Cloud-Native Super Computing
NVIDIA BlueField DPUs provide on-demand, simple and secure high-performance computing and AI services.
By David Slama, Senior Director of Marketing for Networking at NVIDIA and Scot Schultz, Sr. Director HPC & Technical Computing at NVIDIA
High-performance computing (HPC) and AI have driven supercomputers into wide commercial use. They’ve become the primary data processing engines to enable research, scientific discoveries and product development.
As a result, supercomputers now need to service many users of different types and a broad range of software. They have to deliver non-stop services dynamically while delivering bare-metal performance in a secure, multi-tenancy environment.
Cloud-native supercomputing blends the power of HPC with more offloading and acceleration capabilities and with the security and ease of use of cloud computing services. It’s a simple, secure infrastructure for on-demand HPC and AI services.
NVIDIA’s cloud-native supercomputing architecture with NVIDIA BlueField data processing units (DPU) offers several advantages:
- High-speed, low-latency NVIDIA Quantum InfiniBand networking to deliver bare-metal performance
- Additional application and middleware offload and acceleration capabilities
- Secured infrastructure for data protection and tenant isolation
- Data storage for tenant workloads
- NVIDIA DOCA software framework for software-defined Infrastructure and tenant services
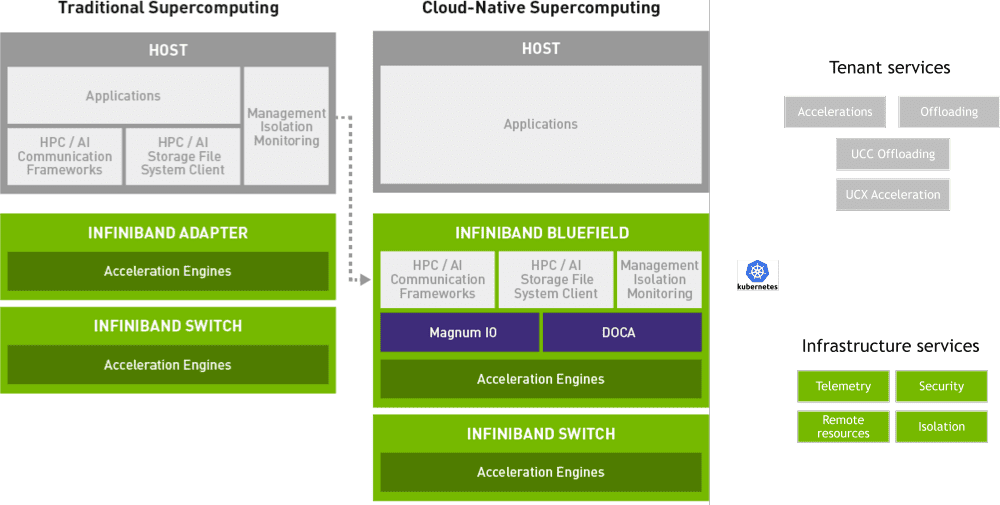
The figure above shows traditional supercomputing architecture versus a cloud-native supercomputing architecture that offers a flexible, secured infrastructure for multi-tenancy with offloading/acceleration capabilities. Additionally, cloud service providers can run and deploy multiple services (Kubernetes PODs) on the BlueField DPU or for infrastructure security, telemetry or resource allocation.
Why cloud-native supercomputing offers a better approach
With BlueField DPU resources, customers can offload communication frameworks, such as UCX or UCC offload services, to the DPU instead of using the host-based CPU resources. This frees the CPU to devote its processing power to the application, instead of spending cycles on communication services.
Cloud-native supercomputing also improves application performance. It offers additional capabilities such as active messages, smart MPI progression, data compression or even user-defined algorithms based on the DOCA SDK.
Zero-trust architecture for bare-metal performance
For security and isolation, cloud-native supercomputing provides a zero-trust architecture. Along with storage virtualization for any remote storage, a particular volume, for example, can be assigned to a tenant.
The architecture also provides for service-level agreement for each tenant and can be defined and configured against the assigned partition keys. For example, for NVIDIA Scalable Hierarchical Aggregation and Reduction Protocol (SHARP) resources, or bandwidth guarantees, rate limiting or other defined tenant-based service levels.
What’s more, it can provide 32,000 concurrent isolated users on a single subnet. The cloud orchestrator has access to both DPU and host telemetry information to monitor the system along with host introspection to ensure that previous tenants leave no accessible footprint to a new tenant across resources. The result: each new tenant accessing the system will have a completely wiped, secure and isolated workspace.
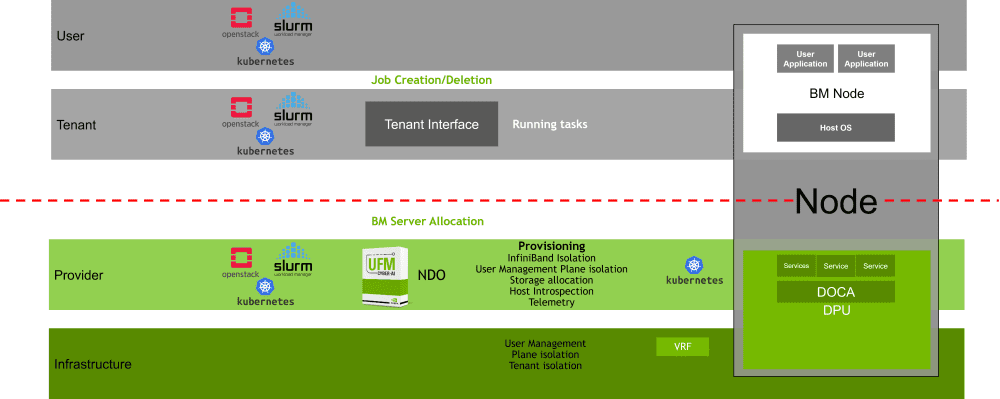
Example of a cloud-native supercomputing architecture
Hear more at NVIDIA GTC
To learn more about how to deploy a cloud-native supercomputing architecture in your network, register for free for NVIDIA GTC, running March 21-24.
The sessions below will explore a step-by-step deployment guide to get up and running and provide valuable insight into what’s next for cloud-native supercomputing.
GTC Spring 2022 Session S42371: Build and Deploy a Cutting-Edge Cloud-Native Supercomputer