Feature Selection – All You Ever Wanted To Know
Although your data set may contain a lot of information about many different features, selecting only the "best" of these to be considered by a machine learning model can mean the difference between a model that performs well--with better performance, higher accuracy, and more computational efficiency--and one that falls flat. The process of feature selection guides you toward working with only the data that may be the most meaningful, and to accomplish this, a variety of feature selection types, methodologies, and techniques exist for you to explore.
By Danny Butvinik, Chief Data Scientist at NICE Actimize.

source: TnT Woodcraft.
Feature selection, as a dimensionality reduction technique, aims to choose a small subset of the relevant features from the original features by removing irrelevant, redundant, or noisy features. Feature selection usually can lead to better learning performance, higher learning accuracy, lower computational cost, and better model interpretability. This article focuses on the feature selection process and provides a comprehensive and structured overview of feature selection types, methodologies, and techniques both from the data and algorithm perspectives.
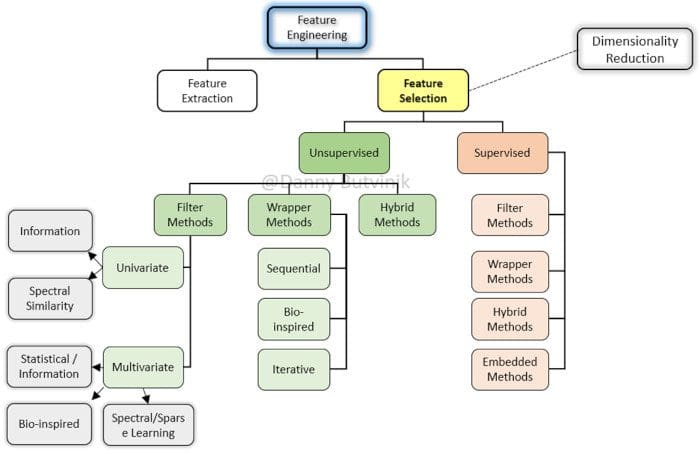
Figure 1: High-level taxonomy for feature selection.
This article considers the feature selection process. The problem is important because a large number of features in a dataset, comparable to or higher than the number of samples, leads to model overfitting, which in turn leads to poor results on the validation datasets. Additionally, constructing models from datasets with many features is more computationally demanding.
A strongly relevant feature is always necessary for an optimal feature subset, and it cannot be removed without affecting the original conditional target distribution.
The aim of feature selection is to maximize relevance and minimize redundancy.
Feature selection methods can be used in data pre-processing to achieve efficient data reduction. This is useful for finding accurate data models. Since an exhaustive search for an optimal feature subset is infeasible in most cases, many search strategies have been proposed in the literature. The usual applications of feature selection are in classification, clustering, and regression tasks.
What Is Feature Selection
All machine learning workflows depend on feature engineering, which comprises feature extraction and feature selection that are fundamental building blocks of modern machine learning pipelines. Despite the fact that feature extraction and feature selection processes share some overlap, often, these terms are erroneously equated. Feature extraction is the process of using domain knowledge to extract new variables from raw data that make machine learning algorithms work. The feature selection process is based on selecting the most consistent, relevant, and non-redundant features.
The objectives of feature selection techniques include:
- simplification of models to make them easier to interpret by researchers/users
- shorter training times
- avoiding the curse of dimensionality
- enhanced generalization by reducing overfitting (formally, reduction of variance)
Dataset size reduction is more important nowadays because of the plethora of developed analysis methods that are at the researcher's disposal, while the size of an average dataset keeps growing both with respect to the number of features and samples.
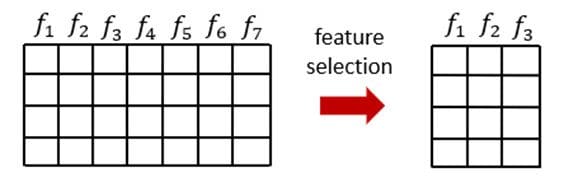
Figure 2: Illustration of feature selection and data size reduction in tabular data.
What Makes Some Feature Representations Better Than Others?
Regardless of the technological approach to feature representation, there is a common question that haunts data scientists in most machine learning workflows: What makes some feature representations better than others?
This might seem like an insane question considering modern machine learning problems are using hundreds of thousands or even millions of features that are impossible to interpret by domain experts.
While there is no trivial answer to our target questions, there are some general principles that we can follow. In general, there are three key desired properties in feature representations:
- disentangling of causal factors
- easy to model
- works well with regularization strategies
Fundamentally, solid representations include features that correspond to the underlying causes of the observed data. More specifically, this thesis links the quality of representations to structures in which different features and directions correspond to different causes in the underlying dataset so that the representation is able to disentangle one cause from another.
Another leading indicator of good representation is the simplicity of modeling. For a given machine learning problem/dataset, we can find many representations that separate the underlying causal factors, but they could be brutally hard to model.
Supervised Feature Selection Methods
Supervised feature selection methods are classified into four types, based on the interaction with the learning model, such as the Filter, Wrapper, Hybrid, and Embedded Methods.
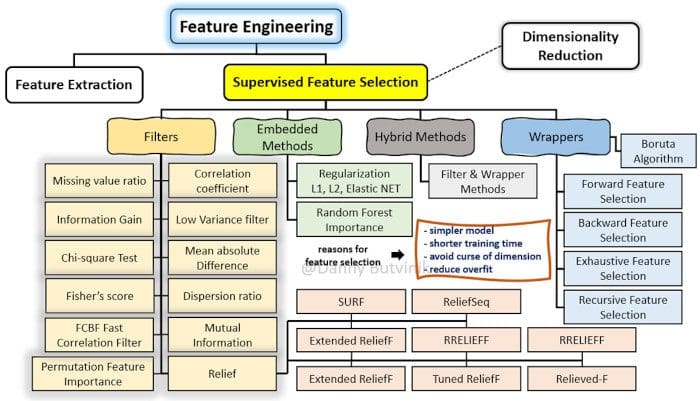
Figure 3: Extended taxonomy of supervised feature selection methods and techniques.
Filter Methodology
In the Filter method, features are selected based on statistical measures. It is independent of the learning algorithm and requires less computational time. Information gain, chi-square test, Fisher score, correlation coefficient, and variance threshold are some of the statistical measures used to understand the importance of the features.
The Filter methodology uses the selected metric to identify irrelevant attributes and also filter out redundant columns from the models. It gives the option of isolating selected measures that enrich a model. The columns are ranked following the calculation of the feature scores.
Wrapper Methodology
The Wrapper methodology considers the selection of feature sets as a search problem, where different combinations are prepared, evaluated, and compared to other combinations. A predictive model is used to evaluate a combination of features and assign model performance scores.
The performance of the Wrapper method depends on the classifier. The best subset of features is selected based on the results of the classifier.
Hybrid Methodology
The process of creating hybrid feature selection methods depends on what you choose to combine. The main priority is to select the methods you’re going to use, then follow their processes. The idea here is to use these ranking methods to generate a feature ranking list in the first step, then use the top k features from this list to perform wrapper methods. With that, we can reduce the feature space of our dataset using these filter-based rangers in order to improve the time complexity of the wrapper methods.
Embedded Methodology
In embedded techniques, the feature selection algorithm is integrated as part of the learning algorithm. The most typical embedded technique is the decision tree algorithm. Decision tree algorithms select a feature in each recursive step of the tree growth process and divide the sample set into smaller subsets.
Unsupervised Feature Selection Methods
Due to the scarcity of readily available labels, unsupervised feature selection (UFS) methods are widely adopted in the analysis of high-dimensional data. However, most of the existing UFS methods primarily focus on the significance of features in maintaining the data structure while ignoring the redundancy among features. Moreover, the determination of the proper number of features is another challenge.
Unsupervised feature selection methods are classified into four types, based on the interaction with the learning model, such as the Filter, Wrapper, and Hybrid methods.
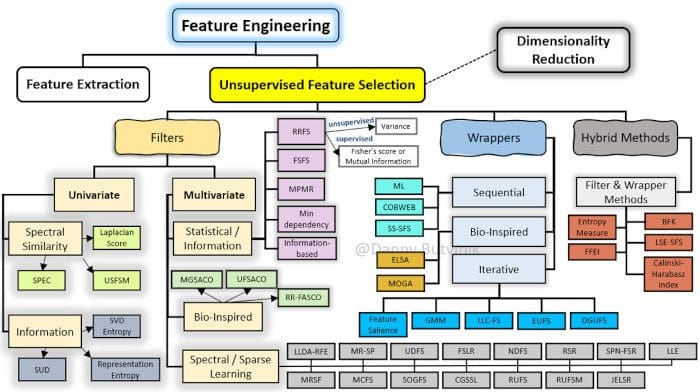
Figure 4: Extended taxonomy of unsupervised feature selection methods and techniques.
Filter Methodology
Unsupervised feature selection methods based on the filter approach can be categorized as univariate and multivariate. Univariate methods, aka ranking-based unsupervised feature selection methods, use certain criteria to evaluate each feature to get an ordered ranking list of features, where the final feature subset is selected according to this order. Such methods can effectively identify and remove irrelevant features, but they are unable to remove redundant ones since they do not take into account possible dependencies among features. On the other hand, multivariate filter methods evaluate the relevance of the features jointly rather than individually. Multivariate methods can handle redundant and irrelevant features. Thus, in many cases, the accuracy reached by learning algorithms using the subset of features selected by multivariate methods is better than the one achieved by using univariate methods.
Wrapper Methodology
Unsupervised feature selection methods based on the wrapper approach can be divided into three broad categories
according to the feature search strategy: sequential, bio-inspired, and iterative. In sequential methodology, features are added or removed sequentially. Methods based on sequential search are easy to implement and fast.
On the other hand, a bio-inspired methodology tries to incorporate randomness into the search process, aiming to escape local optima.
Iterative methods address the unsupervised feature selection problem by casting it as an estimation problem and thus avoiding a combinatorial search.
Wrapper methods evaluate feature subsets using the results of a specific clustering algorithm. Methods developed under this approach are characterized by finding feature subsets that contribute to improving the quality of the results of the clustering algorithm used for the selection. However, the main disadvantage of wrapper methods is that they usually have a high computational cost, and they are limited to be used in conjunction with a particular clustering algorithm.
Hybrid Methodology
Hybrid methods try to exploit the qualities of both approaches, filter and wrapper, trying to have a good compromise between efficiency (computational effort) and effectiveness (quality in the associated objective task when using the selected features).
In order to take advantage of the filter and wrapper approaches, hybrid methods include a filter stage where the features are ranked or selected by applying a measure based on the intrinsic properties of the data. While, in a wrapper stage, certain feature subsets are evaluated for finding the best one through a specific clustering algorithm. We can distinguish two types of hybrid methods: methods based on ranking and methods not based on the ranking of features.
Characteristics of Feature Selection Algorithms
The purpose of a feature selection algorithms is to identify relevant features according to a definition of relevance. However, the notion of relevance in machine learning has not yet been rigorously defined on a common agreement. A primary definition of relevance is the notion of being relevant with respect to an objective.
There are several considerations in the literature to characterize feature selection algorithms. In view of these, it is possible to describe this characterization as a search problem in the hypothesis space as follows:
- Search Organization: general strategy with which the space of hypothesis is explored.
- Generation of Successors: mechanism by which possible variants (successor candidates) of the current hypothesis are proposed.
- Evaluation Measure: function by which successor candidates are evaluated, allowing to compare different hypotheses to guide the search process.
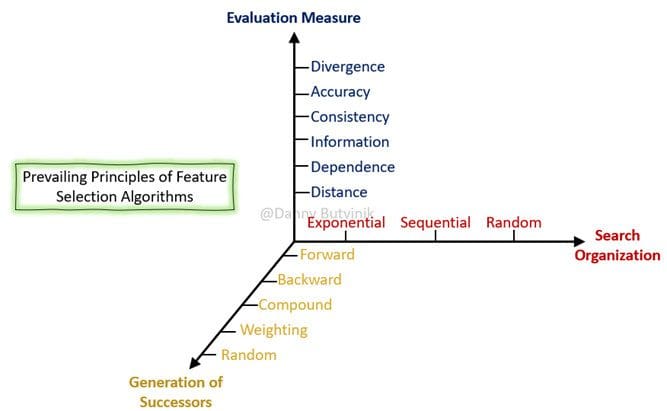
Figure 5: Characterization of a feature selection algorithm.
Feature Representation in Financial Crime Domain
Some of the NICE Actimize research in data science and machine learning is within feature selection and feature representation. In application areas such as fraud detection, these tasks are made more complicated by the diverse, high-dimensional, sparse, and mixed type data.
Without relying on domain knowledge, selecting the right set of features from data of high-dimensionality for inducing an accurate classification model is a tough computational challenge.
Unfortunately, in data mining and financial crime domains, some data are described by a long array of features. It takes seemingly forever to use brute force in exhaustively trying every possible combination of features, and stochastic optimization may be a solution.
Thus, the time and context-specific nature of the financial data requires domain expertise to properly engineer the features while minimizing any potential information loss. In addition, there is no industry standard of metrics in the financial crime domain. That makes the process of developing feature extraction and feature selection extremely difficult, especially when defining an objective function for a machine learning model.
The financial crime feature space vectors cannot be projected into a geometric plan because they won’t hold any underlying logic. The question is, how should one define the distance between two financial transactions (two high-dimensional, mixed type vectors)
I invite you to take that challenge and think about:
- How would you define proper metrics between two sparse, heterogeneous feature vectors (or tensors) having different cardinalities?
- What mechanism would guarantee the verification for valid features, where a valid feature is a feature that has great importance and represents domain logic?
References
- Jovic et al., (2015) A Review of Feature Selection Methods with Applications
- Dadaneh et al., (2016) Unsupervised probabilistic feature selection using ant colony optimization.
- Mohana (2016) A survey on feature selection stability measures
- Chandrashekar (2014) A survey on feature selection methods
- Kamkar, et al., (2015) Exploiting Feature Relationships Towards Stable Feature Selection.
- Guo (2018) Dependence guided unsupervised feature selection.
- Zhou, et al., (2015) A stable feature selection algorithm.
- Yu (2004) Efficient Feature Selection via Analysis of Relevance and Redundancy
- Fernandez et al., (2020) Review of Unsupervised Feature Selection Methods
- Li, et al., (2017) Recent advances in feature selection and its applications
- Zhao and Huan Liu. (2007) Spectral feature selection for supervised and unsupervised learning
Related: