In Part 1, we saw that simple random sampling (SRS) is not always simple in practice.
The Story So Far
Imagine that you’re a data scientist who has been hired to estimate the average height of pine trees in the forest pictured below and describe the distribution. You’re responsible for the planning and analysis, so you get to pull the strings from the comfort of your lair while an avid hiker carries out your instructions to measure trees in the forest.
What you’re most definitely NOT going to do is instruct the hiker to “just select 20 trees entirely at random.” (If you’re tempted, please head back to Part 1.)

How tall are the trees in this forest? Photo by Dan Otis on Unsplash
Instead, always strive to give foolproof instructions, because you never know when a wild fool will appear.
Always strive to give foolproof instructions, because you never know when a wild fool will appear.
Foolproof Instructions
When I challenge my students to give me better — more foolproof — instructions for the data collection agent (the hiker), the group usually arrives at ye olde classic suggestion:
“Identify each tree with a unique number and then sample those IDs randomly.”
That’s better — at least it no longer includes the word “just” — but it’s still not the professional-statistician-level answer. Professional statisticians have had their hearts broken enough times to know that the devil is in the details.

Photo by Sebastian Herrmann on Unsplash
The Devil is in the (Real World) Details
In a professional statistician’s mind, that innocent-looking instruction rapidly snowballs into an entire avalanche of details:
“Dear hiker, let me apologize in advance, but you’ll have to walk through this entire forest one time, numbering all the trees with unique IDs… which is why it’s such a relief that you adore hiking!”
Before we’ve even finished speaking, our minds are racing:
With what paint? (Write it down!)
Wait, how many buckets of paint might we need? (Write it down!)
What do we do if run out of paint (because we don’t know how many trees are in the forest). (Write it down!)
Where can we buy more buckets of paint? Where’s the nearest town? (Write it down!)
Where would it be efficient store the buckets while we’re working? (Write it down!)
How do we make sure that we sensibly label these trees so that we can efficiently find them again if their number is drawn? (Write it down!)
Do we need a cart? Or some assistants? (Write it down!)
How do we make sure we haven’t missed a tree? (Write it down!)
How long do we expect this all to take? (Write it down!)
What if the hiker quits midway through the project? (Write it down!)
What if it rains and the paint comes off? (Write it down!)
How much is this all going to cost? (Write it down!)
What’s our plan for pivoting if the plan turns out to be more expensive than expected? (Write it down!)
What’s our budget? (Write it down!)
Alternative Sampling Schemes
Ah, budget. As you start detailing your plan, you may discover that your ideal approach is infeasible. In that case, you have two options.
- Select a different sampling procedure. SRS is not the only approach available to you and it’s not even necessarily the statistically superior one for your needs. Its main advantage is that it allows you to use beginner techniques, but if you find that pulling off SRS in the real world is more expensive than hiring someone who knows the advanced methods, then this is a great option. Just remember that using other sampling procedures means you must analyze the data differently from the standard way STAT101 teaches you to do it (unless you pick option 2 below).
- Assume away the problems. This is the classic corner-cutting act of desperation and you’ll find it everywhere in science. It essentially boils down to saying that you’ll perform your analysis AS IF certain things are true even though you know they’re not. This is philosophically-shaky territory and the only person who has the right to bless going ahead with it is the decision-maker, who might be willing to accept a lower-quality decision procedure to conserve resources. If you’re not the one who’s in charge of making the data-driven decision, it’s not your place to make this call.
But let’s imagine your hiker is so keen to hang out in the forest for as long as possible (whoa) that they offer you a flat rate on the project. Now you can afford to have this outdoorsy fanatic paint all the trees for you. Time to start planning for the next step: selecting 20 trees at random.
How do we “just” select 20 of them? One dead-simple way to do it is to wait until all the trees are painted with unique IDs, then put all the tree IDs into one column of a spreadsheet, drag the =RAND() function through the adjacent column, and sort in order of the random number column, then select the first 20 IDs at the top of the shuffled sheet.
Now we’re worrying ourselves over more details:
Should the labels be integers or something else? (Write it down!)
What if they’re hard to read? (Write it down!)
Are we sure the random number generator is random? (Write it down!)
What if we forget to paste-special-as-values-only? (Write it down!)
Are we planning to bring a laptop to the forest? Which one? (Write it down!)
Will the software work if there’s no Wi-Fi? (Write it down!)
Will the laptop battery last long enough? (Write it down!)
Do we need backup laptops? (Write it down!)
Once we have the 20 randomly selected tree IDs — saved where? (Write it down!) — it’s time to apologize to the hiker for potentially having to hike the forest a second time. Hopefully, we’ve come up with an efficient hiking strategy to save time since the poor hiker is exhausted already. But then there’s more!
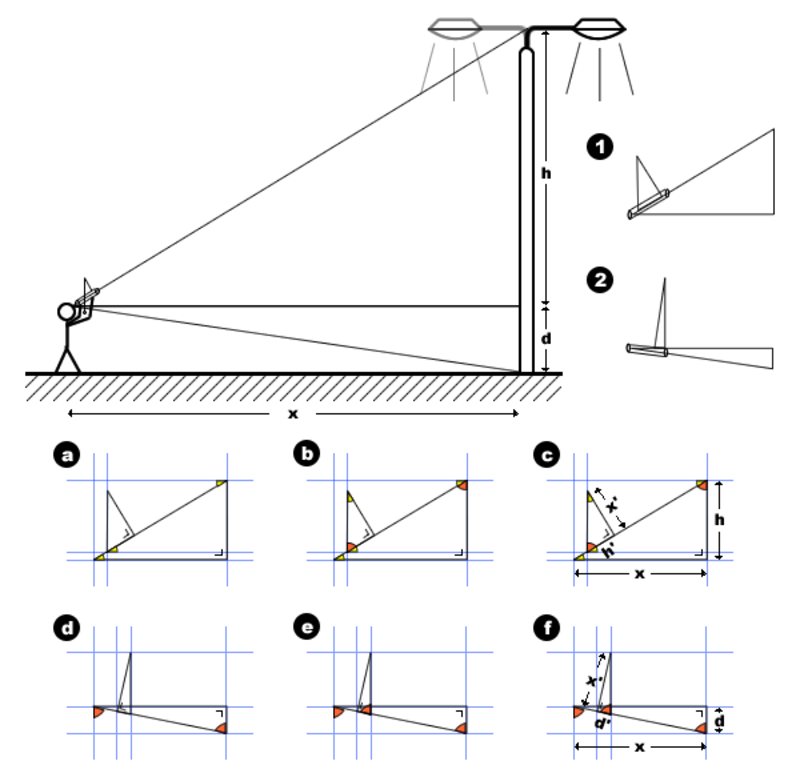
Illustration from the Wikipedia page on elevation measurement using a hypsometer: https://en.wikipedia.org/wiki/Hypsometer
How will the hiker perform the measurements? (Write it down!)
Which instrument shall we use? A hypsometer? (Write it down!)
How do we ensure the hiker is properly trained to use the equipment correctly? (Write it down!)
What should we do if the tree is on a slope or obscured? (Write it down!)
What extra equipment might we need? (Write it down!)
Where will the measurements be recorded? Paper? Laptop? Phone? Did we plan for how this will be carried and what to do if it malfunctions? (Write it down!)
Does the hiker understand that the measurement should be recorded next to the tree ID?
Is tree height the only thing the hiker should measure and record about each tree? Surely there’s some additional information that could be useful and relatively inexpensive to acquire, including time of day, physical characteristics of the tree, distance from hiker’s starting point, number of other trees within a radius relevant for sunlight and soil nutrient competition (what radius is that?), circumference of the tree, and plenty more. (Write it down! But speak to a domain expert first if you, like me, know very little about trees.)
If we’re recording a bunch of additional attributes for each ID, how should they be recorded? What’s the data schema the hiker should use? (Write it down!)
How will we check for mistakes? Should the hiker perform extra checks? (Write it down!)
How do we verify that the hiker followed the instructions correctly? (Write it down!)
For each attribute we’re recording, which units or categories should the hiker use? (Write it down!)
Before we call it a day, we’ll go through our document and flesh out even more details. If you do a shoddy job of writing detailed instructions, you’re going to end up hating your data collection agent for the mess they’ll come back with (since it won’t be what you thought you asked for). And your data collection agent will rightly hate you for giving them stupid instructions and expecting them to read your mind.
Someday, the data collection agent will *be* you… and then you will hate you.
A sampling plan covers the real-world practical aspects of data collection.
That’s how we learn the hard way on the job. The grown-up data hygiene habits I’ve built over the years are fueled by rage at my former self’s bad planning. Younger me cared mostly about the math. Time-marinated me is far more interested in the real-world details. My hope is that you’re able to learn from my mistakes so you needn’t repeat them.
Please, promise me that you’ll never again instruct someone to “just” take a simple random sample.

Photo by Brett Jordan on Unsplash
Sampling Plan
After you’ve worried plenty over the details (write it down!), the document you have in front of you is called a sampling plan.
A sampling plan covers the real-world practical aspects of data collection and it’s amateurish in the extreme to approach recording data from the real world without one. If you try to skip planning, you’ll end up with a very expensive dress rehearsal for your impending do-over.
Sampling Scheme
Now that you’ve written down both the theoretical part (the sampling procedure) and the practical part (the sampling plan), you’re ready to combine them into a single document called a sampling scheme.
Sampling Plan + Sampling Procedure = Sampling Scheme
By the way, when you buy data from a vendor, you should always ask for the full sampling scheme (the plan too, not just the procedure) to make sure you understand what your data actually means. For more tips on working with secondary (inherited) data, including purchased data, see my guide here.
A true professional wouldn’t dream of collecting data before they’ve created a full sampling scheme. Unfortunately, with the way data college courses are taught — so much theory, so little practice — it often takes a while before the freshly graduated ducklings start to resemble true professionals. Those of us who’ve been in the game for a while can do our part by cheerleading for paying attention the practical aspects. After all, if the details are soggy, what’s the point of all the fancy math?
Thanks for Reading! How About an AI Course?
If you had fun here and you’re looking for an applied AI course designed to be fun for beginners and experts alike, here’s one I made for your amusement:
Enjoy the entire course playlist here: bit.ly/machinefriend
Cassie Kozyrkov is a data scientist and leader at Google with a mission to democratize Decision Intelligence and safe, reliable AI.
Original. Reposted with permission.