Data Science 101: Preventing Overfitting in Neural Networks
Overfitting is a major problem for Predictive Analytics and especially for Neural Networks. Here is an overview of key methods to avoid overfitting, including regularization (L2 and L1), Max norm constraints and Dropout.
One of the major issues with artificial neural networks is that the models are quite complicated. For example, let's consider a neural network that's pulling data from an image from the MNIST database (28 by 28 pixels), feeds into two hidden layers with 30 neurons, and finally reaches a soft-max layer of 10 neurons. The total number of parameters in the network is nearly 25,000. This can be quite problematic, and to understand why, let's take a look at the example data in the figure below.
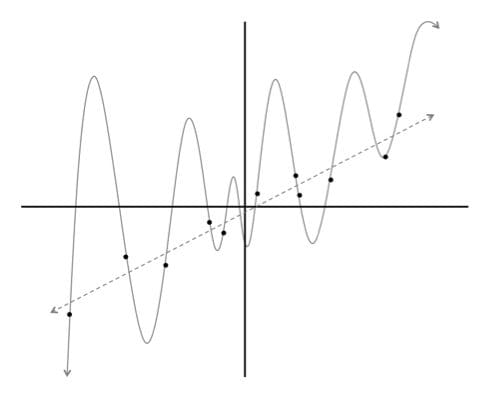
Fig 1. Linear model vs degree 12 polynomial, few points
Using the data, we train two different models - a linear model and a degree 12 polynomial. Which curve should we trust? The line which gets almost no training example correctly? Or the complicated curve that hits every single point in the dataset? At this point we might trust the linear fit because it seems much less contrived. But just to be sure, let's add more data to our dataset! The result is shown below.
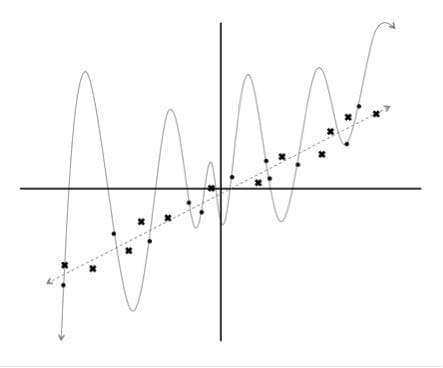
Fig 2. Linear model vs degree 12 polynomial, more points
Now the verdict is clear, the linear model is not only subjectively better, but now also quantitatively performs better as well (measured using the squared error metric). But this leads to a very interesting point about training and evaluating machine learning models. By building a very complex model, it's quite easy to perfectly fit our dataset. But when we evaluate such a complex model on new data, it performs very poorly. In other words, the model does not generalize well.
This is a phenomenon called overfitting, and it is one of the biggest challenges that a machine learning engineer must combat. This becomes an even more significant issue in deep learning, where our neural networks have large numbers of layers containing many neurons. The number of connections in these models is astronomical, reaching the millions. As a result, overfitting is commonplace.
Let's see how this looks in the context of a neural network. Let's say we have a neural network with two inputs, a soft-max output of size two, and a hidden layer with 3, 6, or 20 neurons (respectively). We train these networks using mini-batch gradient descent (batch size 10), and the results, visualized using the ConvnetJS library, are shown below.
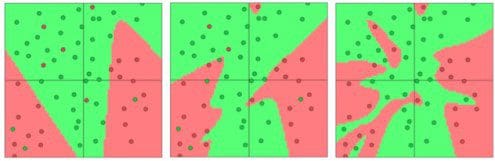
Fig 3. Separating green dots vs red dots , with one hidden layer of 3, 6, 20 neurons
It's already quite apparent from these images that as the number of connections in our network increases, so does our propensity to overfit to the data. We can similarly see the phenomenon of overfitting as we make our neural networks deep. These results are shown in the following figure, where we use networks that have 1, 2, or 4 hidden layers (respectively) of 3 neurons each.
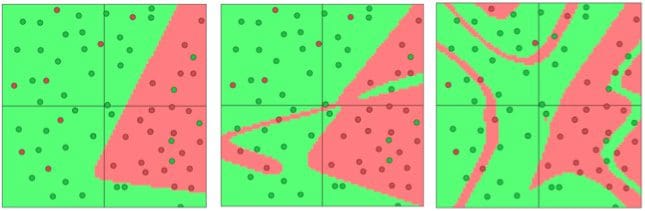
Fig 4. Separating green dots vs red dots, with 1, 2, or 4 hidden layers
In general, the machine learning engineer is always working with a direct trade-off between overfitting and model complexity. If the model isn't complex enough, it may not be powerful enough to capture all of the useful information necessary to solve a problem. However, if our model is very complex (especially if we have a limited amount of data at our disposal), we run the risk of overfitting. Deep learning takes the approach of solving very complex problems with complex models and taking additional countermeasures to prevent overfitting.