10 Python One-Liners for Scikit-learn
Stop writing extra code — these 10 one-liners will take care of 80% of your Scikit-Learn tasks!

Image by Author | Canva
I know that sometimes writing clean code can feel like a burden, but trust me, it's not only a good practice but also helps you understand your codebase better as it grows. Keep your code as simple and short as possible. It's not about aesthetics but about efficiency and clarity.
We will cover 10 Python one-liners that will handle most of your tasks in Scikit-Learn. If you’re not familiar, Scikit-Learn, aka sklearn, is a free and open-source machine learning library for Python that makes building ML models pretty simple. Its ease of use makes it a go-to choice for most developers.
Now, let’s take a look at these one-liners one by one. These snippets are perfect for:
- Quick experiments or benchmarks
- Simplifying repetitive tasks
- Prototyping before writing detailed code
1. Import Scikit-learn Modules in One Line
Before you do anything, you need to import the tools you’ll use. Why write separate imports when you can do them all at once?
from sklearn import datasets, model_selection, preprocessing, metrics, svm, decomposition, pipeline
This imports the most commonly used Scikit-learn modules in one go. It’s a clean and efficient way to set up your workspace.
2. Load the Iris Dataset
The Iris dataset is the “Hello World” of machine learning. With Scikit-learn, you can load it in one line:
X, y = datasets.load_iris(return_X_y=True)
This directly splits the dataset into features (X) and target labels (y), making it ready to use right away.
3. Split Data into Train and Test Sets
Splitting your data into training and testing sets is one of the first steps in any ML workflow. Here’s how you can do it in a single line:
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.2, random_state=42)
This creates an 80/20 split, with 80% of the data for training and 20% for testing. The random_state ensures that your results are consistent every time you run the code.
4. Standardize Features
Standardizing your features (mean = 0, std deviation = 1) is a must for many machine learning models, especially ones like SVM, PCA, or k-means. You can scale your data in one line:
X_train_scaled = preprocessing.StandardScaler().fit_transform(X_train)
This fits the scaler on the training data and transforms it simultaneously, making your model training more effective.
5. Reduce Dimensionality with PCA
If you have too many features, reducing the dimensionality with PCA can make your life easier. You can apply it in one line:
X_reduced = decomposition.PCA(n_components=2).fit_transform(X)
This one-liner reduces your feature space to 2 principal components, which is especially useful for visualization or reducing noise in your dataset.
6. Train an SVM Classifier
Training an SVM classifier is super straightforward with Scikit-learn:
svm_model = svm.SVC(kernel='linear', C=1.0, random_state=42).fit(X_train, y_train)
This one-liner creates an SVM with a linear kernel and trains it on the standardized training data. C is the regularization parameter (smaller values = smoother boundaries).
7. Generate a Confusion Matrix
A confusion matrix gives you a detailed breakdown of your classification results across all classes:
conf_matrix = metrics.confusion_matrix(y_test, svm_model.predict(X_test))
Output:
array([[10, 0, 0],
[ 0, 9, 0],
[ 0, 0, 11]])
This one-liner compares the test labels with the predicted labels and outputs a matrix showing true/false positives and negatives.
8. Perform Cross-Validation
Want to ensure your model performs well on unseen data? Use cross-validation:
cv_scores = model_selection.cross_val_score(svm_model, X, y, cv=5)
Output:
array([0.96666667, 1. , 0.96666667, 0.96666667, 1. ])
9. Print a Classification Report
A classification report gives detailed metrics like precision, recall, and F1-score for each class:
print(metrics.classification_report(y_test, svm_model.predict(X_test)))
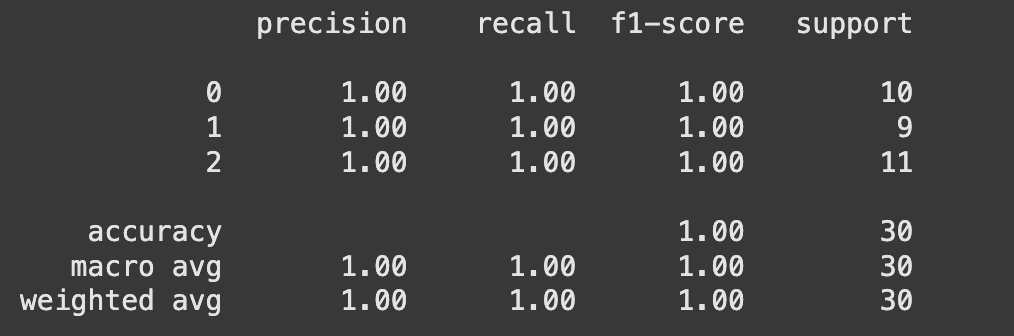
This one-liner prints everything you need to know about how well your model is performing for each class.
10. Create a Preprocessing and Model Pipeline
A pipeline makes your workflow cleaner by combining preprocessing and modeling into a single step:
pipeline_model = pipeline.Pipeline([('scaler', preprocessing.StandardScaler()), ('svm', svm.SVC())]).fit(X_train, y_train)
This one-liner builds a pipeline that standardizes the data and trains an SVM model in one shot.

While these one-liners won’t replace full workflows or detailed pipelines in production, they’ll help you experiment faster and write cleaner code. Here are some great resources for your reference:
- Scikit-learn Documentation: The official docs are packed with examples and explanations
- Kaggle’s Intro to Machine Learning: A beginner-friendly tutorial series
- Hands-On Machine Learning with Scikit-learn, Keras, and TensorFlow: A must-read book for anyone serious about ML
Try these snippets in your own projects. Let me know which one you liked the most, or share your favorite Scikit-learn one-liner!
Kanwal Mehreen is a machine learning engineer and a technical writer with a profound passion for data science and the intersection of AI with medicine. She co-authored the ebook "Maximizing Productivity with ChatGPT". As a Google Generation Scholar 2022 for APAC, she champions diversity and academic excellence. She's also recognized as a Teradata Diversity in Tech Scholar, Mitacs Globalink Research Scholar, and Harvard WeCode Scholar. Kanwal is an ardent advocate for change, having founded FEMCodes to empower women in STEM fields.