Deep Learning Transcends the Bag of Words
Generative RNNs are now widely popular, many modeling text at the character level and typically using unsupervised approach. Here we show how to generate contextually relevant sentences and explain recent work that does it successfully.
Deep learning has risen to prominence, both delighting and enraging computer scientists, following a number of breakthrough results on difficult classification tasks. Convolutional neural networks demonstrate an unprecedented ability to recognize objects in images. A variety of neural networks have similarly revolutionized the field of speech recognition. In machine learning parlance, these models are typically discriminative. That is, they directly model a relationship between some input data, like images, and corresponding labels, like "dog" or "cat". Given data, they produce classifications. But we also want computers to do more: to form sentences, to paint pictures, to craft curriculums for students and to devise treatments for the ill. In machine learning parlance, we want generative models.
Over the past several months, several clever approaches repurposing supervised discriminative deep learning models for data generation have swept the web. Among them is a technique pioneered by Ilya Sutskever for generating text with Recurrent Neural Networks (RNNs) using only characters. In this approach, generating text is posed as a prediction problem. At training time you learn a model which gives high probability to each observed character conditioned on all preceding characters in the string. Then, at prediction time, you produce text by sampling from these probabilities repeatedly. Each time, you pass the sampled character to the model as the next input. This method recently found a massive audience when popularized in a tutorial by Andrej Karpathy, who modified the approach to use LSTM RNNs. The tutorial demonstrates that character-level RNNs can churn out passages that uncannily resemble Shakespeare, and C-code that uncannily resembles Linux source.

What's the Point?
From a perspective of an AI dreamer, this work is obviously exciting. By modeling text at the character level, we impart strictly less prior knowledge onto the model than when we work with words. These models require little if any preprocessing, offering the possibility that they could shine even more in domains where prior knowledge is scantly available. Character based RNNs are notable for their generality, in contrast to most NLP models: a single network could just as easily generate C-code, guitar tablature, English prose, or Chinese characters. Further, these networks demonstrate that RNNs can simultaneously model sequential relationships at many different time scales. They learn to form words, to form sentences, and to form paragraphs, without explicitly modeling them as separate tasks.
In contrast, to train a word-level model, you must first settle on a vocabulary size. Then you must decide upon a convention to handle words that don't reside in your vocabulary. Such models lack an elegant way to handle misspellings, jargon, or concept drift. Further, for a word-based generative RNN, the size of the output layer scales with the size of the vocabulary. Because back-propagating through a softmax layer is computationally expensive, training a translation model at with 60,000 output words requires 4 GPUS dedicated to the task. Then there is a the added complication of handling concept drift. As new words are created the model can't simply learn, it requires an entirely new architecture.
On the other hand, until recently, character level RNNs have worked in an unsupervised fashion. From a practical perspective, when would you want to generate a passage that approximates a selection of Shakespeare selected at random? When would you want unusable source code that superficially resembled the coding style of the Linux community? To make this tech useful, we want to generate contextually appropriate text on command. A teacherbot should generate the right text to explain the answer to a math problem. A recommender system should generate the right text to describe the salient aspects of a product.
Conditional Character-Level Generative RNNs
Thus to make useful generative text models, we want to generate text conditionally. This has been done successfully with word level models by many researchers, including the aforementioned Sutskever and Karpathy (for language translation and image captioning respectively) among others. These models typically follow an encoder-decoder approach. Some conditioned-upon data (say an image) is first encoded by the encoder model. This representation is then passed as the initial state to a decoder RNN, which then functions precisely as a standard generative RNN. One weakness of this approach is that it is limited in the length of the sequences it can decode, as the signal must survive from the very first state of the encoder RNN until the final token in the generated text. Thus it has been much more amenable for training word-level models than for character level models.
Capturing Meaning in Product Reviews with Character-Level Generative Text Models
In a collaboration with Sharad Vikram and Julian McAuley at UCSD, I recently posted a manuscript addressing the issue of generating long-form text conditionally at the character level. Specifically, we use a dataset of reviews scraped from the website BeerAdvocate.com, containing over 1.5 million reviews. Each review is annotated with star ratings as well as product ID and category information. As an exploratory task, we generate reviews, conditioned upon a star rating and category. In other words, our model can, on command, generate a 5 star review for a stout, or a 1 star review of an lager. In ongoing work, we increase the complexity of the conditioned upon information, generating reviews given a user and item. We want to compose a review the user would most likely leave for a given beer, even if the user has never tried the beer before.
In the paper, we show that a simple replication and concatenation strategy can be used to fuse the conditioned upon information (ratings and product categories) with the sequential input (characters in the review). We call this approach a generative concatenative network (GCN). This model can generate product reviews, learning not only to form words from scratch, but to use the correct words to describe each category of item and to reflect the designated star rating. The model can generate reviews spanning hundreds of characters, without "forgetting" the input signal. We also exploit, via Bayes' rule, the equivalence between the conditional generation and predicting the auxiliary information, showing that our generative can be run 'in reverse' as a classifier, nearly matching the performance of a state of the art tf-idf n-gram model. The same model can both generate convincing reviews and successfully classify reviews by category and rating. In a sense, we can jointly learn both to speak, and to comprehend. Eventually related models could serve as powerful primitives for building dialog systems.
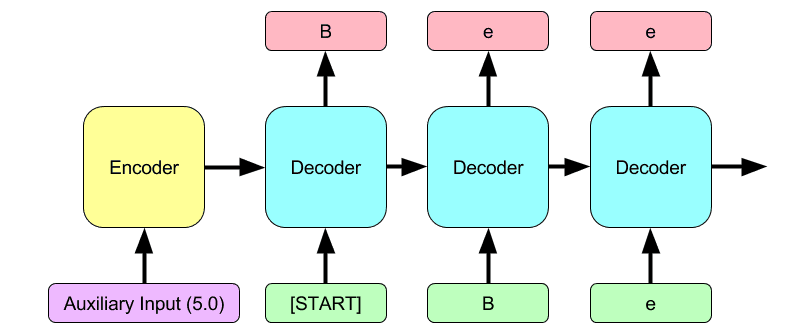
Because the model operates at the character level, it learns to be robust to misspellings, and to capture the non-linear effects of negation on sentiment (depending on the modified adjective). The model also learns both to generate and correctly classify strings containing slang and proper nouns. In addition to the listing the paper on the arXiv, we also produced an online demonstration for conditionally generating reviews. . The following figure depicts the way auxiliary data (in this case, a 5-star rating) is fed to the network.
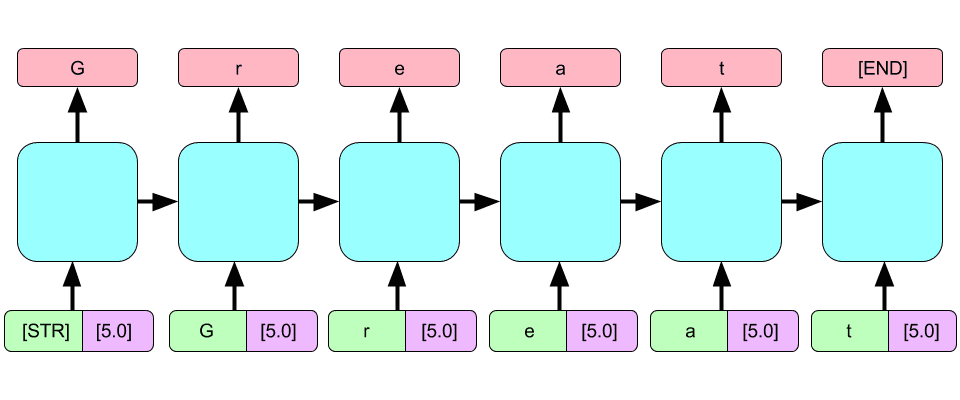
Example of review:
The following review was generated on a generative concatenative net conditioned to produce a 1-star review for a lager:
On tap in a pint glass at the brewery to me. A- This was a bit of a pale gold color. Nothing worth mentioning. I could tell what I was supposed to drink. S: skunky and skunky. T - It tastes like a soda water with a little bit of corn and bad chardonnay. I thought it was a tad better than this normally beer that was better than the smell would have been better. No real hop flavor. An astringent finish. Mouthfeel is light bodied with a slick finish. This is probably the worst beer I've ever had. I won't be having another bottle at a time but if it was the only beer I was skunked, I'd say it was a little better in the bottle.
 On tap in a pint glass at the brewery to me. A- This was a bit of a pale gold color. Nothing worth mentioning. I could tell what I was supposed to drink. S: skunky and skunky. T - It tastes like a soda water with a little bit of corn and bad chardonnay. I thought it was a tad better than this normally beer that was better than the smell would have been better. No real hop flavor. An astringent finish. Mouthfeel is light bodied with a slick finish. This is probably the worst beer I've ever had. I won't be having another bottle at a time but if it was the only beer I was skunked, I'd say it was a little better in the bottle.
On tap in a pint glass at the brewery to me. A- This was a bit of a pale gold color. Nothing worth mentioning. I could tell what I was supposed to drink. S: skunky and skunky. T - It tastes like a soda water with a little bit of corn and bad chardonnay. I thought it was a tad better than this normally beer that was better than the smell would have been better. No real hop flavor. An astringent finish. Mouthfeel is light bodied with a slick finish. This is probably the worst beer I've ever had. I won't be having another bottle at a time but if it was the only beer I was skunked, I'd say it was a little better in the bottle.Beer Category Classification
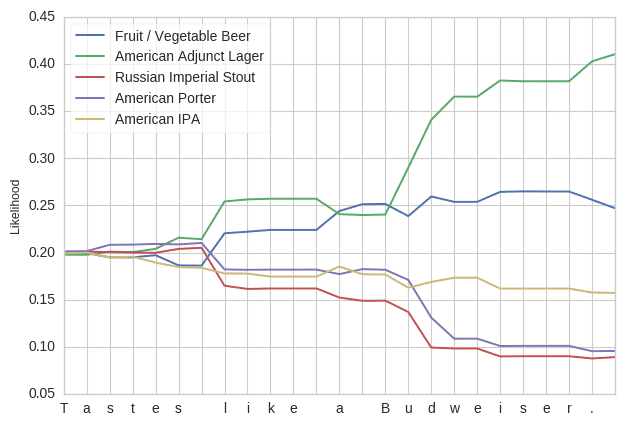
In addition, the model can categorize reviews based on the beer category on a character by character basis. For example, it learns by the 'u' in Budweiser that the review is describing a lager.
Character-Based Neural Machine Translation
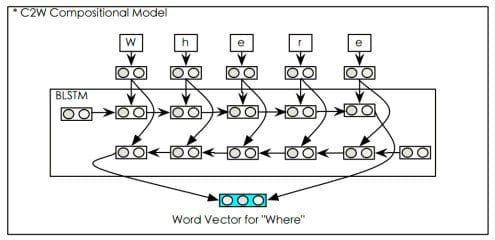
We're not alone in chasing the possibilities for generating text conditionally at the character level. One interesting paper by Wang Ling, Isabel Trancoso et al., also submitted to the International Conference on Learning Representations, introduces an approach for performing machine translation at the character level. This model keeps much of the machinery of a word level model, basing its approach on an attention-based translation model pioneered by Bahdanau et al. However, unlike previous models, which rely a lookup table of word embeddings, this model learns to compose a representation of words as a function of its characters. Thus, while the model makes mild assumptions about whitespace and punctuation, it makes no assumptions about the input our output vocabulary. Accordingly, it could conceivably learn both to process words it has never seen and generate words it has never seen, and does not suffer a memory or computational requirements that explicitly depend on the vocabulary size.
Other Work with Character-Level and Generative Nets
Our work and the exciting work by Ling and Trancoso are but two representatives of a growing trend both towards conditional character based text generation and, more generally, towards exploring the generative capabilities of deep learning models. While this post focuses on character level generative models, it's warrants mentioning Google's Inceptionism (Deep Dreams), which generates images to visualize what each feature detector in a convolutional neural network is "looking for". These models repurpose convolutional neural nets, which are traditionally discriminative models, to generate images. Also of interest are recent papers on generative adversarial learning, which learn to generate images such that they fool a discriminative model trained to distinguish between real and fabricated images.References
- Generating Text with Recurrent Neural Networks
- Sequence to Sequence Learning with Neural Networks
- Capturing Meaning in Product Reviews with Character Level Text Models
- BeerMind Demo
- Character Based Neural Machine Translation
- Google Deep Dreams
 Zachary Chase Lipton is a PhD student in the Computer Science Engineering department at the University of California, San Diego. Funded by the Division of Biomedical Informatics, he is interested in both theoretical foundations and applications of machine learning. In addition to his work at UCSD, he has interned at Microsoft Research Labs and as a Machine Learning Scientist at Amazon, is a Contributing Editor at KDnuggets, and has signed on as an author at Manning Publications.
Zachary Chase Lipton is a PhD student in the Computer Science Engineering department at the University of California, San Diego. Funded by the Division of Biomedical Informatics, he is interested in both theoretical foundations and applications of machine learning. In addition to his work at UCSD, he has interned at Microsoft Research Labs and as a Machine Learning Scientist at Amazon, is a Contributing Editor at KDnuggets, and has signed on as an author at Manning Publications.
Related:
- Does Deep Learning Come from the Devil?
- MetaMind Competes with IBM Watson Analytics and Microsoft Azure Machine Learning
- Deep Learning and the Triumph of Empiricism
- The Myth of Model Interpretability
- (Deep Learning’s Deep Flaws)’s Deep Flaws
- Data Science’s Most Used, Confused, and Abused Jargon