15 Things I Look for in Data Science Candidates
This article presents advice for anyone looking or hiring for data science jobs, written by someone with practical and useful insight.
By Mathias Gruber, Chief Data Scientist at LEO Pharma

Office vector created by macrovector — www.freepik.com
Data science is as popular as ever but paradoxically also seems more fragmented and ill-defined than ever before. It can be quite difficult for newcomers to figure out how to break into the field, and perhaps even more difficult, it can be for managers to figure out how to hire for positions unless you know exactly what you’re looking for.
In this post, I summarize my reflections on what I look for in data science candidates. Disclaimer: these are reflections based on my time working in biotech and pharma companies where data science is a supporting function and not a core part of the business; i.e., not the kind of positions where you get to work on AI architectures for sales forecasting exclusively, but where you have to work end-to-end to create value across multiple business areas.
1. Passion & Curiosity
Passion and curiosity are, of course, qualities that are desirable for anyone working with technology. Data science being the great beast that it is, I think it is an even more ubiquitous prerequisite in this specific field. In many other technical fields, you can specialize in a set of skills and use these to drive business value for years on end — perhaps with the need to learn a new programming language or tool every X years. Data science, however, is inherently a scientific discipline that is developing daily.
There is immense value in passionate candidates who continuously research new data science developments and share these with the team.
Furthermore, a certain level of passion and tenacity are required for candidates to keep wanting to work within data science, without jumping jobs in frustration all the time; debugging why an algorithm does not work can be a lot more involved and frustrating than debugging why a piece of software or infrastructure is not working. You need to be a special kind of crazy to go through these frustrations multiple times. ????♂ As I’ve stated previously:
If the option stands between a run-of-the-mill experienced senior data scientist and a violently passionate candidate with fire in their eyes, pick the latter, everything else being equal.

Do not go into data science if you do not have a passion for it; it is not worth it. Comic from xkcd.com
2. Mental Capacity
Data science as an occupation is not for everyone. We should stop pretending that it is.
Alberto Romero
recently wrote an interesting post on this topic, describing the fallacy many people have; if you put in enough hard work, you can become a data scientist. This is not true. It is a tough job:
You need to comprehend math and algorithms, you need to do coding and software development, you need to understand business problems, and you need to have good storytelling and people skills. Not everyone can do all these things and more well.
I’m not saying you need a 130+ IQ to be a data scientist. I’m also not trying to scare anyone away from converting to data science. On the contrary, you can likely do well within data science if you are in another academic-level position right now. But if you’re at the lower end of the IQ bell curve and struggle to understand new concepts and processes, it is really an uphill battle; constantly learning new things and challenging the status quo is the bread and butter of a data science job. Note, I’m not talking about citizen data scientists using low/no-code tools here.

You do not have to be a genius, but a certain level of intelligence is required. Comic from xkcd.com
3. Ability to translate to ML problems
Being good at engineering machine learning (ML) algorithms is one thing. Being good at understanding business problems is another thing. But merging those two and figuring out how to solve business problems with ML is a whole other deal.
You need to be able to translate real world problems into a machine learning problems that you can solve.
Recently Brian Kent wrote a great post describing this facet of data science in a little more detail. Essentially, when you work as a data scientist (at least in the positions I’ve been at), you will rarely get assignments of the type “this is your dataset, fit a regression model for this target.” More often, you will face business problems like the following:
- “We wish to improve our cash flow using some of that new AI stuff,”
- “We want to improve the yield of this chemical by 10% with ML.”
- “We want to improve the efficiency of this or that process/machine.”
Converting these real-world objectives into solvable ML problems is an extremely underrated skill — you need to get a thorough understanding of the business process in question and the data available, you need a solid foundation of what can actually be done with ML, and finally, you need a good intuition for how you can apply different techniques to solve the business objective at hand effectively.
This skill set is in short supply, but it is something that you can practice, e.g., by familiarizing yourself with a multitude of ML applications and by actually spending time thinking about these kinds of problems.

What data? What model? Figuring out what to solve is not easy. Comic from xkcd.com
4. Honesty & Humility
Picture this: the business wants to use AI/ML for optimizing some processes. They are excited, you are excited, and everybody is looking forward to seeing the results. You make a model, and initially, it looks awesome, and everybody has their hands up. You subsequently realize that you made a mistake in the way you evaluated the model, and it is actually horrible — there is no signal in the data at all.
You need to be the person that takes full ownership and admit if you made a mistake, regardless of the consequences
Mistakes will be made. We all make mistakes all the time. But nobody is served by mistakes being swept under the carpet, or much worse, blamed on others. The above situation should be avoided by always having a certain level of humility when presenting results; if they are preliminary results that have not been validated by peers yet, then clearly state this when presenting them. Do not oversell it. In addition, an excellent candidate will always be their own worst critic:
Spend as much time trying to disprove your own conclusions as you spend arriving at them. This will build confidence.

Honesty rocks for data science. Comic by xkcd.com
5. Automation and Optimization
Everybody hates repetitive tasks. Some people hate it so much that they do whatever they can to automate it. We’re talking about all the way from buzzwordy things such as autoML and GitHub copilot, to automating the setup of code environment and generally everything-as-code, to even automating daily time registration, etc. Automation and optimization, for me, are some of the hallmark mindsets of great developers/data scientists.
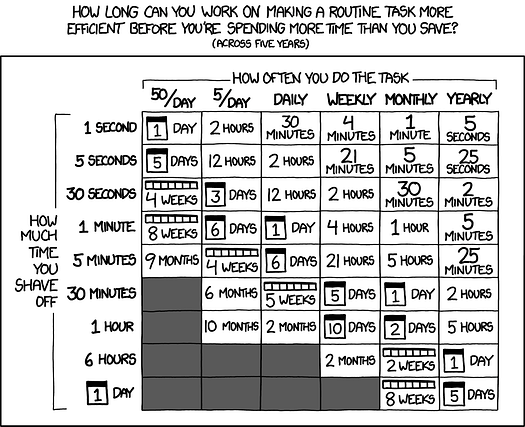
Automate everything. When it makes sense. Comic by xkcd.com
6. Pragmatic & Value Seeking
Data science is a scientific discipline. However, when you get employed as a data scientist, the job is usually about applying data science tools to create business value. Rarely is it about doing research, coming up with new algorithms, breaking new ground, etc. Sometimes it is, but rarely. We are typically employed to create business value.
The goal of our job is to create business value.
When working an industrial data science job, you have to be pragmatic towards this overall goal. I wrote about several pitfalls to avoid in a previous post on the lessons I’ve learned during my time in the industry; you can read more here:
20 Lessons learned going from Junior Data Scientist to Chief Data Scientist
As a summary, I would say that a pragmatic approach involves:
- Always stay customer-centric — if the business is not on board, kill the project, it will never create value.
- Create and select the right ideas — refuse to work on problems/ideas only because someone higher up thinks it is a good idea. If it is technically infeasible, you need to move on.
- Avoid over-engineering — if a simpler approach can solve it in half the time, do that instead.
- Focus on execution — do not get caught up in too many presentations, discussions, what if this, and what if that. Start doing something.
I think there are plenty of reads here on Medium that can help you become more pragmatic as a data scientist. I have recently enjoyed this post by Dennis Eilers, which describes how to be more efficient and impactful in your job, and this post by Archy de Berker on transitioning from academia to industry.

Be pragmatic and create business value. Do not focus on things that do not create value. Comic by xkcd.com
7. Personality & Team Fit
Obviously, the personality of the candidate and how it fits within the rest of the team is important. This is the case for all candidates in all jobs. It is part of why many companies have HR departments and do personality tests before employment. Psychologists often work with the “big five” personality traits, which I find especially insightful for evaluating people you have just met. In terms of these personality traits, I believe some are quite essential, e.g., a certain level of conscientiousness (efficient/organized), disagreeableness (say your opinion and don’t be a sucker), and extroversion (talk with business, hold presentations, etc.), as well as openness (research new tech and kill your darlings). Overall, however, I don’t think there is one “ideal” personality profile for data scientists, so it is mostly a question of avoiding toxic personalities.
Just be chill and nice. Comic by xkcd.com
8. Coding Experience
Coding is an essential part of data science. Typically, the code you write has to be shared with colleagues to get it into production so that you and future colleagues can maintain it for many years to come. Therefore, experience with general software development and good practices is one of the most important qualities for data scientists.
If another developer has to spend 2X the amount of time reviewing and fixing the code you wrote before it can go into production, then you are a detriment to the team and not an asset
Note that I do not care too much about different coding paradigms, nor whether you prefer notebooks or pure scripts, etc. These are standards that individual teams can set. I’m talking about how I’ve seen junior developers write code that was perfectly understandable and could be reviewed in minutes, and I’ve seen senior developers with 30+ years of experience condense 2 weeks of work into 4 lines of incomprehensible R code.
It is a huge plus if you have a public Github account demonstrating that you can write understandable code with good documentation.

Write code that others can understand. Comic from xkcd.com
9. Debugging Skills
We often joke that part of the job is spending all your time on StackOverflow finding code snippets. While you can find plenty of excellent solutions to difficult problems in this manner, the skill of debugging is much more than that.
Do not be the person whose only debugging skill is StackOverflow
On the pure code side of things, you need to read documentation to understand how things actually work, and sometimes you will even have to go through the source code of whatever open source library you are using. On the data science side of things, things can get much hairier; you may need to read through papers to understand how things are supposed to work, and from there, figure out why it is not working — this can truly be a brutal experience, especially since all the numerical details of how people implement algorithms are not always documented in code or the paper.
I would find it much more interesting to see how a candidate would debug a piece of broken code, rather than their ability to solve a given problem by looking at online resources.

Debugging is a skill and an art. Comic from xkcd.com
10. Adaptability
Adaptability is probably already covered by the points about being pragmatic and personality. Even so, adaptability is so essential that I wanted it as a separate point. The field moves fast, and we have to be able to kill our darlings. Spent hundreds of hours on a project, but it turns out not to create business value? Kill it. Spent hundreds of hours with Tensorflow, but now the entire team wants to use PyTorch? Drop it and learn PyTorch. Spent thousands of hours with Python, but now it is not sufficient for what you are doing? Drop it, and learn a new language that is sufficient. Do not dwell on how much time you spent doing something; that will only slow you down.
The day you stop being adaptable is the day you start losing the data science game

Keep an open mind and stay adaptable. Comic from xkcd.com
11. Full Stack Potential
I’ve described previously how I think the typical data science recommendation of specializing within a given subject to avoid becoming a “jack of all trades, master of none” is terrible advice. Rather, one should strive to become “jack of all trades, master of several. “
Do not shun the idea of the “data science unicorn”, rather strive to become one.
That said, I would never be looking for data science unicorns; the talent pool is too scarce, and the definition is too unclear. What I would do, however, is to screen for people complaining about how it is “impossible to be a data science unicorn.” In my book, this statement, which is quite pervasive in the industry, is toxic and indicates an aversion towards getting one's hands dirty and getting things done.
Naturally, you do not have to become a full-fledged frontend/backend developer and cloud/data engineer as well. But I find that the people that are open towards dabbling in other fields are far more effective at delivering results.

Stay open towards expanding your horizons, even though you may not become a master. Comic from xkcd.com
12. Background
Having a background in bioinformatics, quantum physics, or other scientific fields is obviously advantageous when venturing into data science; it means you are used to reading research papers, have done statistical analyses before, maybe a bit of programming, etc. Having a fancy education, however, is by no means a requirement. It is just a few years of structured learning. But naturally, what you have done and achieved previously is considered when applying for new jobs.
I would hire someone who had crawled from nothing to Kaggle competitions grandmaster over any fancy education in a heartbeat, everything else being equal.

Your background naturally influences your current skills. Comic from xkcd.com
13. Storytelling
This point has been made countless times before, so I won’t spend much time on it, even though it is important: data scientists need to tell a good story. What does it mean? Learn to create appealing visualizations, make nice presentations, hold engaging talks, write blog posts, etc.
The more you do it and try to do it better than last time, the better you will be
Learn to tell stories that have an impact. Comic from xkcd.com
14. Collaboration
A weakness of mine is that I’m not that good at collaboration — I think this is a consequence of having been a one-man-army for 10+ years before I got a “real” job. This fact, however, makes me appreciate the people that are good at collaborating even more; creating business value with data science is a team discipline, and so you have to be good at collaborating, with everything that includes; pair programming, proper documentation, sensible git commits, sprint planning, retrospectives, and all that jazz. This kind of experience is definitely an advantage! If you’re new to collaborating, find an interesting open source project and get involved.

You need to be able to work in a team! Data science cannot be done as a one-person army. Comic by xkcd.com
15. Data Science Experience
The last point on my list is actual data science experience. Naturally, it is advantageous if the candidate has been exposed to various disciplines within the field; working with computer vision, natural language processing, forecasting, classic supervised/unsupervised techniques, general deep learning, etc.
In my experience, you rarely get “the same” assignment multiple times. Therefore it is an advantage to have as broad a knowledge base as possible — one day, you may be doing sales forecasting, another you may be predicting chemical properties of molecules or optimizing production processes. If I were hiring for sales forecasting, I wouldn’t worry too much if the candidate had never done sales forecasting before, if the person had a long history of doing other types of machine learning. Learning how to tackle new problems is just another day at the job.
The barrier to gaining broad experience is relatively low; actively participate in a few Kaggle competitions within various fields, then you should start to get a basic overview. Also, by doing this, you will be building a portfolio of what you can do. I’m not saying this is easy to do, just that it is easy to get started. Be sure that you get to the point where you fully understand it whenever you encounter a new concept in this process.
Do not just apply the algorithms as black boxes, but make you understand what they are actually doing.

The longer you’re in the game, the more experience you get; we all keep learning. Comic from xkcd.com
Final Remarks
I ended up writing a fairly lengthy post. If you’ve read through all of it, I thank you ???? I realize that many of the raised points would apply to many professions, especially when it comes to similar jobs such as data engineering, cloud engineering, etc. These are my reflections from a data science perspective. Please note that I would never expect a junior developer to be a perfect fit for all of the mentioned points — rather, I would look for someone who can grow into all the mentioned points. Finally, I would love to get feedback on what other people are looking for in data science candidates, so feel free to drop a comment or reach out through any other channel.
Bio: Mathias Gruber has a broad background in the natural sciences, in particular nanoscience and biophysics. Mathias thrives in challenging environments, and has a passion for obtaining knowledge and developing cutting-edge technology. Current primary interests are all things data science, that is, building solutions to large scale data problems using machine learning algorithms, with particular emphasis on bleeding-edge deep learning methods.
Original. Reposted with permission.
Related:
- How Can You Distinguish Yourself from Hundreds of Other Data Science Candidates?
- The Difference Between Data Scientists and ML Engineers
- Why and how should you learn “Productive Data Science”?