The Cardinal Sin of Data Mining and Data Science: Overfitting
Overfitting leads to public losing trust in research findings, many of which turn out to be false. We examine some famous examples, "the decline effect", Miss America age, and suggest approaches for avoiding overfitting.
By Gregory Piatetsky and Anmol Rajpurohit.

Many people were surprised by a recent study which overturned the conventional wisdom and said there was no link between eating saturated fat and heart disease. It seems that every week there are some new results, especially in medicine and social sciences, which invalidate the old results.
The phenomenon of old results no longer holding has been so widespread that some journalists started to call it the "cosmic habituation" or "the decline effect" - the bizarre theory that the laws of the universe seem to change when you try to repeat an experiment.
The explanation is much simpler.
Researchers too frequently commit the cardinal sin of Data Mining - Overfitting the data.
The researchers test too many hypotheses without proper statistical control, until they happen to find something interesting and report it. Not surprisingly, next time the effect, which was (at least partly) due to chance, will be much smaller or absent.
We note that Overfitting is not the same as another major data science mistake - "confusing correlation and causation". The difference is that overfitting finds something where there is nothing. In case of "correlation and causation", researchers can find a genuine novel correlation and only discover a cause much later (see a great example from astronomy in Kirk D. Borne interview on Big Data in Astrophysics and Correlation vs. Causality).
Every day we learn about new research through various sources and very often, we use these research findings to improve our understanding of the world and make better decisions. How would you feel if you were told that most of the published (and heavily marketed) research is biased, improperly planned, hastily executed, insufficiently tested and incompletely reported? That the results were interesting by design and not by nature?
The inherent flaws of prevalent research practices were very nicely identified and reported by John P. A. Ioannidis in his famous paper Why Most Published Research Findings Are False (PLoS Medicine, 2005). Deeply examining some of the most highly regarded research findings in medicine, Ioannidis concluded that very often either the results were exaggerated or the findings could not be replicated. In his paper, he presented statistical evidence that indeed most claimed research findings are false. Dr. Ioannidis now heads a new METRICS center at Stanford, where he continues to work on making sure that research is reproducible.
So, “bad” research is not new, but the amount of it increased with time. One of the very basic tests of how "scientific" a research is would be to observe its results when the same research is performed in multiple different environments (that are applicable) randomly chosen. Ioannidis noted that in order for a research finding to be reliable, it should have:
- Large sample size and with large effects
- Greater number of and lesser selection of tested relationship
- Greater flexibility in designs, definitions, outcomes, and analytical modes
- Minimal bias due to financial and other factors (including popularity of that scientific field)
Unfortunately, too often these rules were violated, producing irreproducible results.
To illustrate this, here some of the more entertaining "discoveries" that were reported using "overfitting the data" approach:
S&P 500 index is strongly related to Production of butter in Bangladesh (here is PDF)
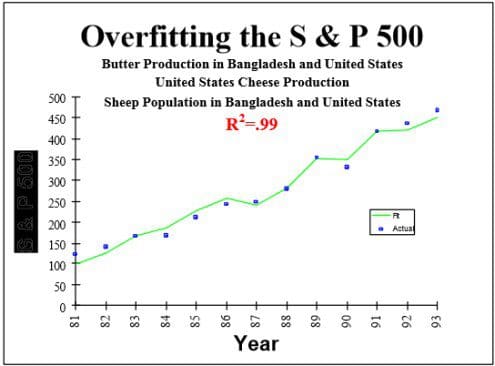
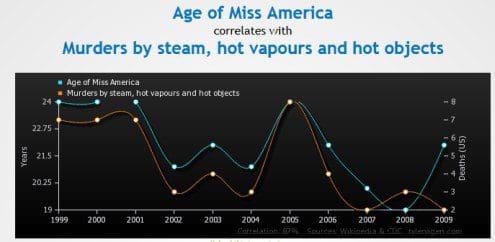
Age of Miss America is strongly related to Murders by steam, hot vapours and hot objects
… and many more interesting (and totally spurious) findings which you can discover yourself using tools such as Google correlate or the one by Tyler Vigen.
Human tendency for "magic thinking" tends to give such unusual findings much higher notoriety (Octopus Paul was world-famous for "predicting" World Cup results in 2010) and this does not increase the general public trust in science.
Several methods can be used to avoid "overfitting" the data
- Try to find the simplest possible hypothesis
- Regularization (adding a penalty for complexity)
- Randomization Testing (randomize the class variable, try your method on this data - if it find the same strong results, something is wrong)
- Nested cross-validation (do feature selection on one level, then run entire method in cross-validation on outer level)
- Adjusting the False Discovery Rate
See also two good posts by Dean Abbott, Why Overfitting is More Dangerous than Just Poor Accuracy [PART 1] and [Part 2], where he explains approaches on avoiding overfitting.
Good data science is on the leading edge of scientific understanding of the world, and it is data scientists responsibility to avoid overfitting data and educate the public and the media on the dangers of bad data analysis.
Related:
- Interview: Kirk Borne, Data Scientist, GMU on Big Data in Astrophysics and Correlation vs. Causality
- The First Law of Data Science: Do Umbrellas Cause Rain?
- Most scientific papers are probably wrong, says John Ioannidis
- Stupid Data Miner Tricks and Motley Fool
- Poll Results: Octopus wins World Cup Prediction Competition