Metadata Store for Production ML!
Add Layer to your existing ML code and quickly get a rich model and data registry with experiment tracking!
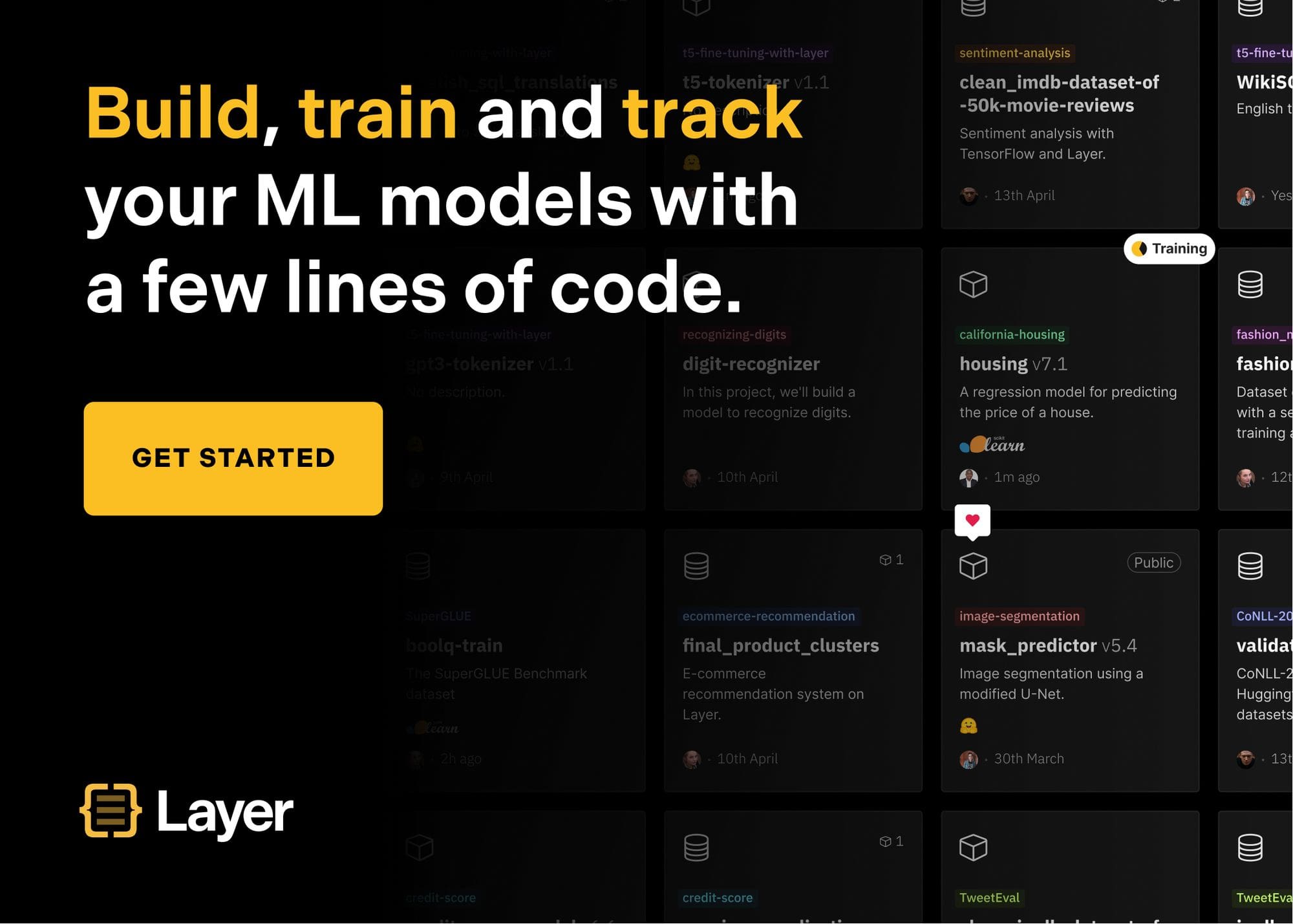
One of the biggest problems in machine learning is the ability to collaborate on ML projects. The lack of a single collaboration platform, scattered datasets, and models exacerbate this problem further.
Layer helps you build, train and track all your machine learning project metadata including ML models and datasets with semantic versioning, extensive artifact logging, and dynamic reporting with local↔cloud training
Enable metadata store for your ML project now!
Add Layer to your existing ML code and quickly get a rich model and data registry with experiment tracking!
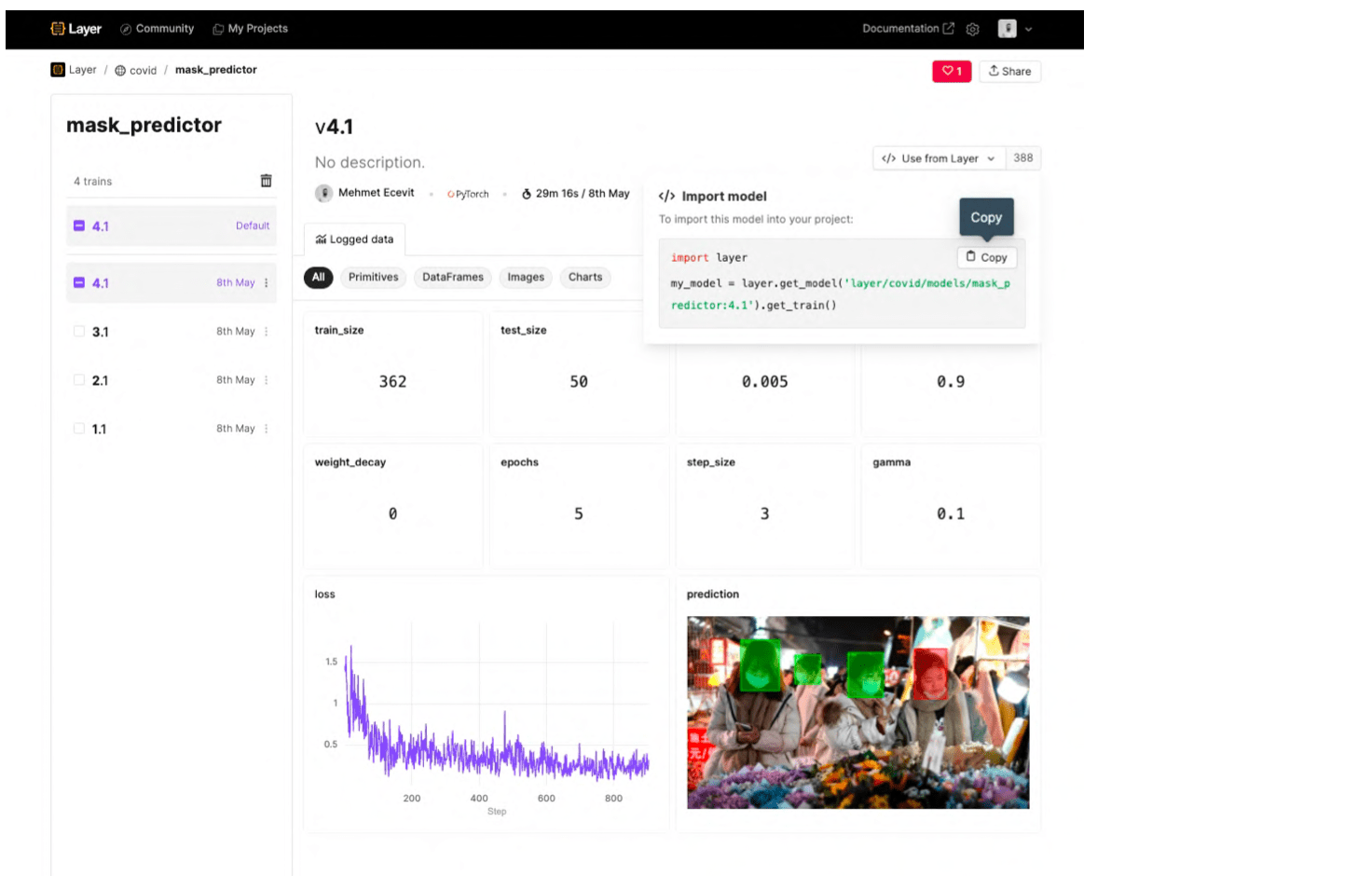
@model()
Wrapping your model training function with the model decorator will store and version the resulting model to Layer. This helps you manage the lifecycle of your model with semantic versioning. The model can then be fetched and used for making predictions immediately.
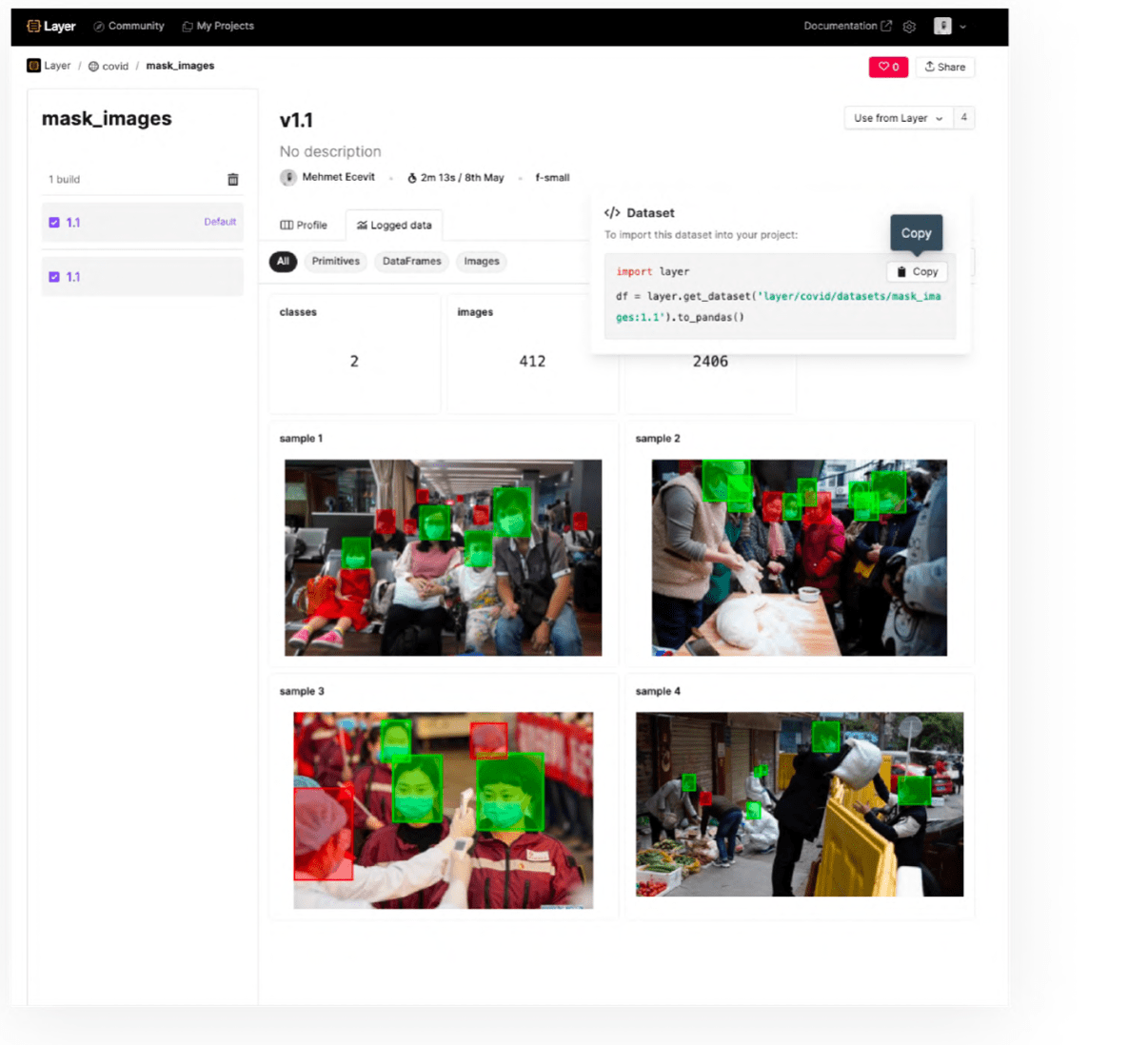
@dataset()
Adding the dataset decorator to your data creation functions will save the resulting data to Layer. Layer will semantically version the data making your pipelines reproducible. Layer supports tabular and image datasets.
@assert()
Testing in machine learning ensures that you have error-free pipelines. To help you to achieve this, Layer has created a list of assertions. To add a behavioral test to your ML model or a unit test to your dataset, you just add the appropriate assertion decorator in your code.
layer.log()
Log metrics, tables, images, markdown/html content, Streamlit/Gradio apps, everything for your machine learning experiment. Then compare your results with your previous versions of your experiments.
layer.run()
Layer is an advanced ML metadata store and pipeline runner. You can use Layer infrastructure to seamlessly build your datasets, train your models, and store your resulting model and dataset artifacts. This is especially useful when:
- Your training data is too big to fit in your local machine.
- Your model requires special infra like a high-end GPU that is too expensive to provision permanently.
Community!
We have numerous models, datasets, and projects on our community page to help you get started with Layer.
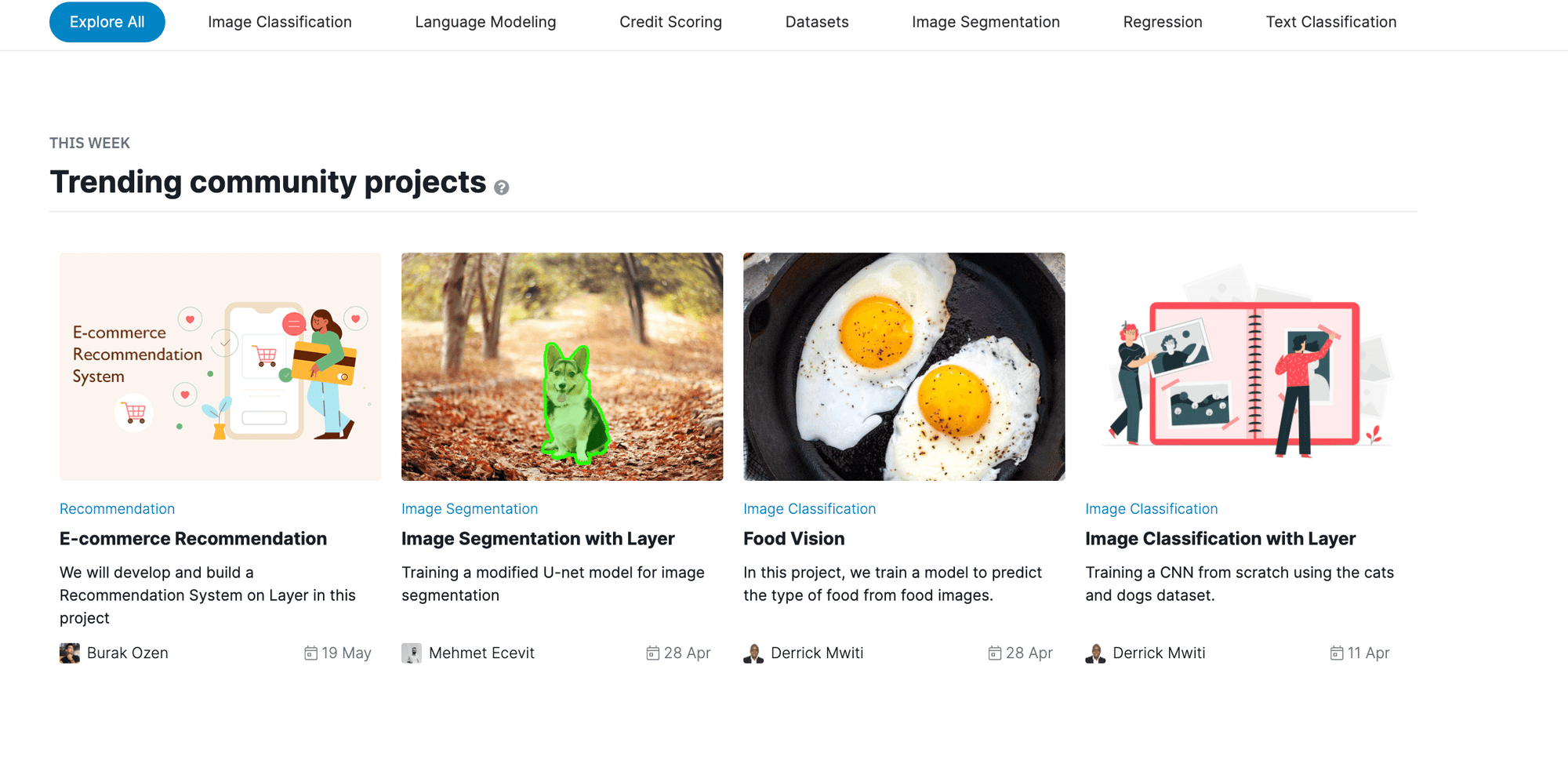
Here are some resources to quickly get you started:
Visit layer.ai to start building now! Don’t forget to join our Slack community, and follow us on Twitter and Linkedin for resources, events, and much more.