Facebook Launches One of the Toughest Reinforcement Learning Challenges in History
The FAIR team just launched the NetHack Challenge as part of the upcoming NeurIPS 2021 competition. The objective is to test new RL ideas using a one of the toughest game environments in the world.
Image Credit: Facebook Research
I recently started a new newsletter focus on AI education and already has over 50,000 subscribers. TheSequence is a no-BS( meaning no hype, no news etc) AI-focused newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers and concepts. Please give it a try by subscribing below:

Reinforcement learning(RL) has been at the center of some of the most impressive achievements in artificial intelligence(AI) in the last decade. From DeepMind’s famous AlphaGo to milestones in games such as StarCraft II, Dota 2 or Minecraft, RL remains one of the fastest growing areas in the deep learning space. Despite all its success, Facebook AI Research(FAIR) believes that RL needs to be pushed to new levels and, for that, they are turning their attention to a new game: NetHack.
The FAIR team just launched the NetHack Challenge as part of the upcoming NeurIPS 2021 competition. The objective is to test new RL ideas using a one of the toughest game environments in the world.
NetHack and RL
NetHack is a traditional dungeon game that has been under development since the 1980s and its incredibly tough to master for new players. For once, mistakes in NetHack have a disproportional cost. Once a player dies, the game starts from scratch in a completely different dungeon. To complete the game successfully, a player needs to execute about 25–50x more steps than in StarCraft. Additionally, the solution to many problems in NetHack require creativity and consulting external knowledge sources which results incredibly hard to model from a strategic standpoint.

Image Credit: Facebook Research
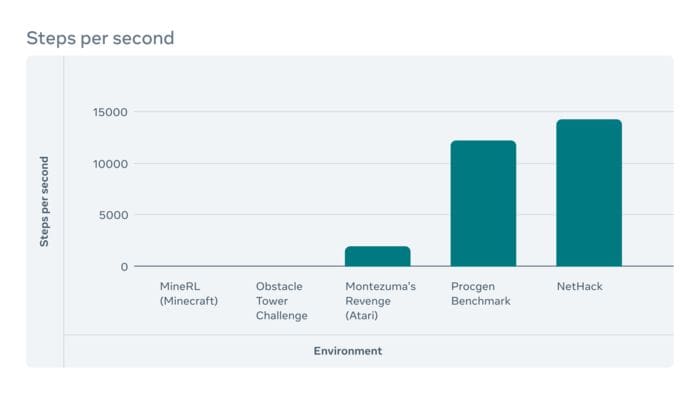
Image Credit: Facebook Research
From the RL perspective, NetHack presents a unique set of challenges:
- Agents cannot reset the environment so optimization methods such as Monte Carlo Tree Search are useless in that type of setting.
- Exploration is even more important given the partial completeness of the environment.
- The high variability of changes in the environment requires rapidly adaptative RL techniques.
Among other things, the NetHack challenge should bring a new set of RL methods that can operate in highly complex environments in which errors have a significant cost. This should help advance research in areas such as navigation or many industrial environments that share some macro-characteristics with NetHack. Can’t wait to see the first wave of submissions.
Original. Reposted with permission.
Related:
- 10 Real-Life Applications of Reinforcement Learning
- Getting Started with Reinforcement Learning
- DeepMind Wants to Reimagine One of the Most Important Algorithms in Machine Learning