Learn Deep Learning by Building 15 Neural Network Projects in 2022
Here are 15 neural network projects you can take on in 2022 to build your skills, your know-how, and your portfolio.

Photo by Possessed Photography on Unsplash
With the invention of computers, many people talked about the fact that computers will never surpass human performance, whether it is beating a champion at chess or solving a Rubik Cube. Well, computers today can do all of those things. All thanks to Neural Networks for changing the world and the nay-sayers! Neural Networks have been around since the 1950s, but it was only in the last two decades that people have been able to realize their true power. Deep learning and neural networks have found their way into our daily lives since 2012. Since then, neural nets have contributed to drug discovery and medical diagnosis to Netflix recommendations. And the growth is not faltering anytime soon; the number of neural net parameters has risen from a few hundred thousand to 1 trillion within ten years. There are countless deep learning applications that we can build with neural networks, but here are 15 that are on my list to build in 2022. Building these neural network projects will give the machine learning skills and knowledge required to build diverse deep learning applications.
If you want to learn and try your hands-on how to build each of these neural network projects, check out these solved Deep Learning and Neural Network Projects, where you’ll learn to create impressive beginner to advanced level deep learning applications.
15 Neural Network Projects You Should Build in 2022
Neural Network Project Ideas Using Convolutional Neural Networks (CNNs)
A CNN is a neural network that relies on the convolution operation to extract features from a given input (typically an image). Convolutions are performed sequentially by filters of varying sizes along with other transformations such as pooling and normalization to extract and learn patterns from the data.
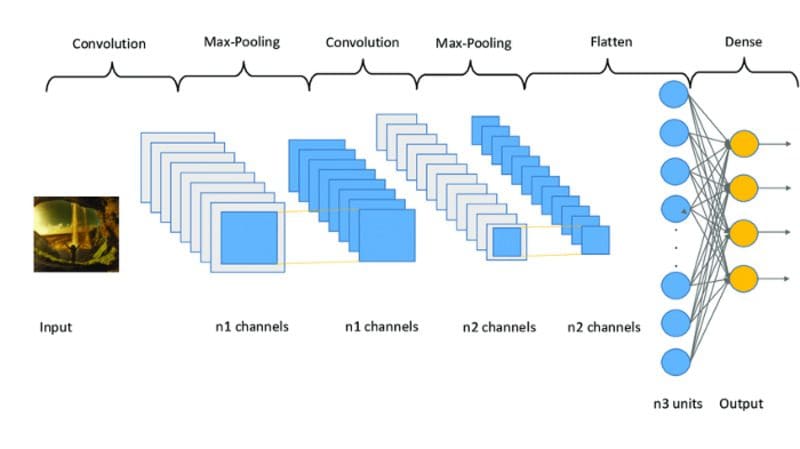
Image Source
1) Optical Character Recognition (OCR) for Handwritten Text
The work on Optical character recognition (OCR) for printed text has been in progress for several decades. With the rise in deep convolutional neural networks, even mangily handwritten text is now (somewhat) legible to the machines. OCR is being used widely today with license plate recognition for arresting speeders, automatically reporting and filtering offensive and inappropriate posts from social media websites, and processing identification online simply by scanning personal documents like passports and driving licenses. Handwriting is more difficult to process both for humans and machines alike. But automating it with handwritten OCR has applications in digitizing millions of antique documents and newspaper clippings, processing scanned hand-filled application forms and even online learning with digital scribble pads.
Several state-of-the-art OCR models prove their benchmarks on the IAM handwritten dataset, and you can use it for free to test your model. Using empirical analysis, you can build a CNN architecture for your dataset simply using Conv2D and MaxPooling2D layers. A sample below defines the second layer taking input from the first layer, “pool_1”.

Adding an RNN or Bi-LSTM layer at the very end can help improve the recognition significantly. Why? Well, handwriting in the same document tends to have some consistency. Learnings from that consistency would help improve predictions as we move further ahead in a sentence or document. This added component can even help the model converge with fewer data than a simple CNN. You can use the keras.layers.recurrent.GRU module for RNN and keras.layers.Bidirectional for a Bi-LSTM unit.
Datasets To Try Your Hands-On: IAM Handwriting Top50, Handwriting Recognition(OCR), Dataset Doctor’s prescription, Kaggle Handwriting Recognition
2) Disease Diagnosis from Medical Reports
Automating the reading of chest X-rays and blood cell images can hasten the diagnosis of chronic diseases like tuberculosis and cancer and potentially save lives with the precision achieved by neutral networks in detecting these ailments from the onset. During the latest pandemic, this application found a real-time use case in alleviating the workload of several healthcare facilities.
By training a deep CNN with annotated images of chest XRays, one can reliably predict the onset of a particular disease, especially COVID-19. You can find a preliminary dataset here. This neural network project idea is an excellent opportunity to exploit transfer learning to achieve good performance and rapid convergence with a small dataset. Using pre-trained weights of state-of-the-art CNN architectures like ResNet50 and Xception on the popular ImageNet dataset, you can easily fine-tune these complex models for your use case.
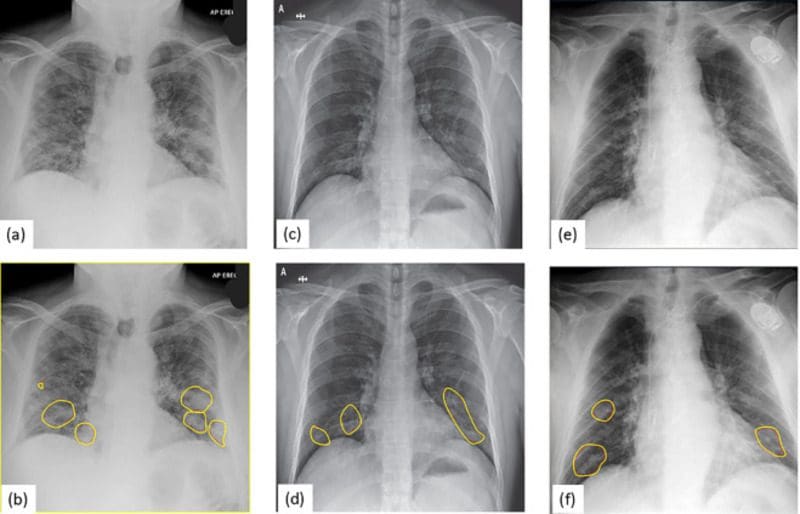
Image Source
Using the available chest XRay datasets, one can load these models from Keras with the include_top flag set to False (this means that the final layer will be omitted while loading). You can then define your dense layer, which will be trained based on the classes and images of your dataset.
Datasets To Try Your Hands-On: NIH Dataset, Chest X-Ray Images (Pneumonia), PADCHEST — BIMCV, Extensive COVID-19 X-Ray, and CT Chest Images Dataset, Blood Cell Images
3) Document Classification
Several industries such as insurance, accounting, and judicial employ services to sort out the thousands of documents they receive daily into several predefined categories. This categorization is done either using the content of those documents (text/images) or the visual layout (forms, tables, charts). And often, both of these modes are useful for classification. Using deep models, one can make this manually tedious task faster by automating it using trained CNNs or language models.
For visual, image-based classification, one can look at the Tobacco3482 dataset containing images of 10 document types, including forms, memos, reports, ads, and charts. A multi-layer CNN using Conv2D+MaxPooling2D should suffice for a decent classification rate of >85%. Other datasets include RVL-CDIP Dataset.
For a text-based approach, one can use open-source OCR tools like Tesseract or EasyOCR to extract text from their documents and construct a dataset for a text-based approach. Or a very preliminary IMDb movie reviews dataset can be accessed from keras.datasets.imdb. Using a series of Bi-LSTMs (Bidirectional in Keras) with dropout strategies is an excellent way to start. An interesting approach would be to use a Conv1D+MaxPooling1D unit to extract features from an input sentence embedding and train an LSTM on those spatial features.
Datasets To Try Your Hands-On: Cornell Review Polarity, Newsgroups Data Set, AG News, Reuters-21578 Text, BBC Full Text
4) Content-Based Recommender Systems
Recommendation systems are ubiquitous in online retail and content-centric media platforms; even blog pages on a business website have recommendations tailored for every customer. Techniques like collaborative filtering are already famous and widely used, but clubbing and recommending similar content would be the more intelligent.
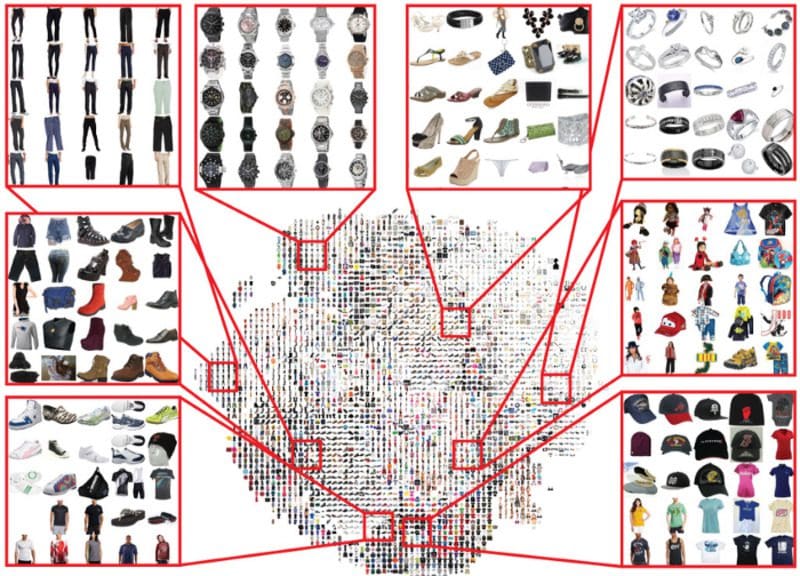
Image Source
You can begin with the Fashion Dataset on Kaggle and work your convolutional model towards learning the representations of these images. One way would be to use transfer learning. Use Keras’ pre-trained ResNet50 model and add a final Pooling layer to learn representations specific to your data. This model will generate an embedding for each fashion item in the dataset. You can now input a particular image to this model, create an embedding, and use cosine similarity to find things that are spatially close to the given item. Thus, you can recommend them reliably to the user.
Datasets To Try Your Hands-On: E-commerce recommendation data, Style Color Images, E-commerce Product Images.
5) Human Activity Detection
While frowned upon by several privacy advocates, surveillance is necessary for some use-cases in a controlled manner. Detecting human activity from CCTV footage for security or as a signal for an automatic door is achievable with deep neural networks in real-time.
For starters, you can head over to the TensorFlow 2 Object Detection API and check the off-the-shelf object detection models they provide. They also provide steps to perform inference on your own image in this notebook. After seeing this, you’ll know what to expect from a human detection system. However, these ready-to-use models work best with a GPU. For now, you can use the free limited GPU on Google Colab.
To work from scratch, you can implement object detection models such as Faster R-CNN using Keras or PyTorch and try your hands-on human detection datasets like Kaggle’s Human Detection Dataset, CrowdHuman Dataset, and Pedestrian Detection Database.
6) Semantic Segmentation of Road Objects
Semantic segmentation involves classifying every pixel in an image to a predefined object class; it creates masks around an object of a particular category. Segmentation, one of the most practical applications of CNN is used by self-driving cars in locating and tracking objects on the road, including the road itself, by satellite cameras to detect natural resources or migrating patterns or terrorist settlements from aerial images, and digital tracking maps to segment roads and buildings to draw a guided path.

Image Source
While several heavy-weight architectures have achieved results close to the one shown above, we can start with a reasonably decent architecture, as shown below.
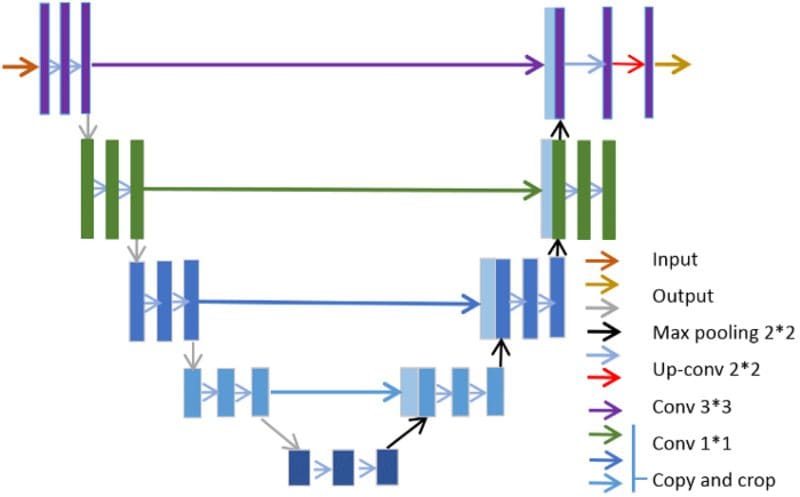
Image Source
As shown on the Keras website, this architecture works on the concept of downsampling an image to learn its basic representations and then learning to upsample it, finally generating a mask-like image. For now, some of the best-performing semantic segmentation models include HRNet, DeepLab, and ASPP.
Datasets To Try Your Hands-On: ADE20K dataset, MIT Scene Parsing Benchmark, RTK Dataset, Visual Geometry Group: Pet Dataset, parissculpt360
Neural Network Project Ideas Using Long Short-Term Memory (LSTM)
LSTM is a type of Recurrent Neural Network that works on sequences of data and retains information learned over time. At each step, the new information learned by the network is added to a “memory” that gets updated based on how important the new knowledge seems to the network. This network has revolutionized speech and handwriting recognition, language understanding, forecasting, and several more normal applications that are normal today.
7) Next Word Prediction
One of the significant challenges in natural language processing and language modeling is learning representations that capture the context of each sentence. While reading, humans can usually track context from words encountered a few words earlier. Similarly, a neural network can also be designed to remember the learnings from the words it encountered for some time to learn better from the following several words or sentences.
Image Source
Next word prediction or generation is the benchmark task to test a language model’s ability to realize and remember past content like a human would. In daily life, we use word predictions while texting or writing emails. More advanced applications include tools that rectify grammar and suggest writing edits or even generate entire essays from a given prompt.
Long Short-term Memory (LSTM) is a neural model that improves the architecture and intuition of previous methods to remember contexts, such as a standard ANN or Recurrent Neural Networks (RNN). A standard LSTM comprises three gates, the input, output, and forget gates. These units learn their own parameters to determine if and how much of the current word should be remembered and how much of the past content should be forgotten.
You can start building your own LSTM using the LSTM module from keras.layers. The text data required for training can be any set of sentences that suit your use case. However, you can use the classics like Shakespeare and Plato as your starting point. It should be noted that mathematical models, including LSTMs, cannot read words/sentences and, thus, need vector representations as input. The Tokenizer module from keras.preprocessing.text is just one of the many ways to achieve these representations. Others include using pretrained word or sentence embeddings like GloVe or FastText.
Datasets To Try Your Hands-On: Project Gutenberg, Medium articles dataset
8) Time Series Prediction using LSTMs
The concept of retaining memory and past content, as demonstrated by LSTMs, is also helpful in cases where the past data is the only way of predicting the present. Weather forecasting, stock price prediction, or even the timeline prediction of diseases like COVID-19 can be made using time series prediction.
Looking at all the data from the beginning of time might be misleading as many of the important factors then are obsolete now. Thus, defining a “window size” or “timesteps” is essential to look at the past while predicting the present/future. Therefore, your data can cluster n timesteps of data together to train an LSTM.
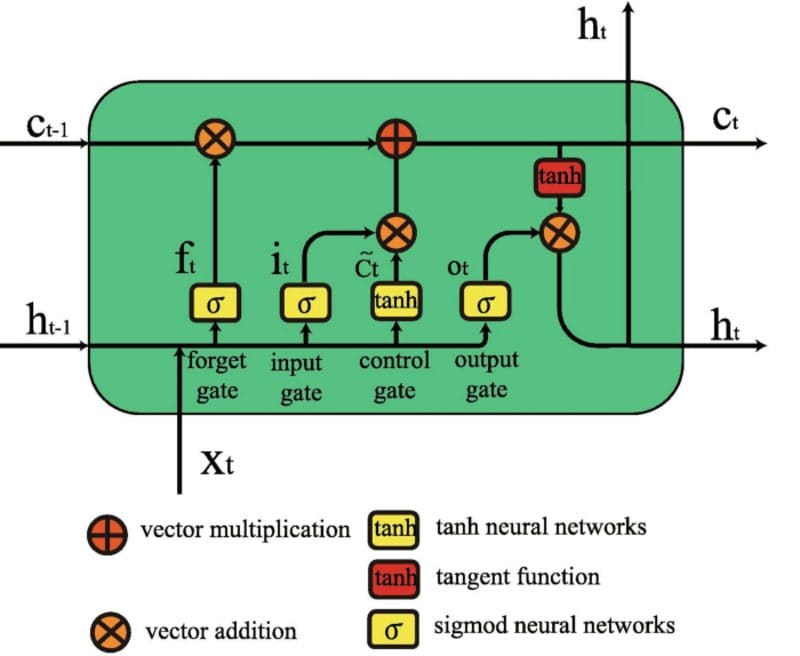
Image Source
You can again use the LSTM module from Keras to achieve this. To make things more challenging, you can use a Sequential model from Keras and build a series of LSTMs followed by a Dense layer to learn more complex relations and improve performance. The COVID-19 India dataset on Kaggle is frequently used for time-series analysis, and now that most of the data have been collected, you can use a portion of the data and confirm the predictions yourself.
Datasets To Try Your Hands-On : Time-series data on data.world, COVID-19 Time Series Data, Novel Corona Virus 2019 Dataset.
9) Conversational Chatbot
Almost every company has an “intelligent” chatbot on its website, but the user experience is certainly not great with all of them. There can be two ways in which a conversational chatbot can reply to a given message: fetch from a set of predefined responses based on the closest match or generate a response of its own. The previous method often yields annoyingly redundant results, and now with advances in conversational AI, the latter is within your reach.
While there are several advanced methods of creating robust chatbots, the best way to start with would be an encoder-decoder architecture using stacked LSTMs. This type of architecture in the context of text generation of any sort is called a sequence-to-sequence (seq2seq) model. It can be achieved using the standard Keras modules of Bidirectional, or LSTM.
Datasets To Try Your Hands-On: For Conversational Chatbot Implementation: The NPS Chat Corpus, ConvAI2, and Cornell Movie-Dialogs Corpus. For Q&A-type chatbots: TREC QA Collection, The WikiQA Corpus, and Question-Answer Database.
10) Text Summarization — Summarization of Large Documents
Another application of seq2seq models is summarizing long-form text into a collection of sentences. This high-level task requires the model to understand the document in its entirety, extract its most important details, and generate coherent sentences that convey that information in the shortest way possible. Researchers can use this tool to summarize dozens of papers and filter out the ones they actually want to spend time reading. Similarly, voice-assistant devices and search engines can also provide quick snippets to the user for a given search query.
Same as before, you can create a seq2seq model with an encore-decoder structure based on stacked LSTMs followed by a Dense layer. Moreover, we can again use transfer learning here by employing GloVe embeddings in the encoder and/or decoder unit to get a headstart on learning sentence representations. You can find GloVe at the Stanford NLP website.
Datasets To Try Your Hands-On: Wiki-summary, yaolu/Multi-XScience, The New York Times Annotated Corpus — Linguistic Data Consortium
11) Text Generation from Prompt
Neural networks have progressed enough to comprehend large amounts of text and generate entire sequences in continuation to a short input prompt. This notion has found immense use in generating product descriptions, promotional emails and also to generate training data to create models that can detect whether a given text was generated by AI.
While models like GPT-3 have achieved the benchmark in this task, we can start from scratch using LSTMs. You can use text from the free ebooks available on Project Gutenberg. After cleaning and vectorizing the data, we can train a Sequential LSTM model on several batches of sentences. Once that is done, you can give the model a test sequence from the ebook and map the output vectors with the character set. You will see that the model was able to continue your input prompt and generate (hopefully) meaningful and relevant sentences.
Datasets To Try Your Hands-On: Shakespeare, DailyDialog Dataset, Nietzsche Texts
12) Neural Machine Translation
Language translation used to be an entire profession before Google Translate and the several powerful language models like GPT. Several multinational businesses would require their documents and web content to be accessible to people across the globe. And while Google Translate might do it for free, not all context is realized by the free tool. To make it specific to one’s use case, one should train the machine translation model by themselves.
Using the previously mentioned seq2seq style architecture, one can easily train such a model with impressive results.
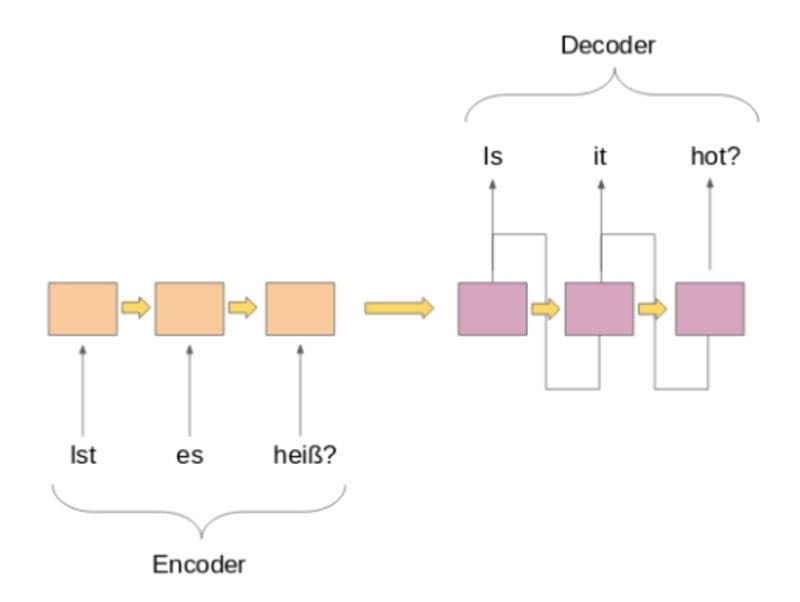
Like previous generational models, translation involves encoding the sentence embeddings into a feature space and using the learnings from that space to decode them into the translated domain. Thus, we can use two LSTM units in Keras with the “return_state” parameter set to True, with one acting as an encoder and the other the decoder.
Datasets To Try Your Hands-On: ANKI, JW300, English to Hindi, Parallel Translation Corpus in 24 languages! (~5M)
13) Fake News Detection
In the past few years, individuals have gotten their news and daily updates from social media or news applications. Not everyone has the time to verify the facts of the stories they read or the headlines that float on social media. And thus, for any organization, it is vital to filter harmful and rumorous news items about themselves. And the same goes for the sites that host these posts. Despite recent language models capable of comprehending large chunks of text and even generating similarly vast amounts of indiscernible content, working on short sentences such as headlines is a challenge.
One method is to train a Bi-LSTM on the headline as well as the content of such news clippings aiming to classify them into real or fake. Another way is to use GloVe embeddings and train deep CNNs using Conv1D+MaxPooling1D. Since this problem is challenging, changing various hyperparameters might lead to drastic improvements in the results. GridSearch is a popular method to find the best set of hyperparameters for your model, and the Python package Talos automates this process for you for your Keras model.
Datasets To Try Your Hands-On — FakeNewsCorpus, Kaggle Fake News, Kaggle Fake News Detection, TI-CNN news dataset.
14) Information Extraction from Unstructured Text
As language models claim to understand large texts, there can be applications where models replace the need for repetitive reading and comprehension by a human. Such applications may be useful in analyzing and processing a huge number of CVs or applications, sorting news articles based on relevance for each user, and processing scanned documents or forms, etc.
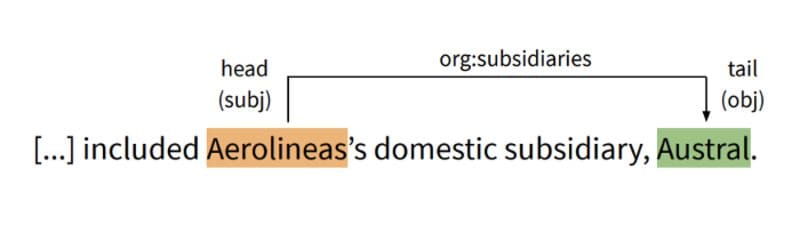
Image Source
This task can be divided into several sub-tasks in standard ML, including named entity recognition (NER), part-of-speech (POS) tagging, and relation extraction. Most of these can be achieved through the SpaCy package in Python. However, this task as a whole can be done effectively by training several stacked LSTMs on unstructured text matched with the targeted information to be extracted from each.
For instance, using the SROIE dataset, you can pick certain fields present in all the documents (date, invoice number, total amount, etc.) and train a model to locate those features in a test document. Other datasets include OPIEC, FUNSD, Resume Entities for NER.
Neural Network Projects Using Convolutional Autoencoders
An Autoencoder is a type of Artificial Neural Network that encodes or downsamples the input into a different feature space, learns from the representations, and attempts to regenerate or decode the features into the target output. Typically, an autoencoder is used to learn mappings or representations by itself between the input and the target making it useful for several tasks like anomaly detection, image translation, and even image generation.
15) Noise Removal using Convolutional Autoencoders
Noisy or blurry images can prove to be devastating to the performance of deep learning-based systems such as face recognition, object detection, or optical character recognition. Different types of noises such as salt-and-pepper, Gaussian, speckle noise may be insignificant to the human eye, but on a pixel level, they are a hurdle for deep learning models, both for training and inference. Moreover, captured images can be blurry for many reasons, including environmental factors or camera lenses. If such unpredictable factors are expected to affect your deployed model, it would be only wise to handle them beforehand.
Autoencoders are a type of artificial neural network composed of an encoder (which compresses the data and thus removes any minor noisy factors) followed by a decoder (which tries to reconstruct the clean image by decompressing the encoded data). Data to train an autoencoder is created by using noisy or blurry images as the features and the clean images as the target. The encoding-decoding architecture of this ANN tries to learn the mapping between the noisy image and the clean image.
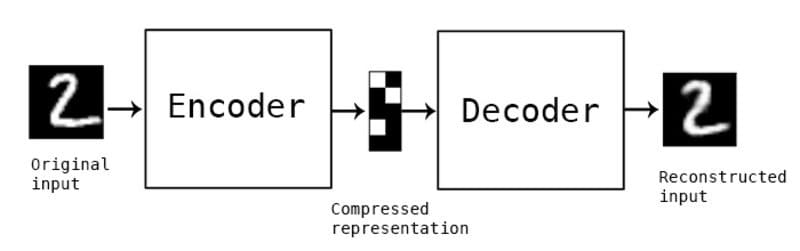
Image source
You can build and train an autoencoder using standard Python libraries for deep learning, such as Keras. The encoder usually comprises stacked convolutional and pooling layers (using Dense, Conv2D, and MaxPooling2D functions) like in a standard CNN but in reducing the number of filters as we go deeper. The decoder is usually a mirrored encoder with an increasing number of filters as we move towards the output, with each followed by UpSampling2D to bring back the original input size. The final intuition of the architecture for a 400x400 RGB image should look something like the image below.
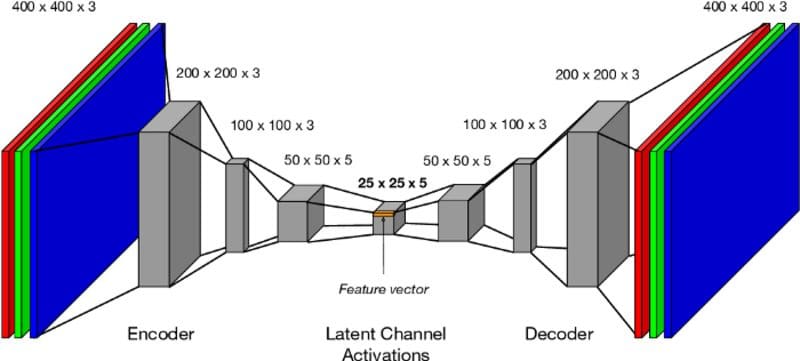
Image Source
However, you can use the MNIST data for starters and add the Gaussian noise generated from numpy.random.normal to images to generate a noisy dataset. You can use OpenCV to generate other types of noisy and blurred images.
Dataset To Try Your Hands-On: ImageNet, CIFAR-10, and CIFAR-100 datasets, fastai/imagenette.
Organizations have realized the power of neural networks and use them heavily in their business. The best way to witness this and get a true idea of how they work is to build something of your own. We saw 15 unique ways to incorporate neural networks into your machine learning project. With these projects, you can observe the relevance of deep learning in the modern world but also be a part of the community through hands-on learning. Thank You for reading, and let’s get doing!
In this article, we have referred to several modules found in Tensorflow-Keras to give an idea of the implementation of each of these projects -
- Input object — Layers API
- Dense layer
- Embedding layer
- Conv1D layer
- Conv2D layer
- MaxPooling1D layer
- MaxPooling2D layer
- LSTM layer
- Bidirectional layer
- Dropout layer
- The Sequential class
- Keras ready-to-use in-built datasets
- Keras Pre-trained Deep Learning models | Applications
Param Raval is a student of engineering with a zeal for Machine Learning and writing.
Original. Reposted with permission.