Greed, Fear, Game Theory and Deep Learning
The most advanced kind of Deep Learning system will involve multiple neural networks that either cooperate or compete to solve problems. The core problem of a multi-agent approach is how to control its behavior.

Image source.
In a previous story, I wrote about how a Game Theoretic approach was influencing developments in the Deep Learning field. In this story, I now write about DeepMind’s latest foray into this exciting area. In a recent blog post (i.e. Yesterday, February 19th 2017), DeepMind presents their latest research on this subject titled “Understanding Agent Cooperation”.
The gist of the research is that, they employed Deep Reinforcement Learning networks in two game environments to study their behavior. The motivation is to study multi-agent systems to better understand and control these kinds of systems. In a previous story (see: “Five Capability Levels of Deep Learning”, I laid out a road map as to how Deep Learning will evolve in even greater capabilities. For discussion sake, I re-summarize it here again:
1. Classification Only ( C )
This level includes the fully connected neural network (FCN) and the convolution network (CNN) and various combinations of them.
2. Classification with Memory (CM)
This level includes memory elements incorporated with the C level networks.
3. Classification with Knowledge (CK)
This level is somewhat similar to the CM level, however rather than raw memory, the information that the C level network is able to access is a symbolic knowledge base.
4. Classification with Imperfect Knowledge (CIK)
At this level, we have a system that is built on top of CK, however is able to reason with imperfect information.
5. Collaborative Classification with Imperfect Knowledge (CCIK)
This level is very similar to the “theory of mind” where we actually have multiple agent neural networks combining to solve problems.
As we see from the above classification, the most advanced kind of Deep Learning system will involve multiple neural networks that either cooperate or compete to solve problems. The core problem of a multi-agent approach is how to control its behavior. In another story, I address this by proposing the the use of market driven mechanisms as a means of control (see: “Equilibrium Discovery in Modular Deep Learning”). It turns out that, DeepMind has been researching in this approach for a while. The DeepMind paper studies multi-agent systems from a similar economic perspective (i.e. incentive driven approach):
We can think of the trained AI agents as an approximation to economics’ rational agent model “homo economicus”. Hence, such models give us the unique ability to test policies and interventions into simulated systems of interacting agents — both human and artificial.
DeepMind researchers explored two games, “Gathering” and “Wolf Pack”. The agents would have to learn either a cooperative or competitive strategy. In the “Gathering” game, when scarcity was introduced into the environment, agents with complex strategies tended to pursue more aggressive competitive strategies. In the “Wolf Pack” game that was designed to encourage cooperative behavior, agents learning complex strategies did not necessarily led to greater cooperative behavior.
The primary value of the research is that it gives us an understanding of the many knobs (i.e. discount factor, batch size, network size) that can be tweaked to arrive at different network behaviors. The paper has a very interesting chart the maps out the agent’s behavior ( “Gathering” on the left and “Wolfpack” on the right ):
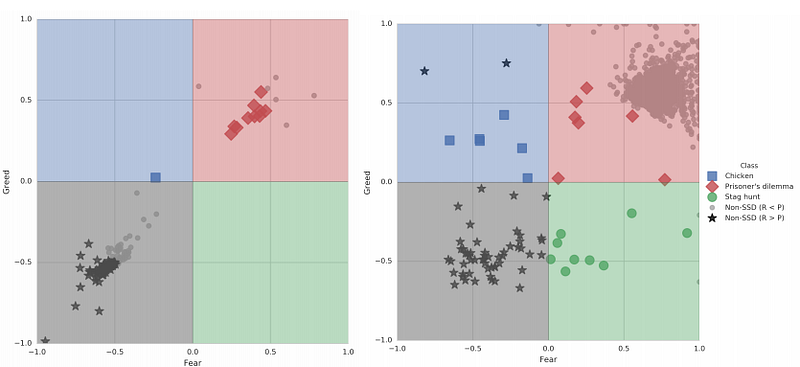
Very interesting that the axis are marked “Greed” and “Fear”, what better motivators are there anyway?
DeepMind isn’t alone in its research of Multi-agent systems and Deep Learning. Maluuba ( Recently acquired by Microsoft ) has also had active research. In a paper, published prior to acquisition, “ Improving Scalability of Reinforcement Learning by Separation of Concerns”:
We presented initial work on a framework for solving single-agent tasks using multiple agents. In our framework, different agents are concerned with different parts of the task. Our framework can be viewed as a generalization of the traditional hierarchical decomposition.
The graph below compares the “Separation of Concerns” (SOC) multi-agent approach versus a conventional approach:

The uniqueness of Maluuba’s approach is that the reward function of each agent depends not only on environmental state but also on the communication actions of the other agents. Depending on the composition of these agents, agents will have varying degrees of coupling, and thus independence. This coupling can vary dependent on the context and situation. So for example, in contexts with high environment reward an agent may act independently. While in contexts of low environment reward, an agent will act in more in relationship with other agents.
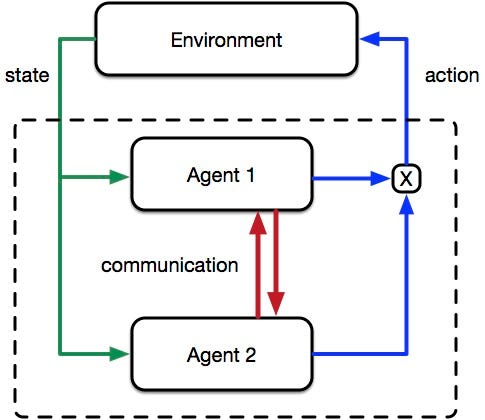
Coupling between agents and environment.
Maluuba’s research indicates a more hierarchical “command and control” coordination mechanism as opposed to a market driven distributed control. It is however, very likely that we shall see hybrid combinations of these coordination methods employed rather a “purist” approach to coordination.
In an even older research at FAIR (FaceBook AI Research), “Learning Multiagent Communication with Backpropagation” investigates an approach for cooperative behavior using backpropagation. The research shares commonalities with the Maluuba research in that the agents balance their behavior with the policy that is being learned and the communication between agents:

Credit: http://cims.nyu.edu/~sainbar/commnet/ The model consists of multiple agents and the communication between them is learned alongside their policy. We apply this model to a diverse set of tasks, demonstrating the ability of the agents to learn to communicate amongst themselves, yielding improved performance over non-communicative agents and baselines.
It is important to note that in all three research, cooperation or competitive strategies are learned by the Deep Learning agents. There are still many open question about this kind of research. The big take away though is that, this kind of work is performed by the giants of the field, DeepMind (Google), Maluuba (Microsoft) and FaceBook. It is an indicator as to where Deep Learning research is heading. I therefore hope this article has instilled enough “greed” or “fear” to motivate one to keep abreast of Game Theory developments and Deep Learning. More on the current state of Deep Learning can be found at: “Deep Learning Design Patterns” .
Bio: Carlos Perez is a software developer presently writing a book on "Design Patterns for Deep Learning". This is where he sources his ideas for his blog posts.
Original. Reposted with permission.
Related:
- Deep Learning, Artificial Intuition and the Quest for AGI
- Why Deep Learning is Radically Different From Machine Learning
- Game Theory Reveals the Future of Deep Learning