Interview: Vince Darley, King.com on the Serious Analytics behind Casual Gaming
We discuss key characteristics of social gaming data, ML use cases at King, infrastructure challenges, major problems with A-B testing and recommendations to resolve them.
 Vince Darley is the Vice President Data Analytics and BI at King, a leading interactive entertainment company for the mobile world and creator of games such as Candy Crush Saga. King listed on the NYSE in March 2014 (NYSE: KING).
Vince Darley is the Vice President Data Analytics and BI at King, a leading interactive entertainment company for the mobile world and creator of games such as Candy Crush Saga. King listed on the NYSE in March 2014 (NYSE: KING).
With more than 17 years’ experience in data science, at King, Vince oversees a team working on all aspects of analytics and business intelligence, including downstream and upstream data pipelines, data warehousing, real-time and batch reporting, segmentation and real-time analytics – information which is used across the business to improve the player experience.
Vince holds a Master of Arts and PhD in Complex Systems from Harvard University and a Bachelor of Arts in Mathematics from the University of Cambridge. He is also a published author, having co-authored ‘A NASDAQ market Simulation: Insights on a Major Market from the Science of Complex Adaptive Systems.’
Here is my interview with him:
Anmol Rajpurohit: Q1. What are the key characteristics of game and player data that you deal with? What are the major challenges in deriving actionable insights from this data?
 Vince Darley: Most of our data looks at the attempts players are making in our games’ levels –such as scores, stars, time-stamps, whether or not the players succeeded or failed in a level and also what aspect made players fail. We also track the help players give to their friends - for example sending lives or moves - and finally, any financial transactions.
Vince Darley: Most of our data looks at the attempts players are making in our games’ levels –such as scores, stars, time-stamps, whether or not the players succeeded or failed in a level and also what aspect made players fail. We also track the help players give to their friends - for example sending lives or moves - and finally, any financial transactions.
One of the great features of our games is that you can play anytime, anywhere and on any device. From a data point of view, this can present a challenge in that we need to carefully merge together very varied data and identifiers to create a clear picture of the individual player. This can be hard because of the data volume (10-20 billion events/day), and because the data is (as all big data is!) noisy.
But getting this right is super important – there’s a big difference between someone who has bought a new device to play on (and therefore doesn't play much on the old device) vs someone who is losing interest and hardly playing on their only device. Secondly, we of course only observe behavior, but for insights to be usefully actionable we need to deduce something about the player’s motivation/state-of-mind, so that we can take the right action. That is hard!
AR: Q2. What are the most common use cases of Machine Learning and Predictive Analytics at King?
VD: King really cares about the long-term perspective, so perhaps the most common case is about predicting or modeling the long-term customer-lifetime-value impact of a game/network feature-change on particular groups of players.
Another common, but very difficult, case is that of predicting that a player is going to stop playing. This is hard because it is only useful if we can predict this very early, for example while the player is still playing.
AR: Q3. On the infrastructure side, how did you adapt your data architecture to manage the rapid growth in data? Any important lessons from this experience?
VD: We've had to adapt several times over the last 3-4 years.
 The first big change came when our games took off on Facebook’s platform and we put Hadoop into action to allow us to scale to millions of players. Hadoop has served us well through our explosive growth with the tremendous success of our Saga games to 100s of millions of players on mobile as a relatively cheap, effective “supertanker” for (today) 2 petabytes of compressed data. I say “supertanker” because Hadoop is big, solid, but not very nimble.
The first big change came when our games took off on Facebook’s platform and we put Hadoop into action to allow us to scale to millions of players. Hadoop has served us well through our explosive growth with the tremendous success of our Saga games to 100s of millions of players on mobile as a relatively cheap, effective “supertanker” for (today) 2 petabytes of compressed data. I say “supertanker” because Hadoop is big, solid, but not very nimble.
So, over a year ago we added an Exasol system alongside Hadoop – this is a very fast, in-memory analytics database – and allows us to do our core processing (the ETL for example) much more quickly – reducing nightly processing from 8-12 hours down to 1-2. There are a few key lessons here.
 Firstly, at our scale (149 million daily active users as of Q4 2014) there is no one-size fits all solution – hybrid solutions such as our Hadoop/Exasol combination are needed. Secondly, we recently let our Hadoop cluster fill up a bit too much, which made it surprisingly fragile. Best to leave a decent amount of headroom.
Firstly, at our scale (149 million daily active users as of Q4 2014) there is no one-size fits all solution – hybrid solutions such as our Hadoop/Exasol combination are needed. Secondly, we recently let our Hadoop cluster fill up a bit too much, which made it surprisingly fragile. Best to leave a decent amount of headroom.
On the BI side we've used QlikView for our standardized reporting for several years and that has generally served us well. At our scale of many
 100s of millions of all-time players (of which some 356 million monthly active), building reports that allow us to quickly slice’n’dice by cohort, country, game, segment, acquisition channel, platform can be problematic. QlikView can sometimes feel a bit sluggish, and it isn't very self-aware (i.e. it surprisingly doesn't provide much support for monitoring the business user’s experience of report latency, load-time, response time, etc). But overall we’re comfortable with its pros/cons vs other things on the market right now.
100s of millions of all-time players (of which some 356 million monthly active), building reports that allow us to quickly slice’n’dice by cohort, country, game, segment, acquisition channel, platform can be problematic. QlikView can sometimes feel a bit sluggish, and it isn't very self-aware (i.e. it surprisingly doesn't provide much support for monitoring the business user’s experience of report latency, load-time, response time, etc). But overall we’re comfortable with its pros/cons vs other things on the market right now.
All of our data infrastructure is in-house, although we keep ourselves aware of what’s going on in cloud services.
AR: Q4. What are the common problems with A-B testing? What are your recommendations to avoid/mitigate those problems?
VD: Well I could speak for hours about A-B testing, so let’s focus on just a few core difficulties. First of all in our industry (free to play games), almost all metrics are very skewed/long-tailed – this means small numbers of players can easily skew the analysis. Second we’d like our players to have a consistent experience across their multiple devices, so that complicates testing. Third, sometimes effects/impacts are subtle and so we might need to run an experiment for quite a long time to get a conclusive outcome. Fourth, we’d like what we learn in one game to be insightful enough that it informs decisions in other games, but its much easier to design AB-tests that tell you about a specific game than it is to design tests that tell you about the player.
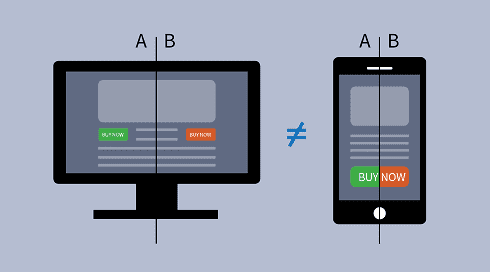
Recommendations? Employ some good data scientists to deal with the statistical subtleties! Decide whether you need to know and precisely quantify “the answer” or just be sufficiently confident you can make a sensible decision – that will allow you to decide when to run an experiment for a short vs long time. Lastly focus on the player and their experience in the experiment design stage, rather than just “does feature A or feature B give me better metrics?”.
Second part of the interview
Related: