Data Science Last Mile
This post discusses the Data Science "Last Mile", the final work to take the discovered insights and deliver them a highly usable format or integrate into a specific application.
By Joel Horwitz (Alpine Data Labs), June 2014.
Data Science is often referred to as a combination of developer, statistician, and business analyst. In more casual terminology, it can be more aptly described as hacking, domain knowledge, and advanced math. Drew Conway does a good job of describing the competencies in his blog post. Much of the recent attention is focused on the early stages of the process of establishing an analytics sandbox to extract data, format, analyze, and finally create insight (see figure 1 below).
Many of the advanced analytic vendors are focused on this workflow due to the historical context of how business intelligence has been conducted over the past 30 years. For example, a new comer to the space, Trifacta, recently announced a $25M venture round that is applying predictive analytics to the data to help improve the feature creation step. Its a very good area to focus considering some 80% of the work is spent here working to un-bias data, find the variables that really matter (signal / noise ratio), and identify the best model (Linear regression, Decision trees, Naive Bayes, etc.) to apply to the data. Unfortunately, most of the insights created often never make it past what I am calling the "Data Science Last Mile."
 Figure 1. Simple data science workflow.
Figure 1. Simple data science workflow.
What is the Data Science Last Mile? It’s the final work that is done to take found insight and deliver in a highly usable format or integrate into a specific application. There are many examples of this last mile and here are what I consider to be the top examples.
Example 1. Reports, Dashboards, and Presentations
Thanks to the business intelligence community, we are now accustomed to expect our insights in a dashboard format with charts and graphs piled on top of each other. Newer visual analytics tools like Tableau and Platfora add to the graphing melange by making it even easier to plot seemingly unrelated metrics against each other. Don't get me wrong, there will always be a place for dashboards.
At Intel, we had daily standup meetings at 7am where we reviewed key metrics and helped drive the priorities each day for the team. We had separate meetings scheduled on a project basis for analysis that was more complex like bringing up a new process or production tool. Here the visualization format is very well defined and there is even an industry standard called SPC or Statistic Process Control. For every business, there are standard charts for reporting metrics and outside of that there is a well defined methodology for plotting data.
One of my favorite books of all time on the best design practice for displaying data is by Edward Tufte. My former boss and mentor recommended the book The Visual Display of Quantitative Information and it changed my life. One of my favorite visuals from this book is how the French visualized their train time tables.
French Train schedule from 1880s, from Marlena Compton blog.
Presentations, reports, and dashboards is where data goes to die. It was common practice to review these charts on regular basis and apply the recommendation to the business, product, or operations on a quarterly or even annual basis.
Example 2. Models
Another way data science output is ingested by an organization is as inputs in a model. From my experience, this is predominantly done using Excel. Its quite surprising to me that there aren't many other applications that have been built to make this process easier? Perhaps its due to this knowledge being locked away in highly specialized analysts heads? Whatever the reason, this seems like a primary area for disruption that there is a significant need to standardize this process and de-silo this exercise. One of my favorite quotes is from a former colleague. We were working over a long weekend analyzing our new product strategy business models when he stated, "When they told me I'd be working on models, this is NOT what I had in mind." Whether you're in Operations, Finance, Sales, Marketing, Product, Customer Relations, Human Resources, the ability to accurately model your business means you're likely able to predict its success.
Example 3. Applications
Finally and quite possibly my favorite examples are those products built on data science around us without us evening knowing it. One of the oldest examples I can think of is the weather report. We are given a 7 day forecast in the form of sun, clouds, rain drops, and green screens managed by verbose interpretive dancers. As opposed to reporting the raw probability data of rain, barometric pressure, wind speeds, temperatures and many other factors that go into this prediction.
Another example is a derived index of credit worthiness (FICO), or the Stock Market index, or Google's Page Rank, or a likeliness to buy value, or a number of other singular values that are used to great effect. These indexes are not reported wholesale, although you can find them if you try. (For example, go to pagerank.chromefans.org/ to see Google Page Rank for any website). Instead, they are packaged into a usable format like Search, Product Recommendations, and many other productized formats that bridge the gap between habit and raw data. For me, this is the area that I am most focused on as the last mile of work that needs to be done to push data into the every aspect of our decision making process.
How does Big Data fit into this scenario? Big data is about improving accuracy with more data. It is well known that the best algorithm looses out to the more data inputs you have. However, conducting sophisticated statistics and analysis on large datasets is not a trivial task. A number of startups have sprung up in the last couple years to build frameworks around this, but require a significant amount of code skills. Only a few have provided a much more approachable way of applying data science to big data.
One such company that has built a visual and highly robust way of conducting analytics at scale is Alpine Data Labs. It has a bevy of native statistical models that you can mix and match to product highly sophisticated algorithms that rival the best in class in a matter of minutes, not months. Pretty wild to think that only a few years ago we were still hand tooling algorithms on a quarterly basis. Check it out for yourself by going to http://start.alpinenow.com to see how far we’ve come.
In summary, it is evident to me that the focus needs to shift back towards the application of data science before we find our self disillusioned. I for one, am already thinking about how to build new products that start with data as its core value than an add on to be determined later. There is much more to write about on this subject and would love to hear your thoughts.
Feel free to contact me on twitter @JSHorwitz
Related Posts:
Data Science is often referred to as a combination of developer, statistician, and business analyst. In more casual terminology, it can be more aptly described as hacking, domain knowledge, and advanced math. Drew Conway does a good job of describing the competencies in his blog post. Much of the recent attention is focused on the early stages of the process of establishing an analytics sandbox to extract data, format, analyze, and finally create insight (see figure 1 below).
Many of the advanced analytic vendors are focused on this workflow due to the historical context of how business intelligence has been conducted over the past 30 years. For example, a new comer to the space, Trifacta, recently announced a $25M venture round that is applying predictive analytics to the data to help improve the feature creation step. Its a very good area to focus considering some 80% of the work is spent here working to un-bias data, find the variables that really matter (signal / noise ratio), and identify the best model (Linear regression, Decision trees, Naive Bayes, etc.) to apply to the data. Unfortunately, most of the insights created often never make it past what I am calling the "Data Science Last Mile."
 Figure 1. Simple data science workflow.
Figure 1. Simple data science workflow.What is the Data Science Last Mile? It’s the final work that is done to take found insight and deliver in a highly usable format or integrate into a specific application. There are many examples of this last mile and here are what I consider to be the top examples.
Example 1. Reports, Dashboards, and Presentations
Thanks to the business intelligence community, we are now accustomed to expect our insights in a dashboard format with charts and graphs piled on top of each other. Newer visual analytics tools like Tableau and Platfora add to the graphing melange by making it even easier to plot seemingly unrelated metrics against each other. Don't get me wrong, there will always be a place for dashboards.
As a rule of thumb, metrics should only be reported as frequently as is the ability to take action on them.
At Intel, we had daily standup meetings at 7am where we reviewed key metrics and helped drive the priorities each day for the team. We had separate meetings scheduled on a project basis for analysis that was more complex like bringing up a new process or production tool. Here the visualization format is very well defined and there is even an industry standard called SPC or Statistic Process Control. For every business, there are standard charts for reporting metrics and outside of that there is a well defined methodology for plotting data.
One of my favorite books of all time on the best design practice for displaying data is by Edward Tufte. My former boss and mentor recommended the book The Visual Display of Quantitative Information and it changed my life. One of my favorite visuals from this book is how the French visualized their train time tables.
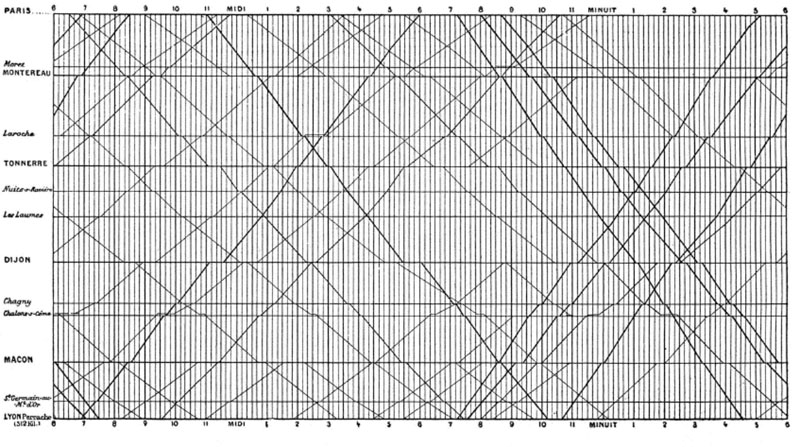
French Train schedule from 1880s, from Marlena Compton blog.
Presentations, reports, and dashboards is where data goes to die. It was common practice to review these charts on regular basis and apply the recommendation to the business, product, or operations on a quarterly or even annual basis.
Example 2. Models
Another way data science output is ingested by an organization is as inputs in a model. From my experience, this is predominantly done using Excel. Its quite surprising to me that there aren't many other applications that have been built to make this process easier? Perhaps its due to this knowledge being locked away in highly specialized analysts heads? Whatever the reason, this seems like a primary area for disruption that there is a significant need to standardize this process and de-silo this exercise. One of my favorite quotes is from a former colleague. We were working over a long weekend analyzing our new product strategy business models when he stated, "When they told me I'd be working on models, this is NOT what I had in mind." Whether you're in Operations, Finance, Sales, Marketing, Product, Customer Relations, Human Resources, the ability to accurately model your business means you're likely able to predict its success.
Example 3. Applications
Finally and quite possibly my favorite examples are those products built on data science around us without us evening knowing it. One of the oldest examples I can think of is the weather report. We are given a 7 day forecast in the form of sun, clouds, rain drops, and green screens managed by verbose interpretive dancers. As opposed to reporting the raw probability data of rain, barometric pressure, wind speeds, temperatures and many other factors that go into this prediction.
Another example is a derived index of credit worthiness (FICO), or the Stock Market index, or Google's Page Rank, or a likeliness to buy value, or a number of other singular values that are used to great effect. These indexes are not reported wholesale, although you can find them if you try. (For example, go to pagerank.chromefans.org/ to see Google Page Rank for any website). Instead, they are packaged into a usable format like Search, Product Recommendations, and many other productized formats that bridge the gap between habit and raw data. For me, this is the area that I am most focused on as the last mile of work that needs to be done to push data into the every aspect of our decision making process.
How does Big Data fit into this scenario? Big data is about improving accuracy with more data. It is well known that the best algorithm looses out to the more data inputs you have. However, conducting sophisticated statistics and analysis on large datasets is not a trivial task. A number of startups have sprung up in the last couple years to build frameworks around this, but require a significant amount of code skills. Only a few have provided a much more approachable way of applying data science to big data.
One such company that has built a visual and highly robust way of conducting analytics at scale is Alpine Data Labs. It has a bevy of native statistical models that you can mix and match to product highly sophisticated algorithms that rival the best in class in a matter of minutes, not months. Pretty wild to think that only a few years ago we were still hand tooling algorithms on a quarterly basis. Check it out for yourself by going to http://start.alpinenow.com to see how far we’ve come.
In summary, it is evident to me that the focus needs to shift back towards the application of data science before we find our self disillusioned. I for one, am already thinking about how to build new products that start with data as its core value than an add on to be determined later. There is much more to write about on this subject and would love to hear your thoughts.
Feel free to contact me on twitter @JSHorwitz
Related Posts: