Getting Started with spaCy for NLP
In this blog, we will explore how to get started with spaCy right from the installation to explore the various functionalities it provides.

Image by Editor
Nowadays, NLP is one of the most emerging trends of AI as its applications are widespread across several industries such as Healthcare, Retail, and Banking to name a few. As there is an increasing need to develop fast and scalable solutions, spaCy is one of the go-to NLP libraries for developers. NLP products are developed to make sense of the existing text data. It mainly revolves around solving questions such as ‘What is the context of data?’, ‘Does it represent any bias?’, ‘Is there some similarity among words?’ etc. to build valuable solutions?
Therefore, spaCy is a library that helps to deal with such questions and it provides a bunch of modules that are easy to plug and play. It is an open-source and production-friendly library that makes development and deployment smooth and efficient. Moreover, spaCy was not built with a research-oriented approach hence it provides a limited set of functionalities for the users to choose from instead of multiple options to develop quickly.
In this blog, we will explore how to get started with spaCy right from the installation to explore the various functionalities it provides.
Installation
To install spaCy enter the following command:
pip install spacy
spaCy generally requires trained pipelines to be loaded in order to access most of its functionalities. These pipelines contained pretrained models which perform prediction for some of the commonly used tasks. The pipelines are available in multiple languages and in multiple sizes. Here, we will install the small and medium size pipelines for English.
python -m spacy download en_core_web_sm python -m spacy download en_core_web_md
Voila! You are now all set to start using spaCy.
Loading the Pipeline
Here, we will load the smaller pipeline version of English.
import spacy
nlp = spacy.load("en_core_web_sm")
The pipeline is now loaded into the nlp object.
Next, we will be exploring the various functionalities of spaCy using an example.
Tokenization
Tokenization is a process of splitting the text into smaller units called tokens. For example, in a sentence tokens would be words whereas in a paragraph tokens could be sentences. This step helps to understand the content by making it easy to read and process.
We first define a string.
text = "KDNuggets is a wonderful website to learn machine learning with python"
Now we call the ‘nlp’ object on ‘text’ and store it in a ‘doc’ object. The object ‘doc’ would be containing all the information about the text - the words, the whitespaces etc.
doc = nlp(text)
‘doc’ can be used as an iterator to parse through the text. It contains a ‘.text’ method which can give the text of every token like:
for token in doc: print(token.text)
output:
KDNuggets is a wonderful website to learn machine learning with python
In addition to splitting the words by white spaces, the tokenization algorithm also performs double-checks on the split text.
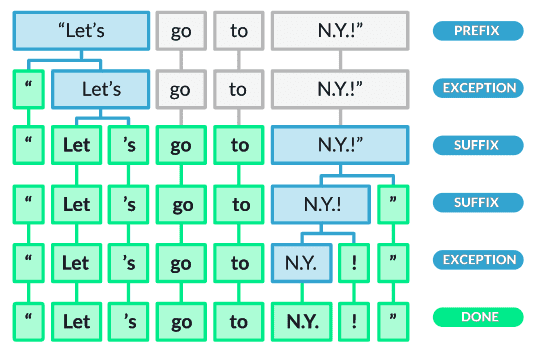
Source: spaCy documentation
As shown in the above image, after splitting the words by white spaces, the algorithm checks for exceptions. The word ‘Let’s’ is not in its root form hence it is again split into ‘Let’ and ‘’s’. The punctuation marks are also split. Moreover, the rule makes sure not to split words like ‘N.Y.’ and considers them like a single token.
Stop Words
One of the important preprocessing steps in NLP is to remove stop words from text. Stop words are basically connector words such as ‘to’, ‘with’, ‘is’, etc. which provide minimal context. spaCy allows easy identification of stop words with an attribute of the ‘doc’ object called ‘is_stop’.
We iterate over all the tokens and apply the ‘is_stop’ method.
for token in doc: if token.is_stop == True: print(token)
output:
is a to with
Lemmatization
Lemmatization is another important preprocessing step for NLP pipelines. It helps to remove different versions of a single word to reduce redundancy of same-meaning words as it converts the words to their root lemmas. For example, it will convert ‘is’ -> ‘be’, ‘eating’ -> ‘eat’, and ‘N.Y.’ -> ‘n.y.’. With spaCy, the words can be easily converted to their lemmas using a ‘.lemma_’ attribute of the ‘doc’ object.
We iterate over all the tokens and apply the ‘.lemma_’ method.
for token in doc: print(token.lemma_)
output:
kdnugget be a wonderful website to learn machine learning with python
Part-of-Speech (POS) Tagging
Automated POS tagging enables us to get an idea of the sentence structure by knowing what category of words dominate the content and vice versa. This information forms an essential part in understanding the context. spaCy allows parsing the content and tagging the individual tokens with their respective parts of speech through the ‘.pos_’ attribute of the ‘doc’ object.
We iterate over all the tokens and apply the ‘.pos_’ method.
for token in doc: print(token.text,':',token.pos_)
output:
KDNuggets : NOUN is : AUX a : DET wonderful : ADJ website : NOUN to : PART learn : VERB machine : NOUN learning : NOUN with : ADP python : NOUN
Dependency Parsing
Every sentence has an inherent structure in which the words have an interdependent relationship with each other. Dependency parsing can be thought of as a directed graph wherein the nodes are words and the edges are relationships between the words. It extracts the information on what one word means to another grammatically; whether it is a subject, an auxiliary verb, or a root, and so on. spaCy has a method ‘.dep_’ of the ‘doc’ object which describes the syntactic dependencies of the tokens.
We iterate over all the tokens and apply the ‘.dep_’ method.
for token in doc: print(token.text, '-->', token.dep_)
output:
KDNuggets --> nsubj is --> ROOT a --> det wonderful --> amod website --> attr to --> aux learn --> relcl machine --> compound learning --> dobj with --> prep python --> pobj
Named Entity Recognition
All the real-world objects have a name assigned to them for recognition and likewise, they are grouped into a category. For instance, the terms ‘India’, ‘U.K.’, and ‘U.S.’ fall under the category of countries whereas ‘Microsoft’, ‘Google’, and ‘Facebook’ belong to the category of organizations. spaCy already has trained models in the pipeline that can determine and predict the categories of such named entities.
We will access the named entities by using the ‘.ents’ method over the ‘doc’ object. We will display the text, start character, end character, and label of the entity.
for ent in doc.ents: print(ent.text, ent.start_char, ent.end_char, ent.label_)
output:
KDNuggets 0 9 ORG
Word Vectors and Similarity
Often in NLP, we wish to analyze the similarity of words, sentences, or documents which can be used for applications such as recommender systems or plagiarism detection tools to name a few. The similarity score is calculated by finding the distance between the word embeddings, i.e., the vector representation of words. spaCy provides this functionality with medium and large pipelines. The larger pipeline is more accurate as it contains models trained on more and diverse data. However, we will use the medium pipeline here just for the sake of understanding.
We first define the sentences to be compared for similarity.
nlp = spacy.load("en_core_web_md")
doc1 = nlp("Summers in India are extremely hot.")
doc2 = nlp("During summers a lot of regions in India experience severe temperatures.")
doc3 = nlp("People drink lemon juice and wear shorts during summers.")
print("Similarity score of doc1 and doc2:", doc1.similarity(doc2))
print("Similarity score of doc1 and doc3:", doc1.similarity(doc3))
output:
Similarity score of doc1 and doc2: 0.7808246189842116 Similarity score of doc1 and doc3: 0.6487306770376172
Rule-based Matching
Rule-based matching can be considered similar to regex wherein we can mention the specific pattern to be found in the text. spaCy’s matcher module not only does the mentioned task but also provides access to the document information such as tokens, POS tags, lemmas, dependency structures, etc. which makes extraction of words possible on multiple additional conditions.
Here, we will first create a matcher object to contain all the vocabulary. Next, we will define the pattern of text to be looked for and add that as a rule to the matcher module. Finally, we will call the matcher module over the input sentence.
from spacy.matcher import Matcher
matcher = Matcher(nlp.vocab)
doc = nlp("cold drinks help to deal with heat in summers")
pattern = [{'TEXT': 'cold'}, {'TEXT': 'drinks'}]
matcher.add('rule_1', [pattern], on_match=None)
matches = matcher(doc)
for _, start, end in matches:
matched_segment = doc[start:end]
print(matched_segment.text)
output:
cold drinks Let's also look at another example wherein we attempt to find the word 'book' but only when it is a 'noun'.
from spacy.matcher import Matcher
matcher = Matcher(nlp.vocab)
doc1 = nlp("I am reading the book called Huntington.")
doc2 = nlp("I wish to book a flight ticket to Italy.")
pattern2 = [{'TEXT': 'book', 'POS': 'NOUN'}]
matcher.add('rule_2', [pattern2], on_match=None)
matches = matcher(doc1)
print(doc1[matches[0][1]:matches[0][2]])
matches = matcher(doc2)
print(matches)
output:
book []
In this blog, we looked at how to install and get started with spaCy. We also explored the various basic functionalities it provides such as tokenization, lemmatization, dependency parsing, parts-of-speech tagging, named entity recognition and so on. spaCy is a really convenient library when it comes to developing NLP pipelines for production purposes. Its detailed documentation, simplicity of use, and variety of functions make it one of the widely used libraries for NLP.
Yesha Shastri is a passionate AI developer and writer pursuing Master’s in Machine Learning from Université de Montréal. Yesha is intrigued to explore responsible AI techniques to solve challenges that benefit society and share her learnings with the community.