The Essential Guide to Transformers, the Key to Modern SOTA AI
You likely know Transformers from their recent spate of success stories in natural language processing, computer vision, and other areas of artificial intelligence, but are familiar with all of the X-formers? More importantly, do you know the differences, and why you might use one over another?
Are you overwhelmed by the vast array of X-formers?
No, they aren't another new team of mutants from Marvel in the tradition of the X-Men, X-Factor, and X-Force. X-formers are the name being given to the wide array of Transformer variants that have been implemented or proposed. You likely know Transformers from their recent spate of success stories in natural language processing, computer vision, and other areas of artificial intelligence, but are familiar with all of the X-formers? More importantly, do you know the differences, and why you might use one over another?
A Survey of Transformers, by Tianyang Lin, Yuxin Wang, Xiangyang Liu, and Xipeng Qiu, has been written to help interested readers in this regard.
From the abstract:
[A] great variety of Transformer variants (a.k.a. X-formers) have been proposed, however, a systematic and comprehensive literature review on these Transformer variants is still missing. In this survey, we provide a comprehensive review of various X-formers. We first briefly introduce the vanilla Transformer and then propose a new taxonomy of X-formers. Next, we introduce the various X-formers from three perspectives: architectural modification, pre-training, and applications. Finally, we outline some potential directions for future research.
That's the 30,000 foot view of what this survey papers covers; let's have a closer look.
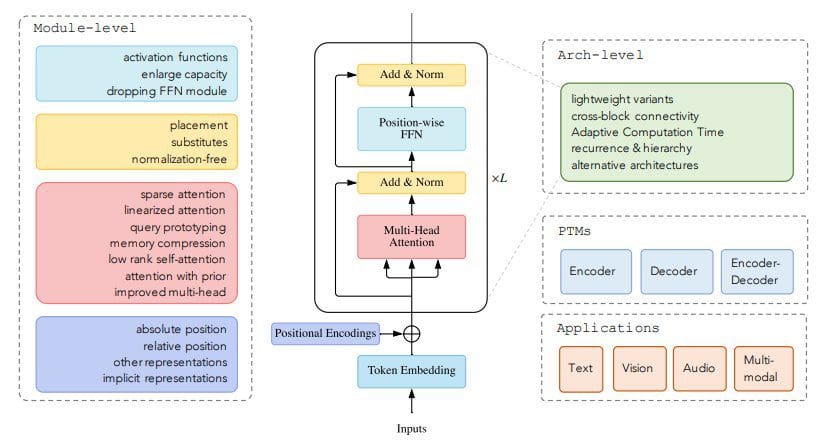
Figure 1. Categorization of Transformer variants (source: A Survey of Transformers)
After introducing the Transformer, the paper establishes the idea of numerous subsequent Transformer variants, the aforementioned X-formers, and notes that these different architectures have all attempted to improve on the original from one of these perspectives: model efficiency, model generalization, and model adaptation. The paper will go on to note these perspectives of change as they relate to the various X-formers subsequently brought up.
Next, the paper goes into deeper technical detail of the vanilla Transformer architecture (see Figure 2), including its usage and performance analysis.
Before getting into specific variants, the authors compare and contrast the Transformer with other architectures. This discussion includes an analysis of both the self-attention mechanism and inductive bias. Herein, Transformers are compared to the architectures of: fully-connected deep neural networks, convolutional networks, and recurrent networks, with regard to per-layer complexity, minimum number of sequential operations and maximum path lengths.
A taxonomy of Transformers is then presented (see Figure 1), noting that a variety of proposed models attempt to improve on the vanilla Transformer from three perspectives: types of architecture modification, pre-training methods, and applications.
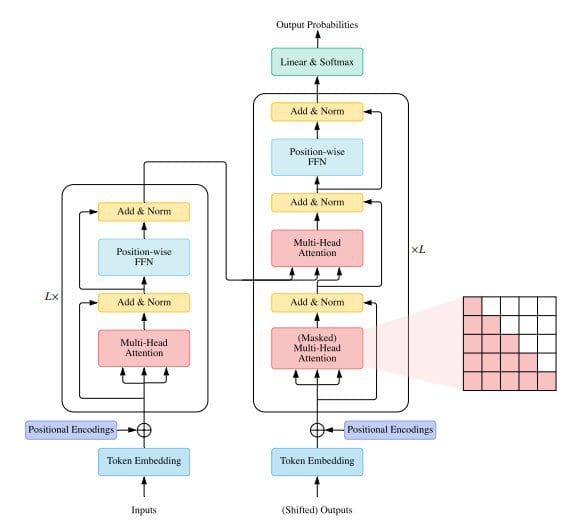
Figure 2. Vanilla Transformer architecture (source:A Survey of Transformers)
The real meat of the survey comes in the following sections, with the first of these focusing on proposed improvements to the attention mechanism, discussing in detail a number of these above-mentioned specific architectures and laying out a taxonomy of these Transformers based on these improvements. Several distinct directions of development have been taken in order to facilitate improvements and these are all discussed, including:
- Sparse Attention
- Linearized Attention
- Query Prototyping and Memory Compression
- Low-rank Self-Attention
- Attention with Prior
- Improved Multi-Head Mechanism
The authors then turn their attention to other X-former module-level modifications, in contrast to architecture level modifications (discussed in a subsequent section). These modifications include position representations, layer normalization, and position-wise feed-forward network layers. Each of these are discussed in detail, connecting how and why each are important to Transfomer architecture, and what various improvements have proposed.
Then comes architecture level X-former variants, discussing modifications beyond the module level, including:
- Adapting Transformer to Be Lightweight
- Strengthening Cross-Block Connectivity
- Adaptive Computation Time
- Transformers with Divide-and-Conquer Strategies
- Exploring Alternative Architecture
The last modification type, Exploring Alternative Architecture, notes that "several studies have explored alternative architectures for Transformer" and discusses where some of this research might be heading.
The next section discusses pre-trained Transformers, while noting a potential problem with Transformers:
Transformer does not make any assumption about how the data is structured. On the one hand, this effectively makes Transformer a very universal architecture that has the potential of capturing dependencies of different ranges. On the other hand, this makes Transformer prone to overfitting when the data is limited. One way to alleviate this issue is to introduce inductive bias into the model.
A brief overview of encoder-only (including the BERT family), decoder-only (including the GPT family), and encoder-decoder (including BART, an extended approach to BERT) architectures as relates to inductive bias is presented.
The paper follows with a summary of the applications of Transformers — which, if you have made it this far, you are probably already aware of — including how it is used in NLP, CV, audio, and multimodal applications. Finally, the authors finish off with conclusions and future directions for X-former related research, noting potential further developments in these directions:
- Theoretical Analysis
- Better Global Interaction Mechanism beyond Attention
- Unified Framework for Multimodal Data
The authors have a done a great job in what they set out to do in this paper. If you are interested in sorting out the specific relationship between the various X-formers out there, I suggest that you, too, give A Survey of Transformers by Tianyang Lin, Yuxin Wang, Xiangyang Liu, and Xipeng Qiu a read.
Related:
- Learn Neural Networks for Natural Language Processing Now
- Great New Resource for Natural Language Processing Research and Applications
- Getting Started with 5 Essential Natural Language Processing Libraries