Multivariate Time-Series Prediction with BQML
Google's BQML can be used to make time series models, and recently it was updated to create multivariate time series models. With the simple code, this article shows how to use it to predict multivariate time series and it can be more powerful than a univariate time series model in this article.
Image from Pexels
Last winter, I gave a presentation on ‘More predictable time-series model with BQML’ at GDG DevFest Tashkent 2022 in Tashkent, the capital of Uzbekistan.
I was going to share some of the material and code after DevFest I used in the presentation, but time has passed, and new features have been released in BQML that overlap some of the content.
Therefore, I’ll instead mention the new features and some of the things that are still valid briefly.
Time-Series Model and BQML
Time series data is used by many organizations for a variety of purposes, and it’s important to note that “predictive analytics” is all about the “future” in time. Time series predictive analytics has been used in the short, medium, and long term, and while it has many inaccuracies and risks, it has also been steadily improving.
Since “prediction” seems to be so useful, you might be tempted to apply a time series prediction model if you have time series data. But time series prediction models are usually computationally intensive, and if you have a lot of data, it will be more computationally intensive. So it’s cumbersome and hard to process it, load it to the analytics environment and analyze it
If you are using Google BigQuery for data management, you can use BQML (BigQuery ML) to apply machine learning algorithms to your data in a simple, easy, and fast way. A lot of people use BigQuery to process a lot of data, and a lot of that data is often time series data. And BQML also supports time series models.
The basis of the time series model currently supported by BQML is the AutoRegressive Integrated Moving Average (ARIMA) model. The ARIMA model predicts using only existing time series data and is known to have good short-term prediction performance, and since it combines AR and MA, it is a popular model that can cover a wide range of time series models.
However, this model is computationally intensive overall, and since it only utilizes time series data with normality, it is difficult to use it in cases with trends or seasonality. Therefore, ARIMA_PLUS in BQML includes several additional features as options. You can add time series decomposition, seasonality factors, spikes and dips, coefficient changes, and more to your model, or you can go through them separately and manually adjust the model. I also personally like the fact that you can adjust for periodicity by automatically incorporating holiday options, which is one of the benefits of using a platform that doesn’t require you to manually add informations related to dates.
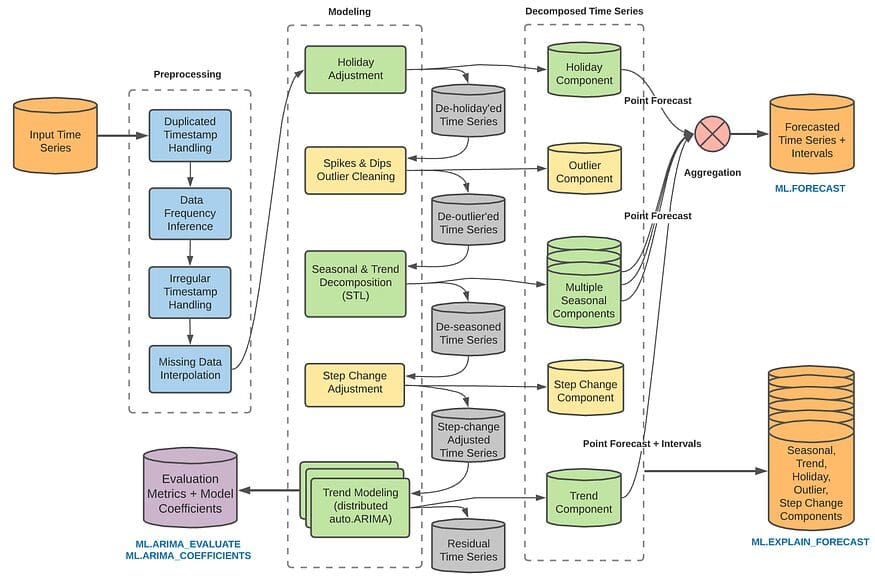
Structure of ARIMA_PLUS (from BQML Manual)
You can refer to this page for more information.
However, when it comes to real-world applications, time series prediction is not as simple as this. Of course, we’ve been able to identify multiple cycles and add interventions to multiple time series with ARIMA_PLUS, but there are many external factors related to time series data, and only very few events happen in isolation. Stationarity can be hard to find in time-series data.
In the original presentation, I looked at how to deal with these real-world time series data for making prediction model- to decompose these time series, clean up the decomposed data, import it into Python, and then weave it with other variables to create a multivariate time series function, estimate causality and incorporate it into a prediction model, and estimate the degree to which the effect varies with changes in events.
New Feature: ARIMA_PLUS_XREG
And in the only last few months, a new feature for creating multivariate time series functions with external variables(ARIMA_PLUS_XREG, XREG below) has become an outright feature in BQML.
You can read all about it here(it’s in preview as of July 2023, but I’m guessing it’ll be available later this year).
I apply the official tutorial to see how it compares to a traditional univariate time series model and we can see how it works.
The steps are the same as in the tutorial, so I won’t duplicate them, but here are the two models I created. First, I created a traditional ARIMA_PLUS model and then an XREG model using the same data but adding the temperature and wind speed at the time.
# ARIMA_PLUS
# ARIMA_PLUS
CREATE OR REPLACE MODEL test_dt_us.seattle_pm25_plus_model
OPTIONS (
MODEL_TYPE = 'ARIMA_PLUS',
time_series_timestamp_col = 'date',
time_series_data_col = 'pm25') AS
SELECT date, pm25
FROM test_dt_us.seattle_air_quality_daily
WHERE date BETWEEN DATE('2012-01-01') AND DATE('2020-12-31')
#ARIMA_PLUS_XREG
CREATE OR REPLACE MODEL test_dt_us.seattle_pm25_xreg_model
OPTIONS (
MODEL_TYPE = 'ARIMA_PLUS_XREG',
time_series_timestamp_col = 'date',
time_series_data_col = 'pm25') AS
SELECT date, pm25, temperature, wind_speed
FROM test_dt_us.seattle_air_quality_daily
WHERE date BETWEEN DATE('2012-01-01') AND DATE('2020-12-31')
A model that uses these multiple data would look something like this
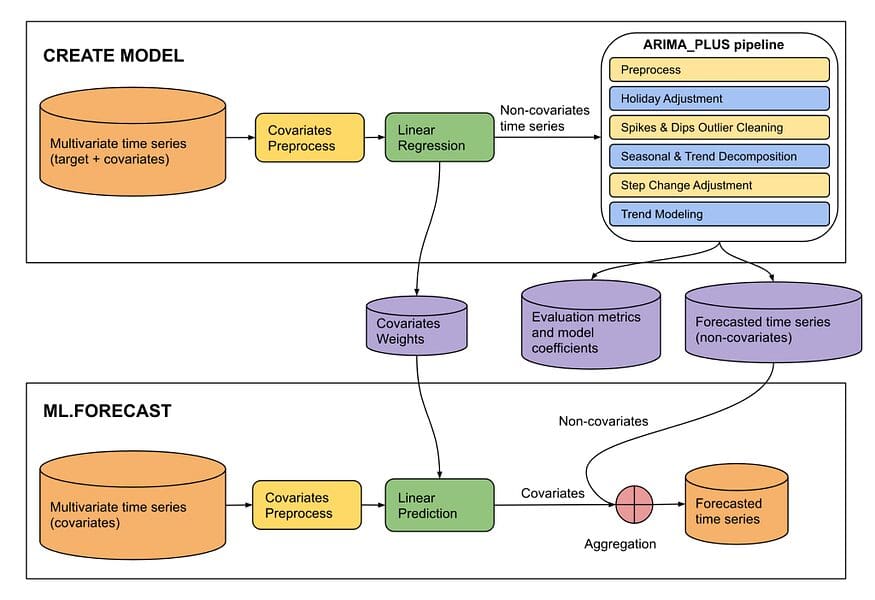
Structure ARIMA_PLUS_XREG (from BQML Manual)
Two models are compared with ML.Evaluate.
SELECT *
FROM ML.EVALUATE
( MODEL test_dt_us.seattle_pm25_plus_model,
( SELECT date, pm25
FROM test_dt_us.seattle_air_quality_daily
WHERE date > DATE('2020-12-31') ))
SELECT *
FROM ML.EVALUATE
( MODEL test_dt_us.seattle_pm25_xreg_model,
( SELECT date, pm25, temperature, wind_speed
FROM test_dt_us.seattle_air_quality_daily
WHERE date > DATE('2020-12-31') ),
STRUCT( TRUE AS perform_aggregation, 30 AS horizon))
Results are below.
ARIMA_PLUS

ARIMA_PLUS_XREG

You can see that the XREG model is ahead on basic performance metrics such as MAE, MSE, and MAPE. (Obviously, this is not a perfect solution, data-dependent, and we can just say that we got another useful tool.)
Multivariate time series analysis is a much-needed option in many cases, but it’s often difficult to apply due to various reasons. Now, we can use it if the reasons are in data and analysis steps. It looks like we have a good option for that, so it’s good to know about it and hopefully it will be useful in many cases.
JeongMin Kwon is a freelance senior Data Scientist in 10+ years of hands-on experience leveraging machine learning models and data mining.