Spark + Deep Learning: Distributed Deep Neural Network Training with SparkNet
Training deep neural nets can take precious time and resources. By leveraging an existing distributed batch processing framework, SparkNet can train neural nets quickly and efficiently.
Deep learning is the hottest machine learning method there is, and it continues to achieve remarkable results.
Deep neural networks have continually proven both useful and innovative. The technology has demonstrated its ability to make significant gains in previously stalled research areas, and has forced some to question whether it may be the apex of machine learning. While not magic (but, perhaps, from the devil), deep learning is certainly a complex field of study, and has managed to, on occasion, surprise even to the most knowledgeable in the field.

Deep neural networks can also take precious time and resources to train. Previous attempts have been made to facilitate parameter coordination in clustered training environments, and leading frameworks such as Theano aim to have their packages taking advantage of distributed GPU clusters in the near term. But what about the possibility of leveraging the structure of existing batch processing distributed frameworks for training these networks?
Distributed data processing frameworks such as Hadoop or Spark have enjoyed widespread adoption and success over the past decade. The original MapReduce paradigm and its spin-off processing algorithms, derivative technologies, and support tools have become a staple of modern data science and analytics, and show no sign of relenting their grip. The ubiquity of Apache Spark implementations in the wild could provide an ideal vehicle for the mass training of deep neural networks, if such a framework could, indeed, be leveraged.
 And this is where we introduce SparkNet, what its developers at UC Berkeley's AMPLab describe, quite simply, as implementing a "scalable, distributed algorithm for training deep networks." They also point out what is a likely selling point: it lends itself to frameworks such as Spark and works effectively in limited bandwidth environments out of the box. SparkNet is built on top of Spark and Caffe.
And this is where we introduce SparkNet, what its developers at UC Berkeley's AMPLab describe, quite simply, as implementing a "scalable, distributed algorithm for training deep networks." They also point out what is a likely selling point: it lends itself to frameworks such as Spark and works effectively in limited bandwidth environments out of the box. SparkNet is built on top of Spark and Caffe.
SparkNet Overview
SparkNet was originally introduced in this paper by Moritz, Nishihara, Stoica, and Jordan (2015). It is open source software available here. Along with the core concept of a scalable, distributed deep neural network training algorithm, SparkNet also includes an interface for reading from Spark's data abstraction, known as the Resilient Distributed Dataset (RDD), a Scala interface for interacting with the Caffe deep learning framework (which is written in C++), and a lightweight tensor library.
Perhaps most importantly, the developers claim that there are numerous additional benefits to realize by integrating deep learning into an existing data processing pipeline. A framework such as Spark would allow cleaning, preprocessing, and other data-related tasks to be handled via the single system, and datasets could be kept in memory for the entire processing pipeline, eliminating expensive disk writes.
The hardware requirements for SparkNet are minimal. Additionally, SparkNet's parallelized stochastic gradient decent (SGD) algorithm requires minimal communication between nodes. The developers also stress that their goal is not to outperform existing computational frameworks, but instead to provide an entirely different paradigm, which just happens to be implemented on top of a popular batch framework such as Apache Spark, and which performs nearly as well as specialized deep learning frameworks, with the additional benefits outlined above.
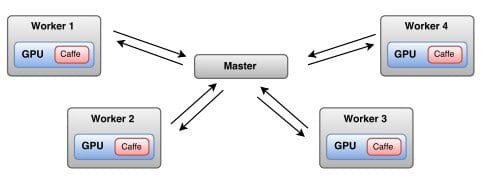
 The parallelization scheme sees data split among the Spark worker nodes, and at each iteration the master node broadcasts the model parameters to all of the workers. Each worker runs a predetermined number of iterations of SGD on its subset of data, up to a maximum length of time. The resulting parameters are sent to the master node, where they are averaged into new model parameters.
The parallelization scheme sees data split among the Spark worker nodes, and at each iteration the master node broadcasts the model parameters to all of the workers. Each worker runs a predetermined number of iterations of SGD on its subset of data, up to a maximum length of time. The resulting parameters are sent to the master node, where they are averaged into new model parameters.
Clearly this approach can require significant broadcasting and collection of parameters between episodes of SGD, and so tuning the architecture will be necessary. SparkNet's authors make such tuning recommendations within their paper, as well as provide experiment results.
While the paper focuses solely on gradient decent, the authors claim that SparkNet works with any Caffe solver.
Caffe is written in C++, and so a wrapper is used for interaction between it and SparkNet. A Java API is used to call this C wrapper. While the Java API can be called directly, it is recommended to use it via the Scala CaffeNet class to facilitate Spark operation (Spark itself is written in Scala). Caffe reads data from Spark RDDs via a custom JavaDataLayer.
Deep neural networks have continually proven both useful and innovative. The technology has demonstrated its ability to make significant gains in previously stalled research areas, and has forced some to question whether it may be the apex of machine learning. While not magic (but, perhaps, from the devil), deep learning is certainly a complex field of study, and has managed to, on occasion, surprise even to the most knowledgeable in the field.

Deep neural networks can also take precious time and resources to train. Previous attempts have been made to facilitate parameter coordination in clustered training environments, and leading frameworks such as Theano aim to have their packages taking advantage of distributed GPU clusters in the near term. But what about the possibility of leveraging the structure of existing batch processing distributed frameworks for training these networks?
Distributed data processing frameworks such as Hadoop or Spark have enjoyed widespread adoption and success over the past decade. The original MapReduce paradigm and its spin-off processing algorithms, derivative technologies, and support tools have become a staple of modern data science and analytics, and show no sign of relenting their grip. The ubiquity of Apache Spark implementations in the wild could provide an ideal vehicle for the mass training of deep neural networks, if such a framework could, indeed, be leveraged.
 And this is where we introduce SparkNet, what its developers at UC Berkeley's AMPLab describe, quite simply, as implementing a "scalable, distributed algorithm for training deep networks." They also point out what is a likely selling point: it lends itself to frameworks such as Spark and works effectively in limited bandwidth environments out of the box. SparkNet is built on top of Spark and Caffe.
And this is where we introduce SparkNet, what its developers at UC Berkeley's AMPLab describe, quite simply, as implementing a "scalable, distributed algorithm for training deep networks." They also point out what is a likely selling point: it lends itself to frameworks such as Spark and works effectively in limited bandwidth environments out of the box. SparkNet is built on top of Spark and Caffe. SparkNet Overview
SparkNet was originally introduced in this paper by Moritz, Nishihara, Stoica, and Jordan (2015). It is open source software available here. Along with the core concept of a scalable, distributed deep neural network training algorithm, SparkNet also includes an interface for reading from Spark's data abstraction, known as the Resilient Distributed Dataset (RDD), a Scala interface for interacting with the Caffe deep learning framework (which is written in C++), and a lightweight tensor library.
Perhaps most importantly, the developers claim that there are numerous additional benefits to realize by integrating deep learning into an existing data processing pipeline. A framework such as Spark would allow cleaning, preprocessing, and other data-related tasks to be handled via the single system, and datasets could be kept in memory for the entire processing pipeline, eliminating expensive disk writes.
The hardware requirements for SparkNet are minimal. Additionally, SparkNet's parallelized stochastic gradient decent (SGD) algorithm requires minimal communication between nodes. The developers also stress that their goal is not to outperform existing computational frameworks, but instead to provide an entirely different paradigm, which just happens to be implemented on top of a popular batch framework such as Apache Spark, and which performs nearly as well as specialized deep learning frameworks, with the additional benefits outlined above.
 The parallelization scheme sees data split among the Spark worker nodes, and at each iteration the master node broadcasts the model parameters to all of the workers. Each worker runs a predetermined number of iterations of SGD on its subset of data, up to a maximum length of time. The resulting parameters are sent to the master node, where they are averaged into new model parameters.
The parallelization scheme sees data split among the Spark worker nodes, and at each iteration the master node broadcasts the model parameters to all of the workers. Each worker runs a predetermined number of iterations of SGD on its subset of data, up to a maximum length of time. The resulting parameters are sent to the master node, where they are averaged into new model parameters. Clearly this approach can require significant broadcasting and collection of parameters between episodes of SGD, and so tuning the architecture will be necessary. SparkNet's authors make such tuning recommendations within their paper, as well as provide experiment results.
While the paper focuses solely on gradient decent, the authors claim that SparkNet works with any Caffe solver.
Caffe is written in C++, and so a wrapper is used for interaction between it and SparkNet. A Java API is used to call this C wrapper. While the Java API can be called directly, it is recommended to use it via the Scala CaffeNet class to facilitate Spark operation (Spark itself is written in Scala). Caffe reads data from Spark RDDs via a custom JavaDataLayer.