DeepMind’s New Super Model: Perceiver IO is a Transformer that can Handle Any Dataset
The new transformer-based architecture can process audio, video and images using a single model.

Source: https://www.zdnet.com/article/googles-supermodel-deepmind-perceiver-is-a-step-on-the-road-to-an-ai-machine-that-could-process-everything/
I recently started a new newsletter focus on AI education and already has over 50,000 subscribers. TheSequence is a no-BS( meaning no hype, no news etc) AI-focused newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers and concepts. Please give it a try by subscribing below:

Most deep learning models we build these days are highly optimized for a specific type of dataset. Architectures that are good at processing textual data cant be applied to computer vision or audio analysis. That level of specialization naturally influences the creation of models highly specialized in a given task and that are not able to adapt to other tasks. This constraint highly contrasts with human cognition in which many tasks require diverse inputs such as vision and audio. Recently, DeepMind published two papers unveiling general-purpose architectures that can process different types of input datasets.
The first paper titled “Perceiver: General Perception with Iterative Attention” introduces Perceiver, a transformer architecture that can process data including images, point clouds, audio, video, and their combinations but its limited to simple tasks such as classification. In “Perceiver IO: A General Architecture for Structured Inputs & Outputs”, DeepMind presents Perceiver IO, a more general version of the Perceiver model that can be applied to complex multi-modal tasks such as computer games.
Both Perceiver models are based on transformer architectures. Despite all its success with models like Google BERT or OpenAI GPT-3, most transformer models have been mostly effective in scenarios with inputs of maximum a few thousand elements. Data types such as images, videos or books can contain millios of elements which makes the use of transformers a bit challenging. To address this, Perceiver relies on a general attention layer that does not make any domain-specific assumptions about the input. Specifically, the Perceiver attention model first encodes the input into smaller latent arrays which processing cost is independent of the size of the input. This allow the Perceiver model to scale gracefully with the inputs.
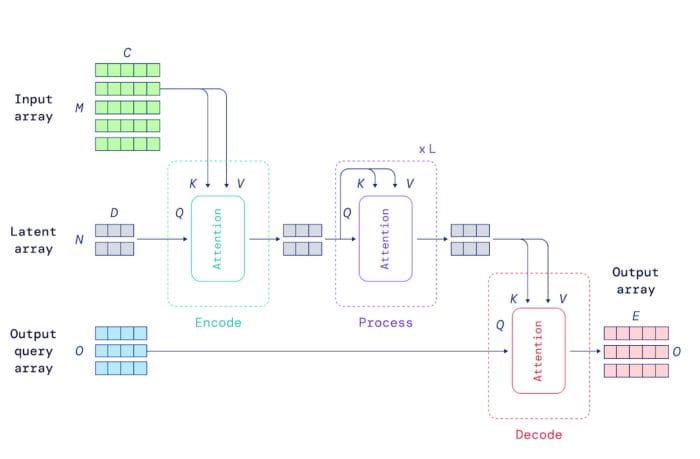
Image Credit: DeepMind
Beyond the scalability benefits, the previous architecture allows the Perceiver model to achieve robust levels of generalization using different datasets. See the examples below that reconstruct video and audio inputs.
Here is the original video.
Video Credit: DeepMind
Here is what Perceiver produced.
Video Credit: DeepMind
Super impressive! Perceiver is one of the first large scale architectures able to process different input types. We are likely to see DeepMind double down in this concept in future research.
Transformer architectures have been front and center of most relevant milestones in the last few years of deep learning. Mostly applied to natural language scenarios with models like Google BERT or OpenAI GPT-3, transformers have been steadily making progress in other domains such as computer vision.
Bio: Jesus Rodriguez is currently a CTO at Intotheblock. He is a technology expert, executive investor and startup advisor. Jesus founded Tellago, an award winning software development firm focused helping companies become great software organizations by leveraging new enterprise software trends.
Original. Reposted with permission.
Related:
- DeepMind Wants to Reimagine One of the Most Important Algorithms in Machine Learning
- Facebook Open Sources a Chatbot That Can Discuss Any Topic
- How DeepMind Trains Agents to Play Any Game Without Intervention