Exploratory Data Analysis in Python
We view EDA very much like a tree: there is a basic series of steps you perform every time you perform EDA (the main trunk of the tree) but at each step, observations will lead you down other avenues (branches) of exploration by raising questions you want to answer or hypotheses you want to test.
By Chloe Mawer & Jonathan Whitmore, Silicon Valley Data Science.
Earlier this year, we wrote about the value of exploratory data analysis and why you should care. In that post, we covered at a very high level what exploratory data analysis (EDA) is, and the reasons both the data scientist and business stakeholder should find it critical to the success of their analytical projects. However, that post may have left you wondering: How do I do EDA myself?
Last month, my fellow senior data scientist, Jonathan Whitmore, and I taught a tutorial at PyCon titled Exploratory Data Analysis in Python—you can watch it here. In this post, we will summarize the objectives and contents of the tutorial, and then provide instructions for following along so you can begin developing your own EDA skills.
Tutorial Objectives
Our objectives for this tutorial were to help those attending:
- Develop the EDA mindset by walking through a questions to ask yourself through the various stages of exploration and pointing out things to watch out for
- Learn how to invoke some basic EDA methods effectively, in order to understand datasets and prepare for more advanced analysis. These basic methods include:
- slicing and dicing
- calculating summary statistics
- basic plotting for numerical and categorical data
- basic visualization of geospatial data on maps
- using Jupyter Notebook widgets for interactive exploration
We view EDA very much like a tree: there is a basic series of steps you perform every time you perform EDA (the main trunk of the tree) but at each step, observations will lead you down other avenues (branches) of exploration by raising questions you want to answer or hypotheses you want to test.
Which branches you pursue will depend on what is interesting or pertinent to you. As such, the actual exploration you do while following along on this tutorial will be yours. We have no answers or set of conclusions we think you should come to about the datasets. Our goal is simply to aid in making your exploration as effective as possible, and to let you have the fun of choosing which branches to follow.
Tutorial Outline
The talk consists of the following:
- Introduction to exploratory data analysis: I summarize the motivation for EDA and our general strategy that we dive deeper into throughout the tutorial.
- Introduction to Jupyter Notebooks: our tutorial entails working through a series of Jupyter Notebooks and so Jonathan gives a quick introduction to using them for those who haven’t seen them before. We even learn a new trick from an attendee!
- Exploratory analysis of the Redcard dataset: Jonathan works through an exploratory analysis of a dataset that comes from a fascinating paper published with commentary in Nature. The core question of the paper is reflected in the title, “Many analysts, one dataset: Making transparent how variations in analytical choices affect results”. The authors recruited around 30 analytic teams who were each tasked with the same research question: “Are soccer referees more likely to give red cards to dark skin toned players than light skin toned players?” and given the same data. The dataset came from the players who played in the 2012–13 European football (soccer) professional leagues. Data about the players’ ages, heights, weights, position, skintone rating, and more were included. The results from the teams were then compared to see how the different ways of looking at the dataset yielded different statistical conclusions. The rich dataset provides ample opportunity to perform exploratory data analysis. From deciding hierarchical field positions, to quantiles in height or weight. We demonstrate several useful libraries including standard libraries like pandas, as well as lesser known libraries like
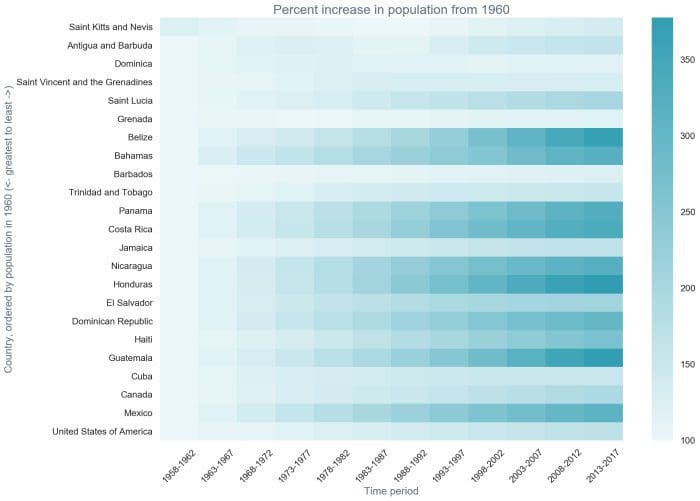
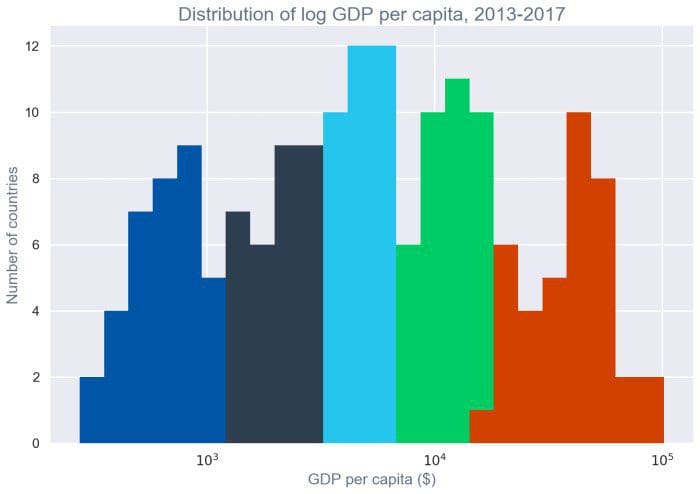
missingno,pandas-profiling, andpivottablejs. - Exploratory analysis of the AQUASTAT dataset: In this section, I work through exploration of the Food and Agriculture Organization (FAO) of the United Nation’s AQUASTAT dataset. This dataset provides metrics around water availability and water use, as well as other demographic data for each country, reported every five years since 1952. This dataset is often called panel or longitudinal data because it is data that is repeatedly collected for the same subjects (in this case, countries) over time. We discuss methods for exploring it as panel data, as well as methods focused on looking at only a cross-section of the data (data collected for a single time period across the countries). The data also is geospatial, as each observation corresponds to a geolocated area. We show how to look at very basic data on maps in Python, but geospatial analysis is a deep field and we scratch only the surface of it while looking at this dataset. We recommend the PySAL tutorial as an introduction to geospatial analysis in Python.
Following Along at Home
To get full value out of this tutorial, we recommend actually working through the Jupyter notebooks that we have developed. You can do this in one of two ways:
- In the cloud via Microsoft Azure notebooks: Set up an account and then clone this library. Cloning this library will allow you to open, edit, and run each Jupyter notebook online without having to worry about setting up Jupyter notebooks and a Python environment. This service is free and your notebooks can be saved for future use without any constraint. The only thing to know about this service is that while notebooks are persisted indefinitely, there is no saving of data or other non-notebook files after the working session. Data can be imported and then analyzed but any results outside of the notebook will have to be downloaded before leaving.
- Locally on your computer: Clone the github repo here and set up your Python environment according to the instructions found in the README.
Following along at home, you have the benefit of being able to put us on pause. We went through a lot of material in the three hours of the tutorial (and had to deal with some of the technical troubles inevitable during a hands-on tutorial of 65+ people using computers with different operating systems and various company firewalls!). To get full value out of the content, we suggest you pause throughout the tutorial when there are suggestions to try certain analyses yourself.
The possibilities for EDA are endless, even for a single dataset. You may want to look at the data in different ways and we welcome you to submit your own EDA notebooks for either or both of the datasets through a pull request in the github repo. We will provide feedback and approve PRs for your approaches to be shared with others developing their EDA skills.
Chloe Mawer comes from a background in geophysics and hydrology, and is well-versed in leveraging data to make predictions and provide valuable insights. Her experience in both academic research and engineering makes her capable of tackling novel problems and creating practical, effective solutions.
Jonathan Whitmore is a data scientist at SVDS. Following a postdoctoral position in astrophysics, Jonathan is a sought after speaker on computing and astronomy. He is excited by the application of machine learning and statistical techniques to industry problems and has developed novel data analysis techniques.
Original. Reposted with permission.
Related: