively and quickly has the upper hand in business, which comes down to building and maintaining scalable data labeling pipelines. The more human power in a company is dedicated to this crucial aspect, the higher the chances of prompt streamlining of that business and its needs. This implies exploring more datasets for Machine Learning and continuously experimenting with new algorithms (good old trial-and-error).
Become a CSA
If you are interested in becoming a CSA, there are high-quality courses available that can give you a head start in the industry – from Stanford’s Machine Learning course on Coursera to Harvard’s Professional Certificate in Data Science, Cornell’s ML Certificate, and MIT’s Professional Certificate Program in AI.
Those who prefer to learn from crowdsourcing practitioners outside the world of academia can now enroll in a new course titled Practical Crowdsourcing for Efficient Machine Learning. This hands-on online course is suitable for beginners, takes around 23 hours to complete, and offers a shareable certificate upon completion. Among other subjects, the quality and accuracy of data labeling are taught. Successful graduates will have an opportunity to test-drive their algorithms by running full-cycle crowdsourcing projects.
Related: