Distributed TensorFlow Has Arrived
Google has open sourced its distributed version of TensorFlow. Get the info on it here, and catch up on some other TensorFlow news at the same time.
KDnuggets has taken seriously its role to keep up with the newest releases of major deep learning projects, and in the recent past we have seen landmark such releases from major technology giants and as well as universities and research labs. While Microsoft, Yahoo!, AMPLabs, and others have all contributed outstanding projects in their own right, the landscape was most impacted in November, 2015, with the release of what is now the most popular open source machine learning library on Github by a wide margin, Google's TensorFlow.

Some Background
I wrote in the early days after its release of my initial dissatisfaction with the project, based primarily on the lack of distributed training capabilities (especially given that such capabilities were directly alluded to in the accompanying whitepaper's title). There were also a few other - lesser - "issues" I had with it, but the central point of contention was that it was single node only.
This original post was polarizing, with many people upset at my "dismissal" of the tech powerhouse's latest offering (a closer read would reveal that I did not, in any way, dismiss it). Others believed the post to be level-headed and unswayed by the onslaught of early misinformed cheerleading posts ("TensorFlow has changed artificial intelligence!" or "Google brings machine learning to the masses!") that offered no insights into the software at all.
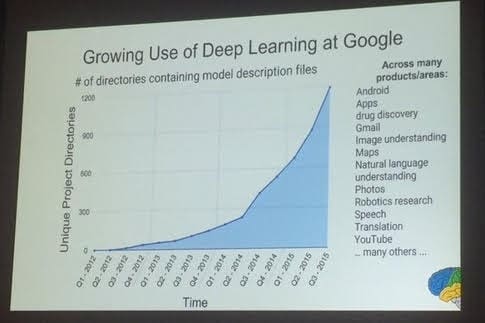
I then followed this up with an update based on a NIPS 2015 tutorial by Jeff Dean and Oriol Vinyals, 2 Googlers heavily involved in the development of TensorFlow, titled "Large-Scale Distributed Systems for Training Neural Networks." The talk was not solely about TensorFlow, but it did play a major role. I outlined a few of the updates on the direction of TensorFlow's development which Dean and Vinyals had provided, including the inevitability of distributed support and the exponential growth of deep learning inside Google. Soon after, KDnuggets' Zachary Chase Lipton shared his overview of TensorFlow, which was also level-headed and provided insight into some of the aspects of TensorFlow which he contended made it a very solid offering. Zachary deemed it the best and most convenient deep learning library available.
The point in here (somewhere) is that TensorFlow has elicited a lot of responses from folks, including those reviewing the software, those using it regularly, and those agreeing or disagreeing with others' views. Which is all (mostly) good. Google has, in some ways, brought deep learning a bit more mainstream in my opinion, given that open source TensorFlow has somehow become a common denominator among interested parties in a very short period of time. Through divisive opinion has come unity; at least everyone was talking about the same product, regardless of their views or vitriol.
And so to now come full circle, this past week Google announced an update to its deep learning library: TensorFlow now supports distributed training.

Distributed TensorFlow
It has actually been a big couple of weeks for distributed deep learning. First, at Spark Summit East, held in NYC from February 16-18, there was a talk given by Christopher Nguyen discussing a distributed version of TensorFlow that was implemented on top of Spark using an abstracted layer, the Distributed DataFrame. Then, just days ago, Yahoo! released a distributed version of Caffe on top of Spark, cleverly named CaffeOnSpark, which you can read more about here. And, finally, distributed TensorFlow.
Distributed TensorFlow is part of the "regular" TensorFlow repo, occupying its own subdirectory within. As noted in its directory's readme, the distributed version of TensorFlow is supported by gRPC, which is a "high performance, open source, general RPC framework that puts mobile and HTTP/2 first," for inter-process communication.
To get started, you have to build a TensorFlow server binary (grpc_tensorflow_server) and a gRPC-based client from source, as the binaries currently available do not support distributed processing. Simple instructions are available for doing so with Bazel, Google's own publicly-available build tool. After the distributed TensorFlow components have been built, this simple test (starting a server) can confirm success:
# Start a TensorFlow server as a single-process "cluster". $ bazel-bin/tensorflow/core/distributed_runtime/rpc/grpc_tensorflow_server \ --cluster_spec='local|localhost:2222' --job_name=local --task_index=0 &
The following code opens a remote session and runs the requisite Hello, (Distributed) World!
import tensorflow as tf c = tf.constant("Hello, distributed TensorFlow!") sess = tf.Session("grpc://localhost:2222") sess.run(c) # 'Hello, distributed TensorFlow!'
The repo readme goes on to outline managing clusters within TensorFlow itself, but also points out that using a cluster manager such as Kubernetes is probably a better idea.
Placing operations on a particular process uses the existing TensorFlow tf.device() function, which obliterates any learning curve. tf.device() was previously (and still is) used to specify CPU or GPU devices, and is extended to workers like this:
# Specify code runs on a GPU with tf.device('/cpu:0'): ... # Similarly, specify a task in the 'worker' job with tf.device("/job:worker/task:7"): ... train_op = ... # Now, launch the job on 'worker7' node with tf.Session("grpc://worker7:2222") as sess: for _ in range(10000): sess.run(train_op)
There is some additional information on replicating network training on the repo's readme. Though I have no way of knowing this definitively, I would wager that some official tutorials are forthcoming. I can all but guarantee that by mid-week there will be a whole host of unofficial tutorials and overviews as well.
TensorFlow Serving
Also recently released on the TensorFlow Github is TensorFlow Serving, which is a "library for serving machine learning models." The library is meant for managing the lives of machine learning models after training, covering the data inference stage. TensorFlow Serving can also perform the management and serving of versioned models, multiple models, multiple versions of the same model, and A/B testing of experimental models, among other tasks.
Serving can also be used for MapReduce and other bulk processing jobs, as well as for model performance analysis. It supports GPU acceleration for both of these scenarios. With a modular architecture, TensorFlow can be modified to deal with more than just TensorFlow models, however, as it allows pass-though to the served model APIs.
More about Serving can be found on its Github repository.
Conclusion
Google has open sourced the distributed TensorFlow engine, and its operation and integration with existing TensorFlow seems to be well-thought out and logical. Yet, in doing so, it has been beaten to the proverbial punch by a few other distributed projects that have been released since TensorFlow's debut in November (AMPLab's SparkNet, Microsoft's CNTK, and - most recently - Yahoo!'s CaffeOnSpark). But does not being first in the this latest wave of deep learning technologies open sourcing hurt TensorFlow at all? I highly doubt it. Even in a landscape where TensorFlow was released amid some criticism that it lacked the anticipated distributed capabilities from go, it has still managed to become more popular than (literally) all of the alternatives out there. This update will just be the little shove that gets people who have been on the fence about TensorFlow to finally give in and give it a try.
In my opinion, Google has now given TensorFlow the engine it requires to steal the share of the market that it (admittedly) seems to have already stolen. Given that Zachary Chase Lipton is more knowledgeable than I regarding deep neural network modeling, and that he sees TensorFlow as the best option that there is (he even goes as far in his article to state that he is in no hurry for any other library to replace it), combined with the back end that I had initially thought to be missing from the release, TensorFlow seems poised at this point to deflect any criticism that could be mounted against it and to continue its march toward solidifying its status as the de facto mainstream deep learning library.
The head-scratcher (at least, in my opinion), is that the release was made very quietly. There doesn't seem to be any big announcement on any Google blog, but the logic may well be to evaluate a soft release before an announcement. But who knows? There are people smarter than I in charge of making these types of decisions, so I'm sure there is reason in there somewhere.
Also, TensorFlow Serving seems to be an industrial strength addition to the ecosystem for those looking to deploy and manage deep learning models in production. The niche that it may carve out has yet to be seen, but there is promise in its flexibility, if model management is something that is of concern to you.
And while it has been around for a while, a recent update has given Scikit-flow, Google's scikit-learn style interface for high level TensorFlow network modeling, has seemingly given it a boost in popularity. A recent KDnuggets article outlines Scikit-flow's usefulness for those new to deep learning as well as those who are familiar with scikit-learn fit/predict API model.
Lastly, don't forget that Udacity and Google are running a deep learning MOOC right now that uses TensorFlow as the vehicle for implementing learned architectures.
There's a lot going on in the TensorFlow world these days.
Related: