Five Key Facts About Wu Dao 2.0: The Largest Transformer Model Ever Built
The record-setting model combines some clever research and engineering methods.

Image Source: https://www.forbes.com/sites/alexzhavoronkov/2021/07/19/wu-dao-20bigger-stronger-faster-ai-from-china/?sh=4a5264ed6fb2
I recently started a new newsletter focus on AI education and already has over 50,000 subscribers. TheSequence is a no-BS( meaning no hype, no news etc) AI-focused newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers and concepts. Please give it a try by subscribing below:

It seems that every other month we have a new milestone in the race of building massively large transformer models. The trajectory is astonishing. GPT-2 set up new records by building a 1.5 billion parameters model just to be surpassed by Microsoft’s Turing NLG with 17 billion parameters. GPT-3 setup the mark at 175 billion parameters and Google’s Switch Transformer took it to 1.6 trillion parameters. Recently, Beijing Academy of Artificial Intelligence (BAAI) announced the release of Wu Dao 2.0, a transformer model that contains a mind blowing 1.75 trillion parameters. Those numbers are just hard to imagine.
Beyond the monster size of Wu Dao 2.0, the model exhibits several impressive capabilities such as its ability to multitask in language and image domains. To understand Wu Dao 2.0, it might be worth reviewing some key facts about its foundational architecture and design that could shade some light in the intricacies of the model. Here are some of my favorites:
1) FastMoE is the Key
To scale training to trillions of parameters, Wu Dao relied on an architecture known as FastMoE. As it names indicates, the architecture draws inspiration from Google’s Mixture of Experts (MoE) which was used to train the Switch Transformer architecture. MoE is a paradigm proposed in the 1990s that divides a problem domain into multiple experts and a gating mechanism to distribute knowledge. MoE has been used to accelerate the training of large deep neural networks but it typically requires highly specialized hardware. FastMoE is a simple MoE implementation based on PyTorch that can scale using commodity hardware. FastMoE was the key element to scale the training of FastMoE past 1 trillion parameters.
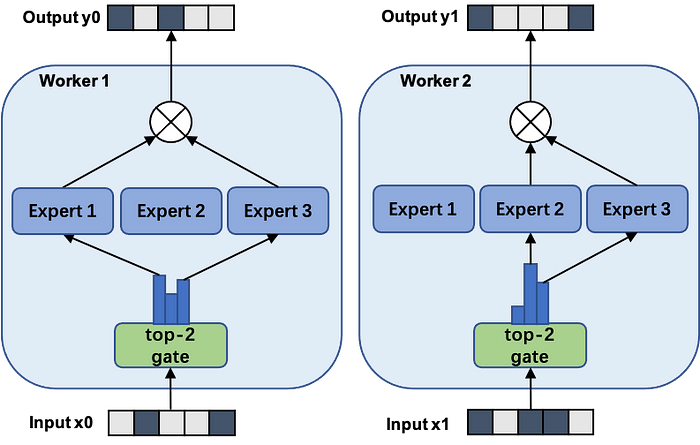
Image Source: https://github.com/laekov/fastmoe
2) The Core Architecture is Based on GLM 2.0
Wu Dao 2.0 is based on the general language model(GLM) 2.0 architecture published in March this year. GLM makes improvements over traditional transformer architectures like BERT or Turing-NLG in areas such as downstream task communication and fine-tuning in order to achieve better results with smaller models.
3) The P-Tuning Algorithm is Cleverly Used to Improve Understanding
Another technical breakthrough used in Wu Dao 2.0 is an algorithm known as P-Tuning 2.0 that breaches the gap between few-shot learning and supervised learning in order to better build language understanding capabilities in transformer models.
4) CogView is Used for Text to Image Generation
Wu Dao 2.0 is able to perform different tasks in both language and image domains. Transformer models such as OpenAI’s DALL-E has achieve remarkable results in test to image generation. Wu Dao 2.0 relies on a similar technique called CogView that can effectively generate rich images from textual descriptions.
5) Evaluated Across Diverse Language and Image Benchmarks
Wu Dao 2.0 was able to achieve state-of-the-art results across 9 industry leaving benchmarks in natural language and computer vision:
- ImageNet zero-shot SOTA exceeds OpenAI CLIP;
- LAMA knowledge detection: more than AutoPrompt;
- LAMABADA Cloze: Ability surpasses Microsoft Turing NLG;
- SuperGLUE few-shot FewGLUE: surpass GPT-3 and obtain the current best few-shot learning results;
- UC Merced Land-Use zero-shot SOTA, exceeding OpenAI CLIP;
- MS COCO text generation diagram: DALL·E beyond OpenAI;
- MS COCO English graphic retrieval: more than OpenAI CLIP and Google ALIGN;
- MS COCO multilingual graphic retrieval: surpasses the current best multilingual and multimodal pre-training model UC2, M3P;
- Multi 30K multilingual graphic retrieval: surpasses the current best multilingual and multimodal pre-training model UC2, M3P.
Wu Dao 2.0 is another impressive achievement in this new era of massively large transformer models. The model combines state of the art research with very clever machine learning engineering methods. Some of the principles of the Wu Dao architecture will serve as inspiration to keep pushing the boundaries of transformer models.
Bio: Jesus Rodriguez is currently a CTO at Intotheblock. He is a technology expert, executive investor and startup advisor. Jesus founded Tellago, an award winning software development firm focused helping companies become great software organizations by leveraging new enterprise software trends.
Original. Reposted with permission.
Related:
- DeepMind Wants to Reimagine One of the Most Important Algorithms in Machine Learning
- Behind OpenAI Codex: 5 Fascinating Challenges About Building Codex You Didn’t Know About
- DeepMind’s New Super Model: Perceiver IO is a Transformer that can Handle Any Dataset